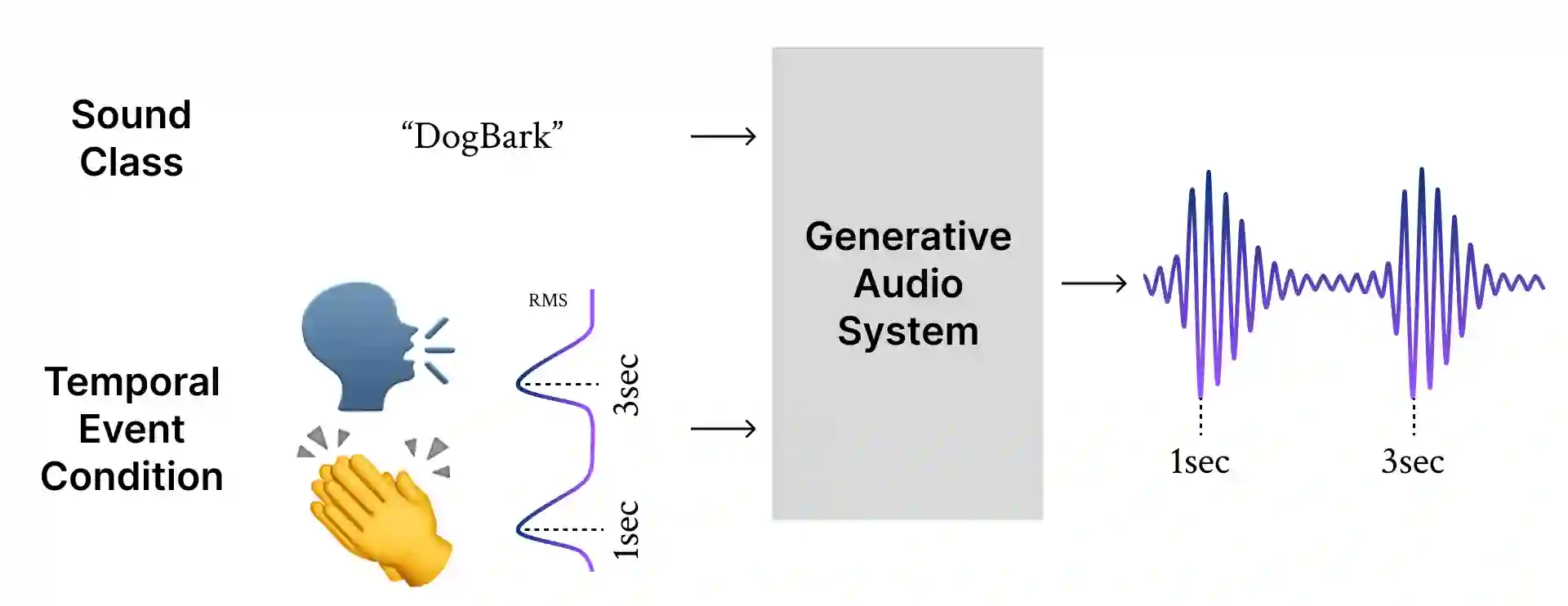
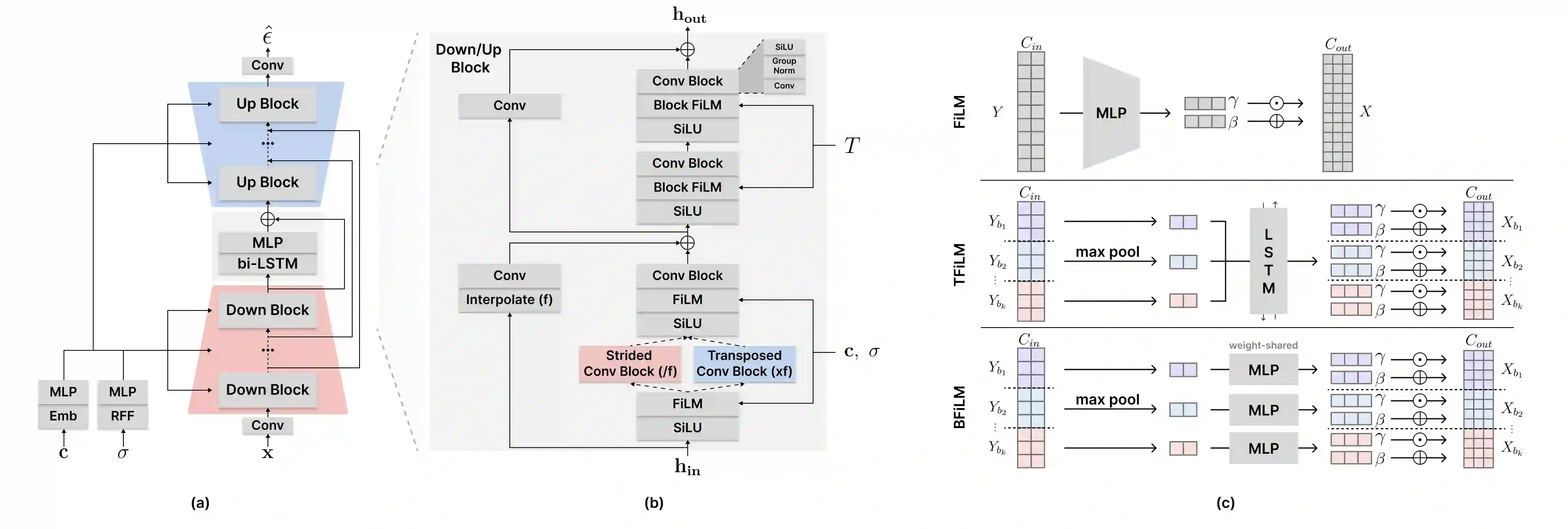
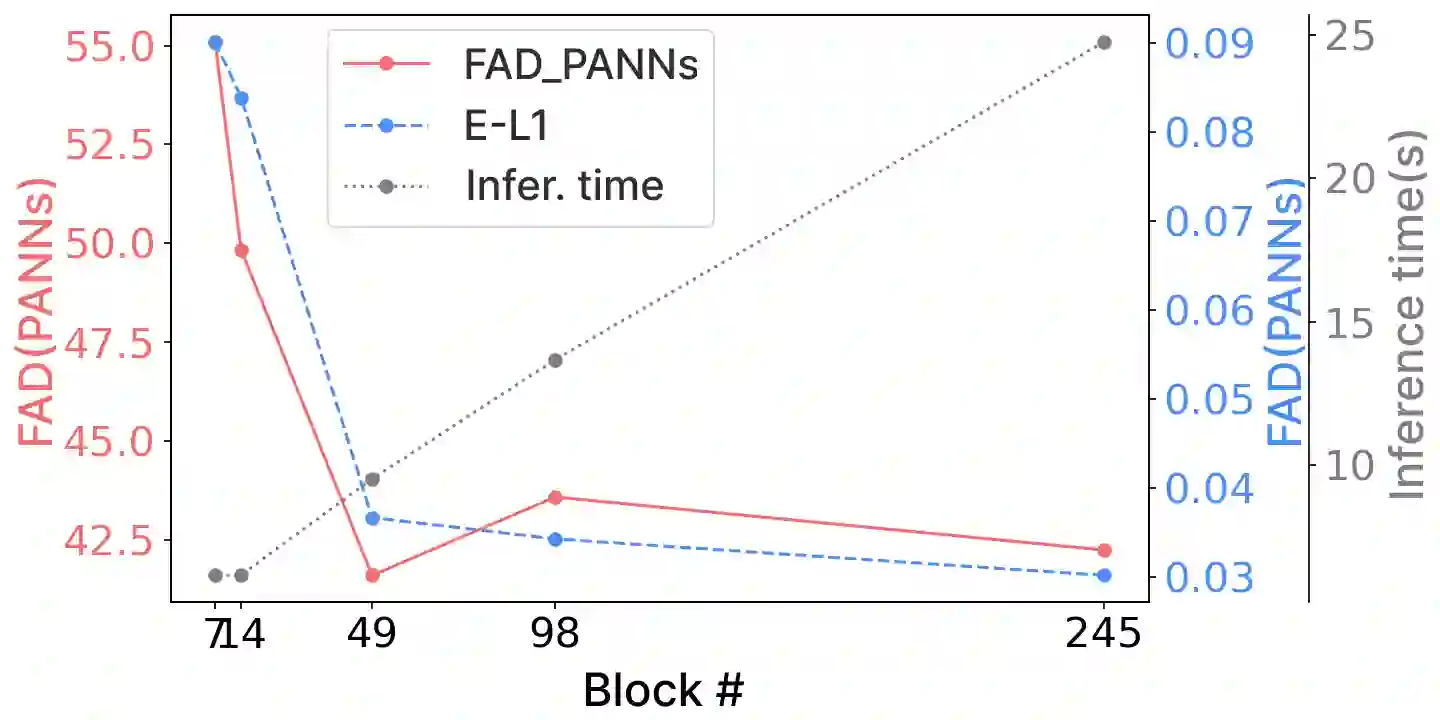
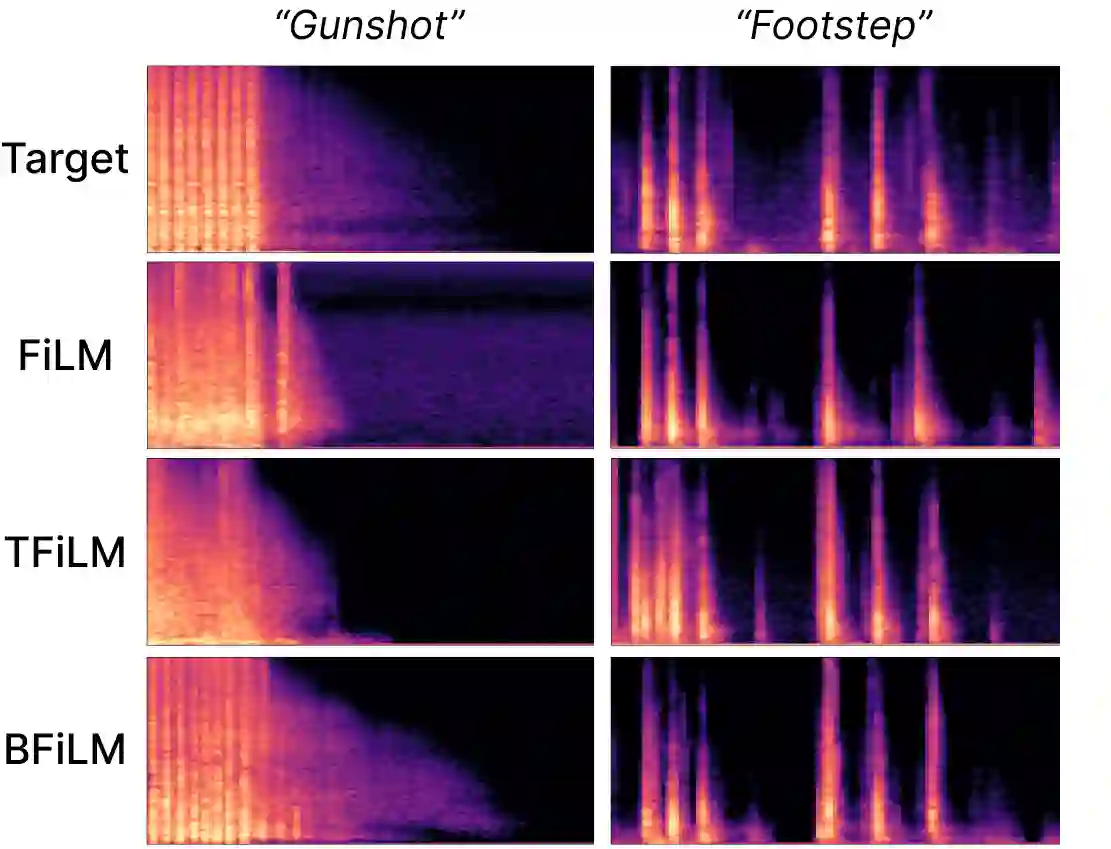
Foley sound, audio content inserted synchronously with videos, plays a critical role in the user experience of multimedia content. Recently, there has been active research in Foley sound synthesis, leveraging the advancements in deep generative models. However, such works mainly focus on replicating a single sound class or a textual sound description, neglecting temporal