
原创作者:黎酝,顾宇轩
指导老师:冯骁骋
原创指导:顾宇轩 转载须标注出处:哈工大SCIR
1. 大模型错因诊断分析背景
近年来,以大规模预训练为基础的语言模型迅速发展[1-4] 。借助海量语料[5] 、自注意力架构[6-8] 以及参数规模的指数增长[9-10] ,这类模型在对话交互[11] 、代码生成[12] 、思维推理[13] 等诸多任务中取得了突破性进展。尽管如此,大模型在实际应用中仍面临多种结构性挑战。首先,幻觉[14] 是其最为突出的失效模式之一,即模型尽管输出流畅,但在事实正确性或任务忠实性上存在严重偏差。大模型的幻觉问题已经呈系统化、大规模化特征。其次,在指令理解或任务执行环节[15-16] ,模型常出现误解用户意图、忽略任务边界或者泛化错误任务等的现象,使得其输出偏离用户指令预期的操作规范。再者,在多轮对话或长上下文交互中[17] ,模型有时会迷失在对话上下文中,发生记忆丢失、话题漂移、自相矛盾或逻辑断裂的情况。更重要的是,模型内部机制大多仍为黑箱,导致我们无法直观判断其为什么出现错误、在哪里出错,从而严重制约了在高风险场景(如医疗、金融、政务等)中的可信部署[18-21] 。总体来看,尽管大模型技术日益成熟,但其可靠性、可解释性和安全性尚未同步提升,亟需系统化的研究以识别、定位与缓解其失效原因[22] 。针对上述挑战,现有研究逐渐认识到,仅仅衡量模型整体性能,如问题回答的准确率等指标,已不足以满足深入理解与应用保障的需求[23-26] 。相反,错因诊断与错因分析已成为新的研究范式。这类研究涵盖行为层面的测试,例如能力列表检测[27-29] 、探针分析[30-32] 、校准置信度[33-35] )、机制层面的可解释性工具(如激活补丁[36-37] 和表示归因[38-39] )以及检索增强中的知识源头归因[40] 等。