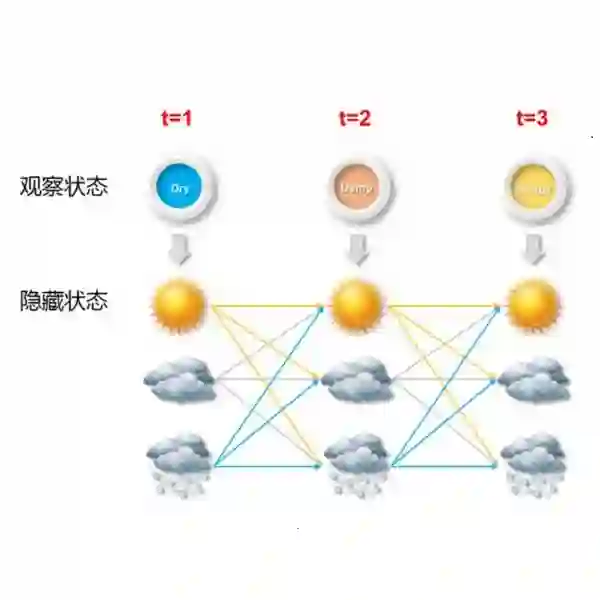
In routine care, individuals identified a priori as high-risk are usually tested for conditions more frequently. Protected attributes, such as sex or ethnicity may also determine testing frequency. Such heterogeneous detection rates across a population induce label error. This causes systematic model error for specific groups and biases performance metrics during validation. This paper proposes a method to correct for such bias in prediction models due to differential diagnostic delay. We use a causal inference framework to define our target estimand: an individual's diagnosis probability in a counterfactual scenario where their diagnosis rate matches that of a reference group. We model the longitudinal process as a hidden Markov model, in which confirmatory test results are emissions from a latent progressive disease stage. We validate our approach in simulated data and apply it to a case study of chronic kidney disease prediction using electronic health records. In simulations, our method reduces prediction bias and improves calibration-in-the-large, correcting the Observed:Expected ratio in the underdiagnosed group from 1.34 (standard deviation: 0.09) in a model developed without any correction for underdiagnosis bias to 1.02 (0.09). Violations of assumptions in the simulation affected the estimation of model parameters, but the proposed approach nonetheless remained better calibrated than the standard model. In the clinical case study, we identify diabetes as the main driver of observability, with an odds ratio of 10.36 (95% confidence interval, 9.80 - 11.02) in 6-month urine albumin-creatinine ratio testing rate. Using our approach to predict the counterfactual diagnostic rate in patients without diabetes, we improved the Observed:Expected ratio of a developed clinical prediction model from 1.55 (1.51 - 1.59) to 1.01 (0.98 - 1.04).
翻译:在常规临床诊疗中,被事先认定为高风险人群的个体通常会接受更频繁的疾病检测。性别或种族等受保护属性也可能决定检测频率。这种人群间异质性的检出率会导致标签误差,进而引发特定群体的系统性模型误差,并在验证过程中造成性能指标偏倚。本文提出一种方法,用于校正因诊断延迟差异导致的预测模型偏倚。我们采用因果推断框架定义目标估计量:在个体诊断率与参照组匹配的反事实情境下,其疾病诊断概率。我们将纵向过程建模为隐马尔可夫模型,其中确诊检验结果被视为潜在进展性疾病阶段的状态发射值。我们在模拟数据中验证了该方法,并将其应用于基于电子健康记录的慢性肾病预测案例研究。模拟结果显示,该方法降低了预测偏倚,改善了整体校准度,将低诊断组的观察/预期比值从未进行欠诊断偏倚校正模型的1.34(标准差:0.09)校正至1.02(0.09)。模拟中违反模型假设会影响参数估计,但所提方法仍比标准模型保持更优的校准度。在临床案例研究中,我们发现糖尿病是诊断可见性的主要驱动因素,其6个月尿白蛋白肌酐比检测率的比值比为10.36(95%置信区间:9.80-11.02)。通过使用该方法预测非糖尿病患者的反事实诊断率,我们将临床预测模型的观察/预期比值从1.55(1.51-1.59)改善至1.01(0.98-1.04)。