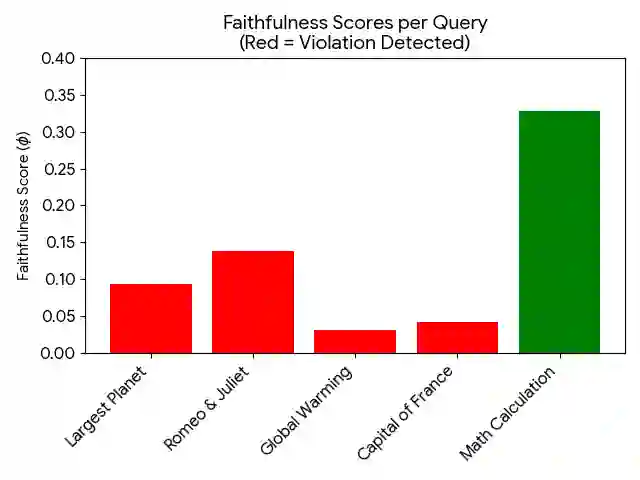
As Large Language Model (LLM) agents are increasingly tasked with high-stakes autonomous decision-making, the transparency of their reasoning processes has become a critical safety concern. While \textit{Chain-of-Thought} (CoT) prompting allows agents to generate human-readable reasoning traces, it remains unclear whether these traces are \textbf{faithful} generative drivers of the model's output or merely \textbf{post-hoc rationalizations}. We introduce \textbf{Project Ariadne}, a novel XAI framework that utilizes Structural Causal Models (SCMs) and counterfactual logic to audit the causal integrity of agentic reasoning. Unlike existing interpretability methods that rely on surface-level textual similarity, Project Ariadne performs \textbf{hard interventions} ($do$-calculus) on intermediate reasoning nodes -- systematically inverting logic, negating premises, and reversing factual claims -- to measure the \textbf{Causal Sensitivity} ($φ$) of the terminal answer. Our empirical evaluation of state-of-the-art models reveals a persistent \textit{Faithfulness Gap}. We define and detect a widespread failure mode termed \textbf{Causal Decoupling}, where agents exhibit a violation density ($ρ$) of up to $0.77$ in factual and scientific domains. In these instances, agents arrive at identical conclusions despite contradictory internal logic, proving that their reasoning traces function as "Reasoning Theater" while decision-making is governed by latent parametric priors. Our findings suggest that current agentic architectures are inherently prone to unfaithful explanation, and we propose the Ariadne Score as a new benchmark for aligning stated logic with model action.
翻译:随着大型语言模型(LLM)智能体越来越多地承担高风险自主决策任务,其推理过程的透明度已成为关键的安全问题。尽管\textit{思维链}(CoT)提示使智能体能够生成人类可读的推理轨迹,但这些轨迹究竟是模型输出的\textbf{忠实}生成驱动因素,还是仅仅为\textbf{事后合理化}解释,目前尚不明确。我们提出\textbf{项目Ariadne},一种新颖的可解释人工智能(XAI)框架,该框架利用结构因果模型(SCMs)和反事实逻辑来审计智能体推理的因果完整性。与现有依赖表层文本相似度的可解释性方法不同,项目Ariadne对中间推理节点执行\textbf{硬干预}($do$-演算)——系统地反转逻辑、否定前提并逆转事实主张——以测量最终答案的\textbf{因果敏感性}($φ$)。我们对最先进模型的实证评估揭示了一个持续存在的\textit{忠实度鸿沟}。我们定义并检测到一种普遍存在的故障模式,称为\textbf{因果解耦},其中智能体在事实和科学领域表现出高达$0.77$的违规密度($ρ$)。在这些案例中,尽管内部逻辑矛盾,智能体却得出相同的结论,证明其推理轨迹仅充当“推理剧场”,而决策过程实则由潜在的参数先验所支配。我们的研究结果表明,当前的智能体架构本质上容易产生不忠实的解释,为此我们提出将Ariadne分数作为一项新的基准,用于评估陈述逻辑与模型行为的一致性。