如图 1所示,这一系列工作的核心目标是从模型出现错误这一黑盒现象,提升至模型为何出错、出错在哪一环、甚至如何修复这一可操作层面。进行此类错因诊断的研究具有多重意义:从理论层面而言,它能推动我们理解大模型从数据、表示、推理、解码、工具链等多层结构中的内在故障机制;从方法层面而言,它为构建从检测到定位再到修复的闭环提供了路径,从而使得模型的迭代不仅是经验驱动的,而更具系统性;从应用层面而言,它是构建可信、可审计、可治理的大模型系统的前提条件,尤其在高风险场景中,必须能够追踪模型失效的级别、来源与责任。换言之,错因诊断与分析的研究使大模型技术从表现优异走向行为可控、机制可解释、结果可审查的更高层级。
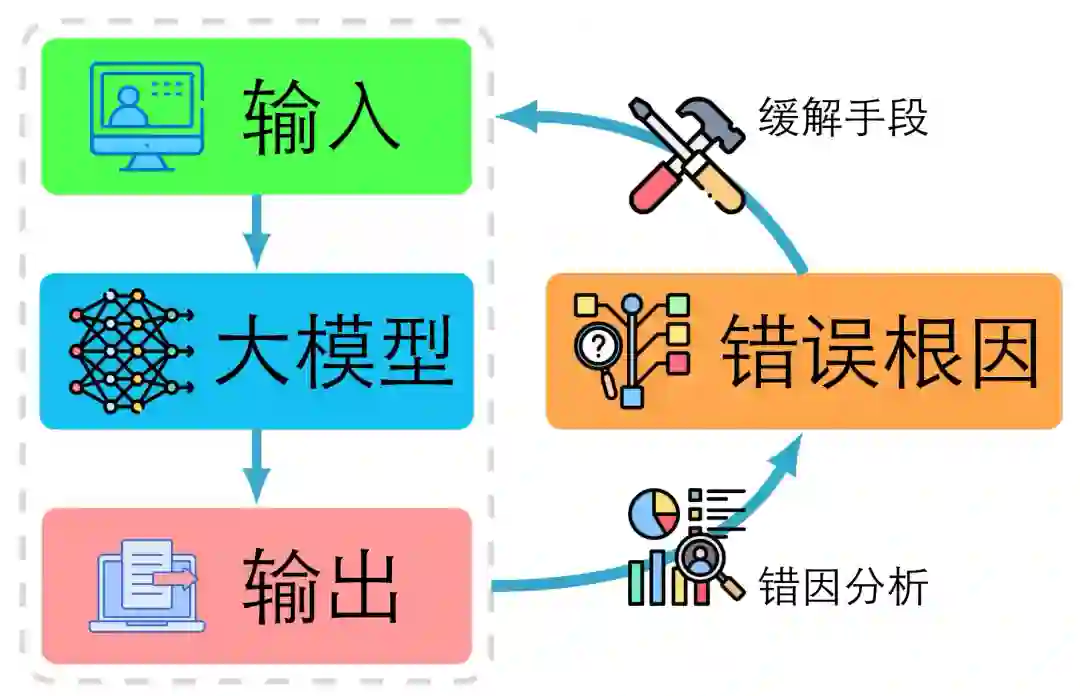
图1:错因分析总览 基于上述背景,我们提出对大模型错因与诊断方法进行体系化的调研与总结,旨在将目前散落于不同任务、不同模型、不同研究范式中的大模型出错诊断技术与错因溯源分析加以结构化、分类化与整合。我们主张构建一个涵盖数据与知识分布、表示机制、推理过程、不确定性、上下文利用、检索增强、指令理解等多个维度的错误诊断与错因分析框架。这样做具有重要意义:首先,它为研究者提供了系统化视角,能将行为级现象与模型底层机制映射起来,从而提升对大模型出错原因的理论理解;其次,它为工程实践提供了可操作的诊断指南,研究者或开发者可据此选择针对性的诊断策略、对模型进行定量评估、并制定修复流程;最后,通过建立共有的分类范式与基准流程,有望促进跨模型、跨任务、跨团队的比较研究与结果复现,进而推动大模型生态向可解释与可信的方向演进。总而言之,我们希望构建体系化的总结而不是简单的整理,将错因诊断从孤立案例提升为共建公共知识库和规范分析决策流程,从而加速大模型从黑箱困境向工程可管信任系统的转型。
