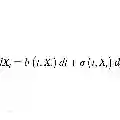Recent reinforcement learning has enhanced the flow matching models on human preference alignment. While stochastic sampling enables the exploration of denoising directions, existing methods which optimize over multiple denoising steps suffer from sparse and ambiguous reward signals. We observe that the high entropy steps enable more efficient and effective exploration while the low entropy steps result in undistinguished roll-outs. To this end, we propose E-GRPO, an entropy aware Group Relative Policy Optimization to increase the entropy of SDE sampling steps. Since the integration of stochastic differential equations suffer from ambiguous reward signals due to stochasticity from multiple steps, we specifically merge consecutive low entropy steps to formulate one high entropy step for SDE sampling, while applying ODE sampling on other steps. Building upon this, we introduce multi-step group normalized advantage, which computes group-relative advantages within samples sharing the same consolidated SDE denoising step. Experimental results on different reward settings have demonstrated the effectiveness of our methods.
翻译:近期强化学习技术已提升了流匹配模型在人类偏好对齐方面的性能。尽管随机采样能够探索去噪方向,但现有在多个去噪步上进行优化的方法仍受限于稀疏且模糊的奖励信号。我们观察到,高熵步可实现更高效、更有效的探索,而低熵步则导致难以区分的轨迹输出。为此,我们提出E-GRPO——一种熵感知的组相对策略优化方法,旨在提升随机微分方程采样步的熵值。由于随机微分方程的积分过程因多步随机性而面临奖励信号模糊的问题,我们特别将连续的低熵步合并为一个高熵步用于随机微分方程采样,同时在其他步上应用常微分方程采样。在此基础上,我们引入了多步组归一化优势函数,该函数在共享同一合并随机微分方程去噪步的样本组内计算组相对优势。在不同奖励设置下的实验结果验证了我们方法的有效性。