information, which is crucial in the practical applications of Foley sound. We present T-Foley, a Temporal-event-guided waveform generation model for Foley sound synthesis. T-Foley generates high-quality audio using two conditions: the sound class and temporal event feature. For temporal conditioning, we devise a temporal event feature and a novel conditioning technique named Block-FiLM. T-Foley achieves superior performance in both objective and subjective evaluation metrics and generates Foley sound well-synchronized with the temporal events. Additionally, we showcase T-Foley's practical applications, particularly in scenarios involving vocal mimicry for temporal event control. We show the demo on our companion website.
翻译:拟声音效(Foley sound)是与视频同步插入的音频内容,在多媒体内容的用户体验中起着关键作用。近年来,借助深度生成模型的进展,拟声音效合成领域涌现出活跃研究。然而,此类工作主要聚焦于复制单一声音类别或文本声音描述,忽视了在拟声音效实际应用中至关重要的时序信息。我们提出T-Foley——一种面向拟声音效合成的时序事件引导波形生成模型。T-Foley通过两种条件生成高质量音频:声音类别与时序事件特征。针对时序条件,我们设计了一种时序事件特征及名为Block-FiLM的新型条件处理技术。T-Foley在客观与主观评估指标上均取得卓越性能,并能生成与时序事件高度同步的拟声音效。此外,我们展示了T-Foley的实际应用,特别涉及利用人声模仿进行时序事件控制的场景。演示内容详见我们的配套网站。