2 错误类型
随着大语言模型在自然语言理解和生成任务中展现出前所未有的能力,其输出的质量和可靠性成为学术界和工业界高度关注的问题。然而,由于模型的训练数据、生成策略以及内部机制的限制,其输出并非总是准确、可靠或符合预期。为了科学评估模型性能、指导模型优化和保障应用安全,有必要对大语言模型的错误进行明确的定义和系统分析。大语言模型错误是指模型在生成文本过程中,其输出内容与人类期望、任务要求或客观标准之间存在显著偏差,导致信息不准确、不可靠或不符合预期。这种偏差不仅包括事实错误,还涵盖了模型在理解指令、逻辑推理、文本连贯性及有效性等方面的缺陷。具体而言,错误可能表现为事实性错误,即模型输出与客观事实、数据或可验证信息不一致,包括虚构、错误或不精确的陈述;遵循性错误,即模型未能正确理解或执行用户指令,导致输出与任务要求、格式规范或安全约束不符;推理性错误,即模型在逻辑推理、数学计算、因果分析或归纳演绎过程中出现错误,从而导致结论不成立或不合理;连贯性错误,即文本在结构、语义流或话题衔接上不自然、混乱或跳跃,影响阅读理解和信息传递;以及有效性错误,即模型生成的内容在形式上可能看似合理,但在实质上缺乏可操作性或完整性。大语言模型错误具有几个核心特征。首先,它是可验证的,可以通过客观标准或规则进行判断,而不仅仅是风格或偏好差异。其次,它体现为模型输出与期望的偏离,这种偏离既可以是客观偏离,如事实错误或逻辑冲突,也可以是主观偏离,如未完全执行任务指令或格式要求。第三,这类错误具有可归类性,可以系统地进行分类和标注,从而形成标准化的分析体系。最后,大语言模型错误直接影响输出信息的可靠性和可用性,对用户体验、任务完成以及应用安全均具有潜在风险。