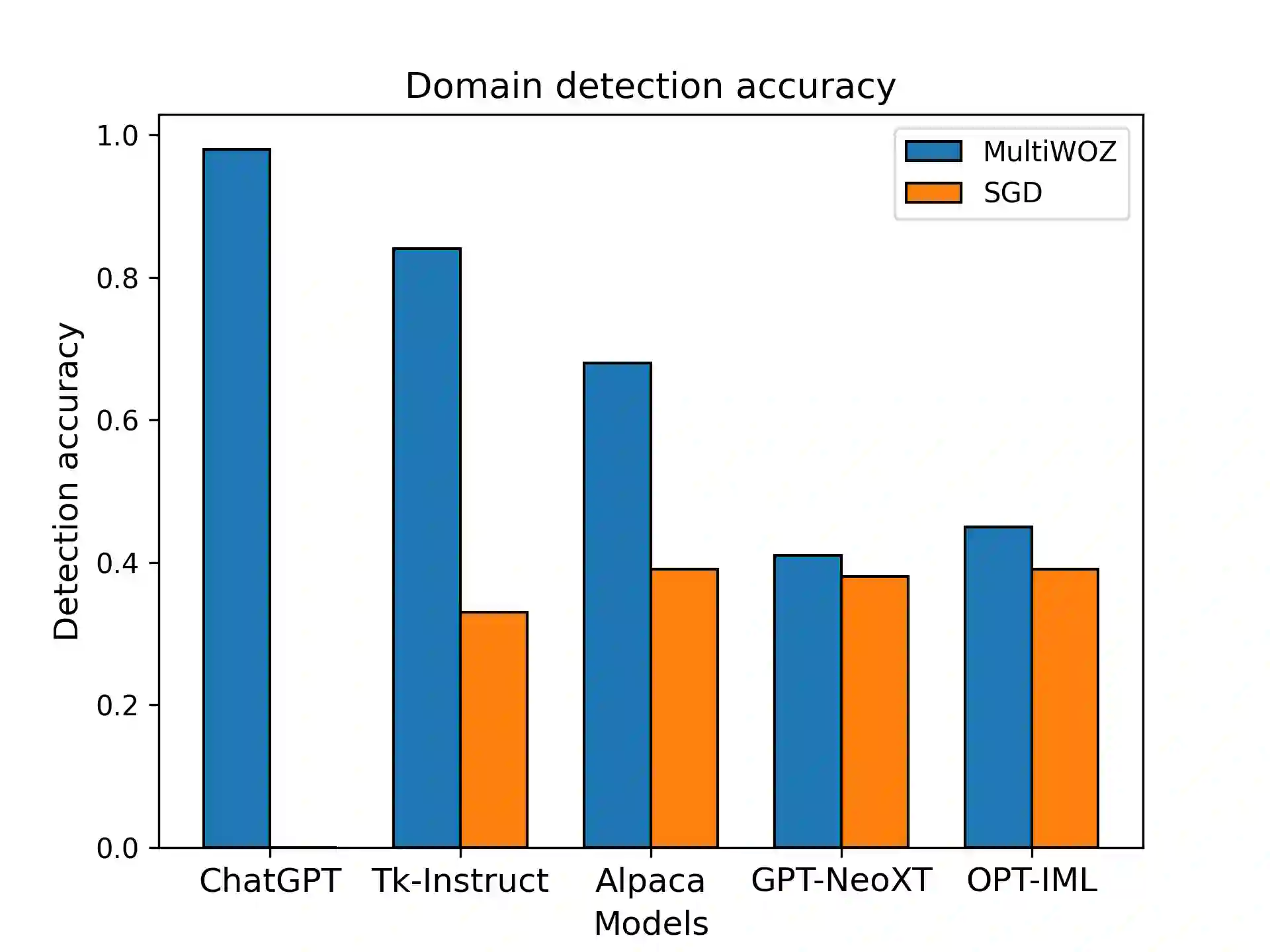
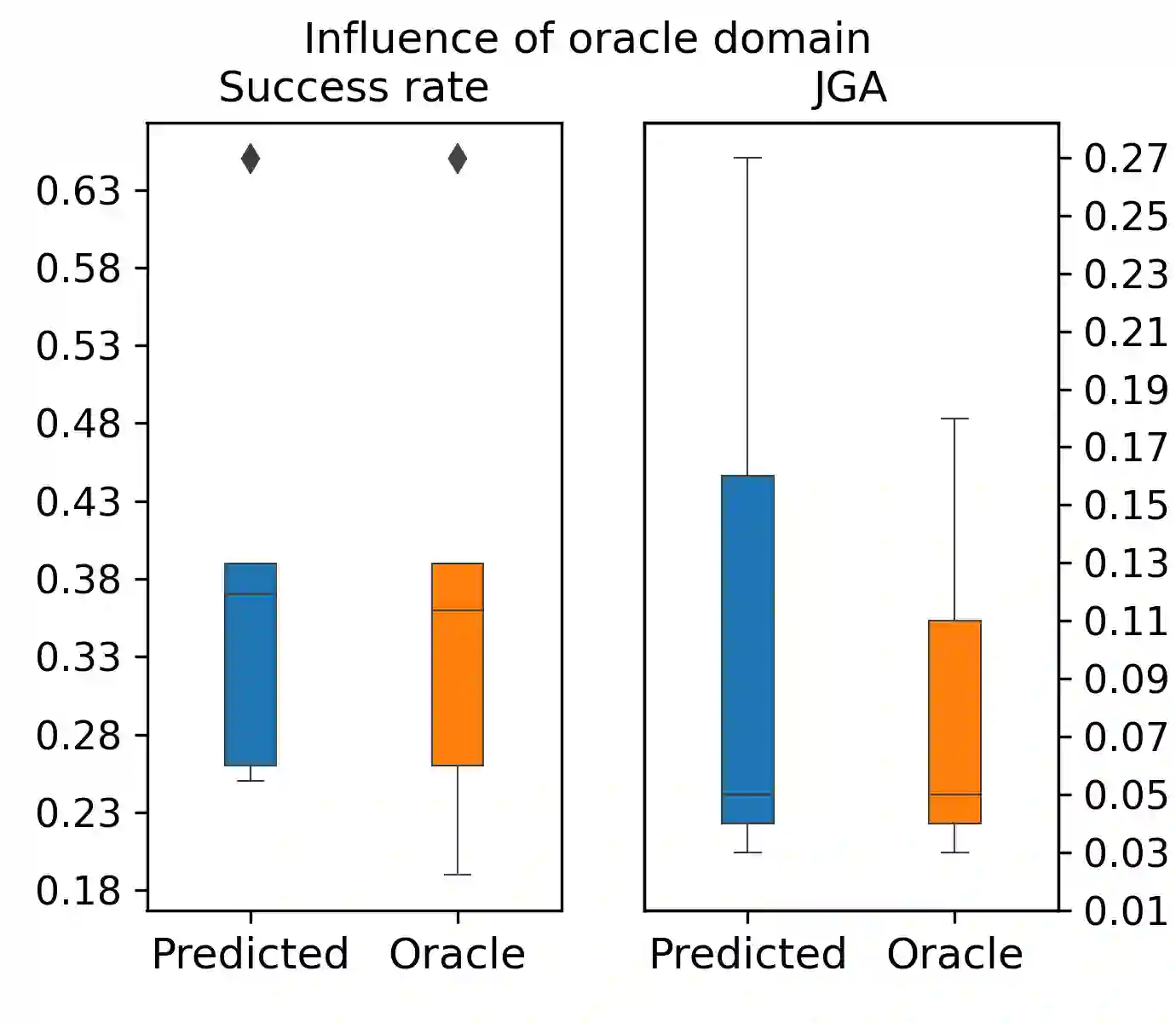
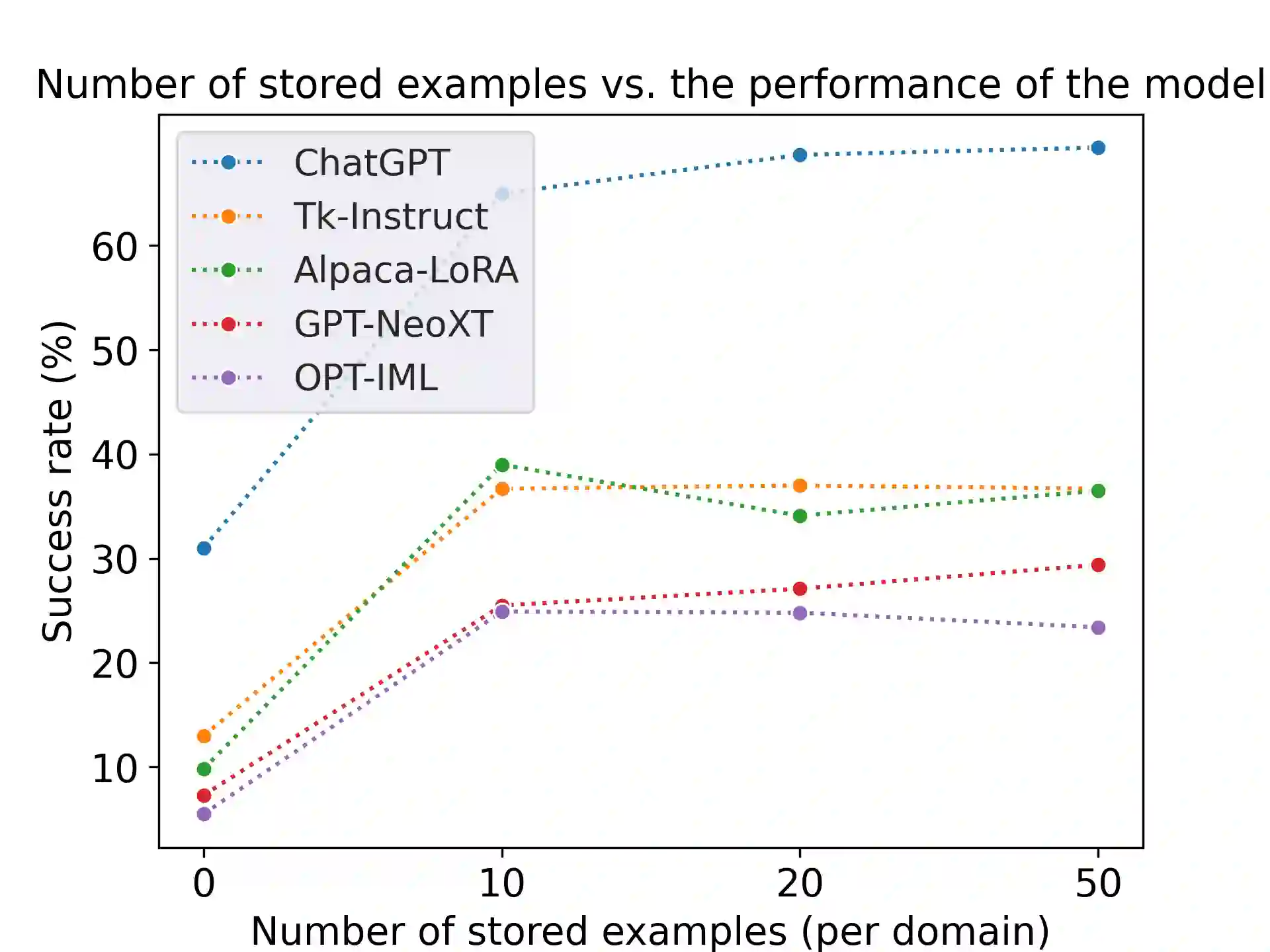
Instructions-tuned Large Language Models (LLMs) gained recently huge popularity thanks to their ability to interact with users through conversation. In this work we aim to evaluate their ability to complete multi-turn tasks and interact with external databases in the context of established task-oriented dialogue benchmarks. We show that for explicit belief state tracking, LLMs underperform compared to specialized task-specific models. Nevertheless, they show ability to guide the dialogue to successful ending if given correct slot values. Furthermore this ability improves with access to true belief state distribution or in-domain examples.
翻译:指令微调的大型语言模型(LLMs)近期因通过对话与用户交互的能力而备受关注。本研究旨在评估其在既定任务导向型对话基准场景中完成多轮任务及与外部数据库交互的能力。我们发现,在显式信念状态追踪任务中,LLMs 的表现逊于专门的任务特定模型。然而,若获得正确的槽值,LLMs 仍能引导对话走向成功结局。此外,这种能力在获取真实信念状态分布或领域内示例时会进一步提升。