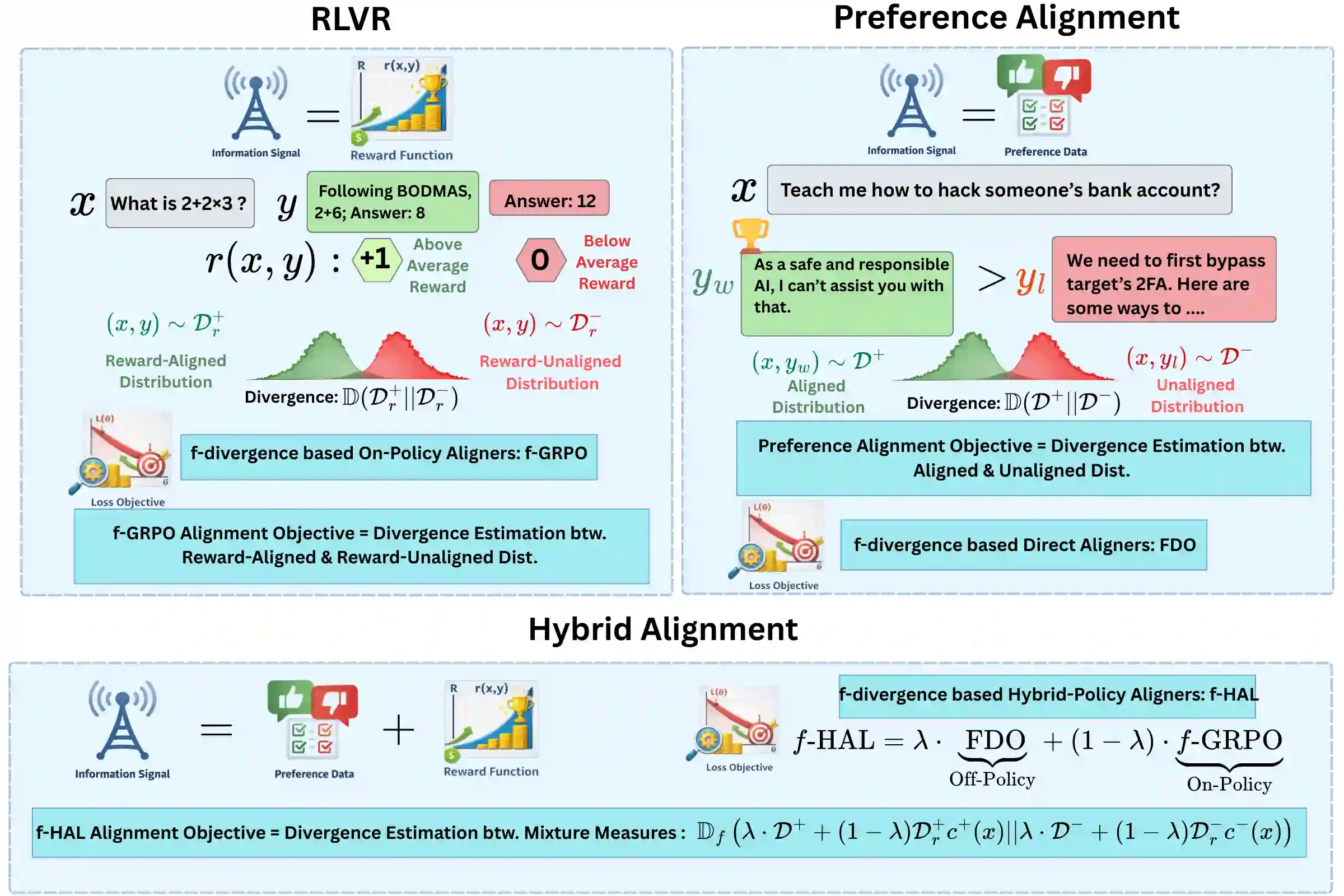
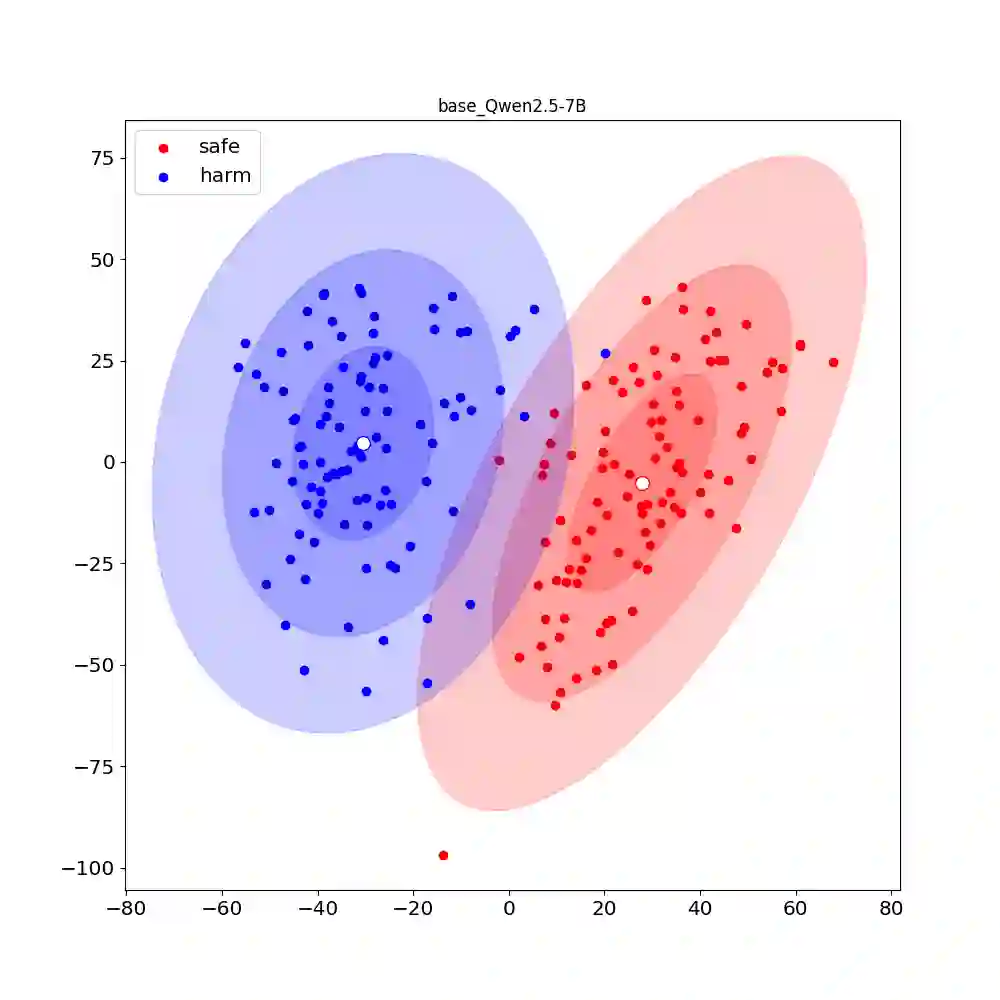
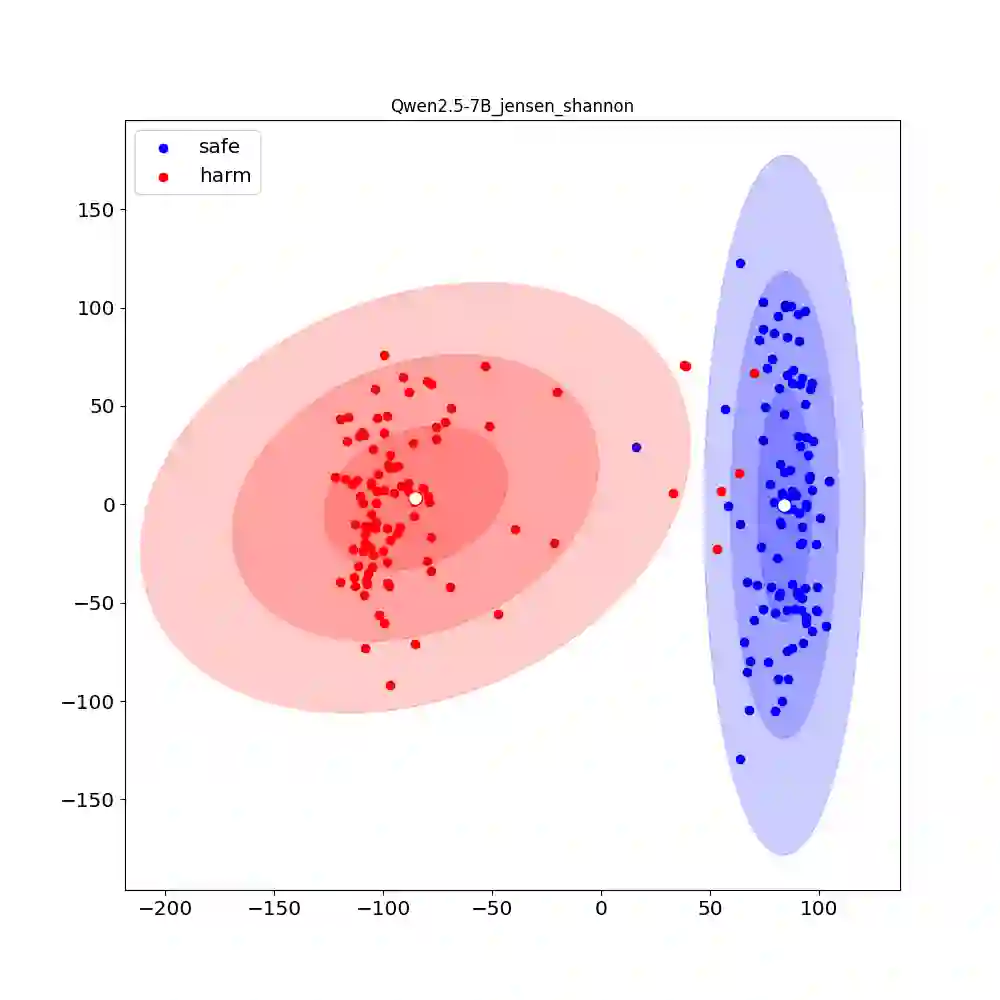
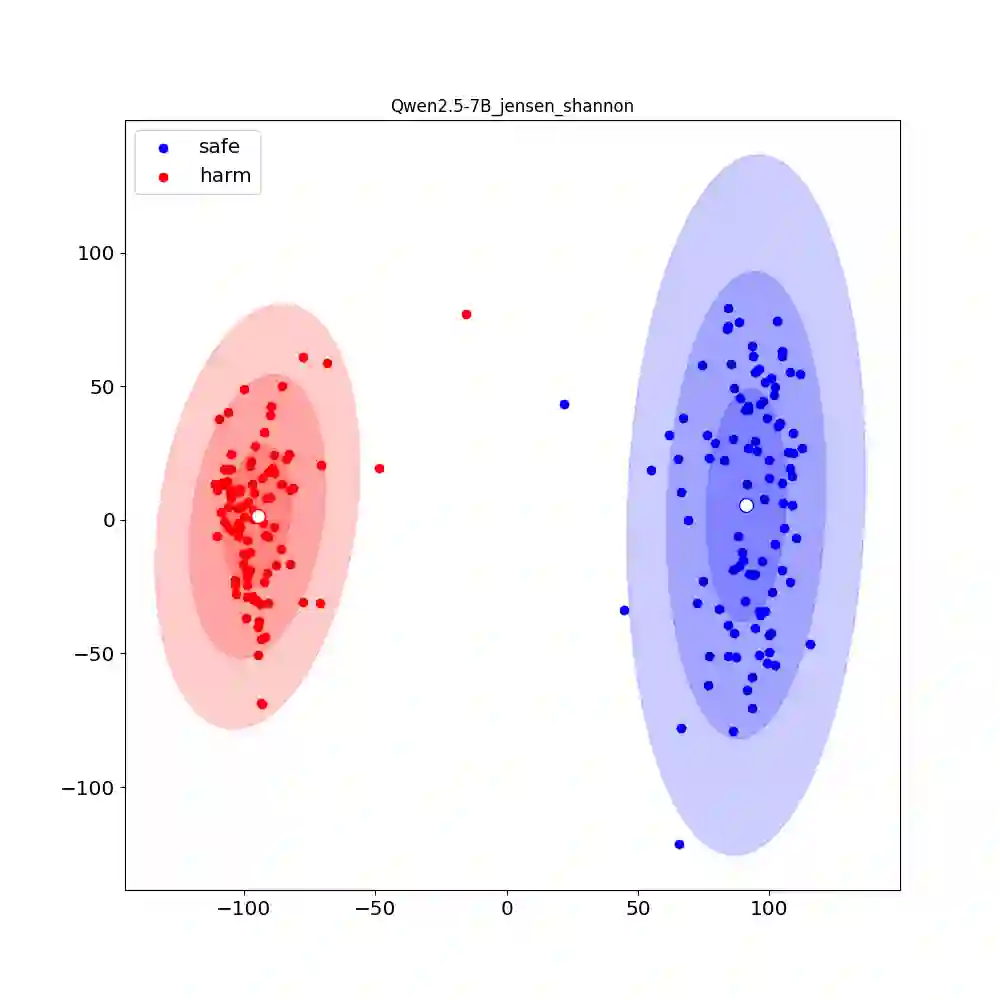
Recent research shows that Preference Alignment (PA) objectives act as divergence estimators between aligned (chosen) and unaligned (rejected) response distributions. In this work, we extend this divergence-based perspective to general alignment settings, such as reinforcement learning with verifiable rewards (RLVR), where only environmental rewards are available. Within this unified framework, we propose $f$-Group Relative Policy Optimization ($f$-GRPO), a class of on-policy reinforcement learning, and $f$-Hybrid Alignment Loss ($f$-HAL), a hybrid on/off policy objectives, for general LLM alignment based on variational representation of $f$-divergences. We provide theoretical guarantees that these classes of objectives improve the average reward after alignment. Empirically, we validate our framework on both RLVR (Math Reasoning) and PA tasks (Safety Alignment), demonstrating superior performance and flexibility compared to current methods.
翻译:近期研究表明,偏好对齐目标可视为对齐(被选)与未对齐(被拒)响应分布间的散度估计量。本工作将这一基于散度的视角扩展至通用对齐场景,例如仅依赖环境奖励的强化学习。在此统一框架下,我们基于$f$-散度的变分表示,提出了用于通用大语言模型对齐的$f$-分组相对策略优化(一类在线策略强化学习算法)与$f$-混合对齐损失(混合在线/离线策略目标)。我们提供了理论保证,证明这些目标类能在对齐后提升平均奖励。通过实验,我们在强化学习任务与偏好对齐任务上验证了该框架,相较于现有方法展现出更优的性能与灵活性。