需要说明的是,并非所有生成文本的偏差都具有相同的严重性,但风格差异、措辞选择、表达流畅度以及信息覆盖不完整都可视为大语言模型输出偏差的一部分,属于广义的错误范畴。例如,输出未完全覆盖关键信息、缺少必要步骤或细节,虽然核心任务部分完成,但仍会导致任务不可完全执行,这类情况应判定为有效性错误;类似地,措辞不当、表达不流畅或结构组织欠佳,也可能降低信息传递的准确性和可理解性,应视为连贯性或呈现性错误。换言之,错误的定义不再局限于事实性或逻辑性偏差,而应涵盖所有影响模型输出可靠性、可操作性与可理解性的偏差类型,从而形成更加全面的分析标准。对大语言模型错误进行明确定义的意义在于,它为模型性能评估与改进提供了可操作的理论基础。一方面,错误定义能够帮助研究者识别模型在不同层面的系统性缺陷,从而针对性地设计诊断与修复机制;另一方面,明确的错误标准也为模型安全与可信性治理提供依据,使模型输出能够在事实正确性、逻辑一致性与语义可控性之间实现平衡。通过对错误的识别、解释与控制,可以推动大语言模型从语言流畅向语义可靠的方向演进,为其在教育、医疗、法律、科研等高价值领域的应用奠定安全与可信的基础。 为系统性刻画大语言模型在实际应用中可能出现的问题,我们构建了一套涵盖多维度的大模型错误分类体系。从事实性、遵循性、推理性、连贯性到有效性等五个角度,对模型在生成过程中可能暴露的失误进行细致划分。错误类别与定义如表 1所示,为后续的错误检测与缓解方法奠定了统一的分析基础。具体的错误样例和解释如表 2所示。
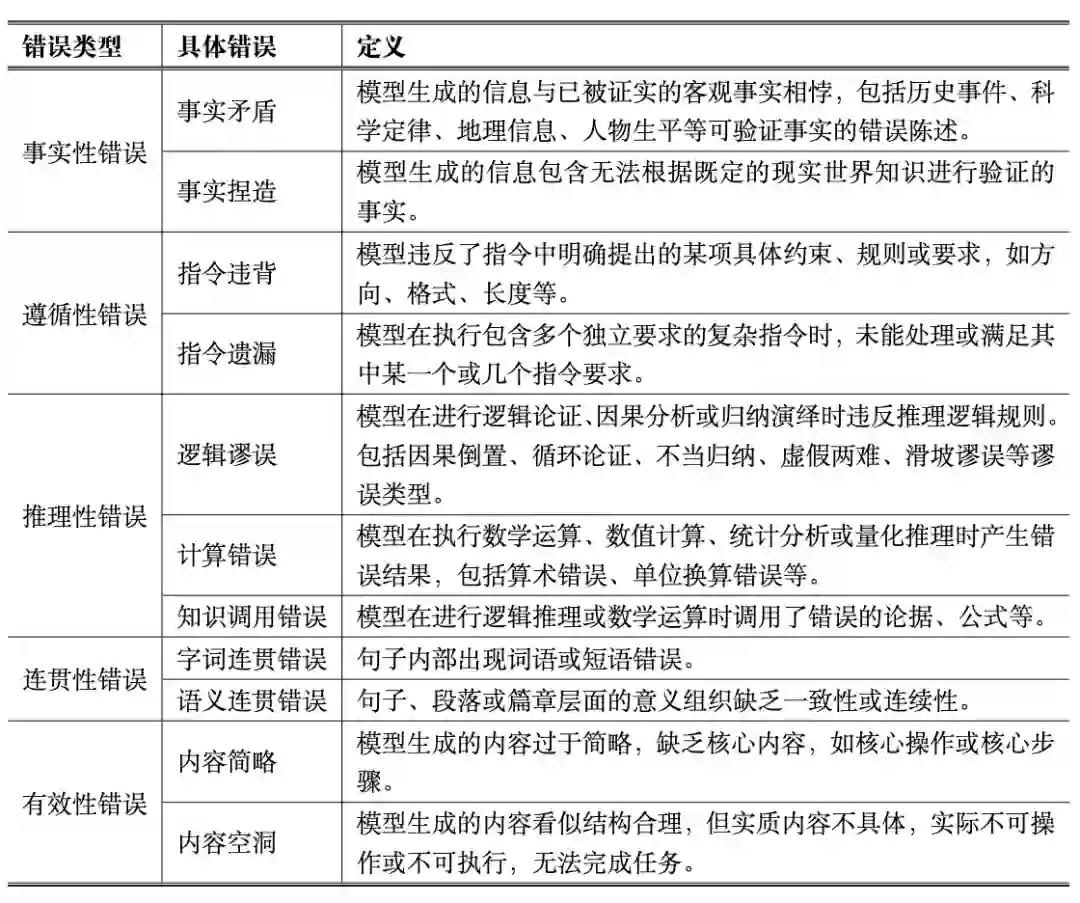
表1:错误类别与定义
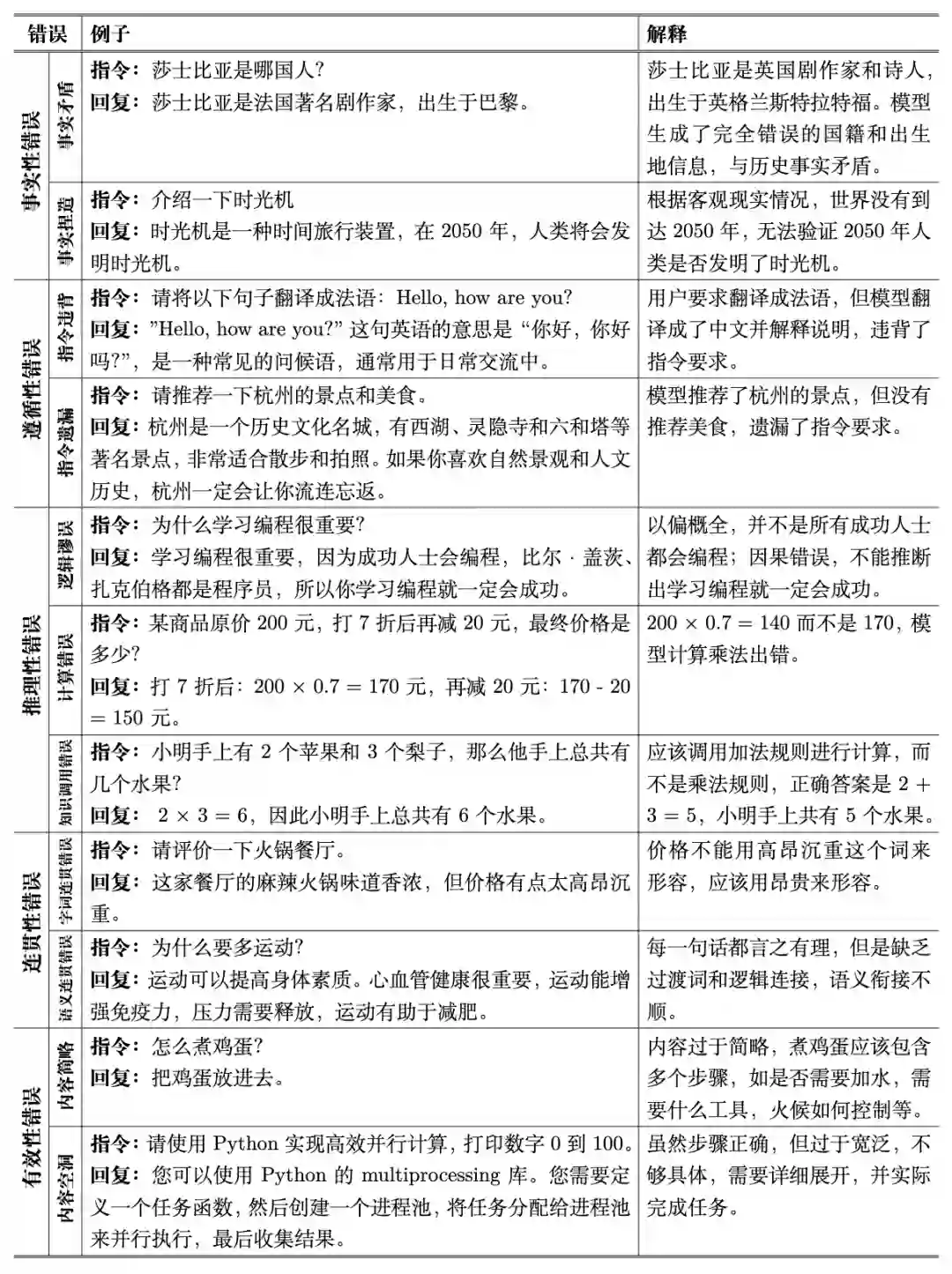
表2:错误类型具体样例 3. 基于信息损失的错误根因分析 大模型错误的根因是指导致大模型输出偏离正确目标的潜在机制性因素中产生决定性影响的内在动因。与作为可观测现象的大模型错误相比,大模型错误根因无法直接获取,而是依赖大量分析工具沿着因果链条向大模型内部机制溯源。随着溯因分析的深入,错误根因往往会与错误缓解手段产生直接关联。关于大模型错误根因与错误的具体区别主要体现为:二者分别处于机制层与现象层,对应“为什么会错”与“错在了哪里”。错误是可观测输出偏差,其判定依赖将模型输出与人类预期比较,例如人类可以轻易发现模型输出推理链条中的漏洞;错因是内部机制,其确认依赖因果诊断而非仅凭表层比对,例如需要判定某种错误根因的类型需要有对该机制相关变量进行控制性改变并能稳定地对模型错误产生一致的观测结果。由此导出三个可操作的区分准则:(1) 可观测性:错误可由输出与预期直接判定,错因需通过机制证据或干预验证;(2) 可修复性:错因往往对应修复手段,而错误不具备可修复下;(3) 再现性:错因在有效的观测手段下一般稳定可复现,而错误受到大量因素干扰存在一定的随机性。在研究大模型错误的根因时,我们从大模型完整部署周期中信息流动与损失的视角出发,提出一种基于信息损失区间的根因分类体系。该体系认为,大语言模型从知识获取、参数化学习到指令理解与知识表达的全过程,构成了一条连续的信息传递链。真实世界知识被采样为知识库,通过模型训练被压缩进参数空间,再经由用户输入激活、解析、推理并输出为自然语言结果。任何环节的信息丢失、失真或偏移,都会在最终输出层面表现为不同类型的错误。因此,我们将大模型错误的根因划分为四个主要的信息损失区间:知识整合损失、信息压缩损失、指令理解损失与知识表达损失。这一分类框架以信息论为基础,强调错误并非孤立的输出偏差,而是信息在流经不同阶段时发生衰减与变形的结果。完整流程如图 2所示。
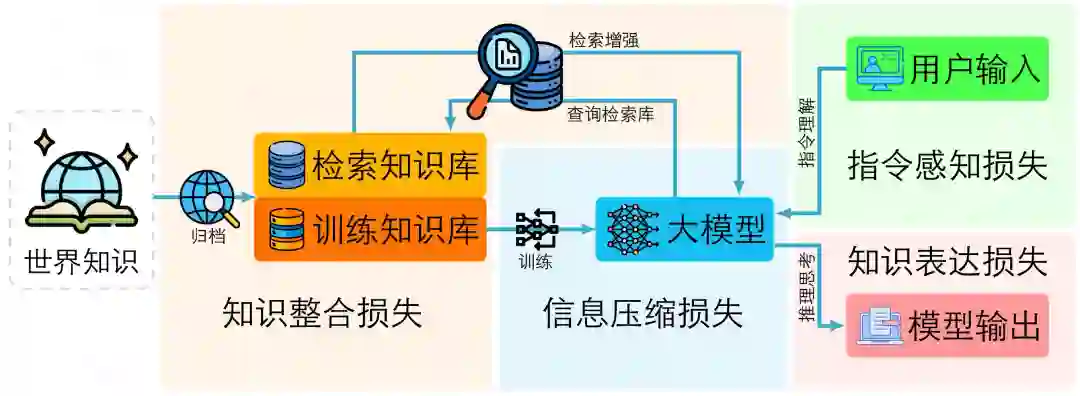
图2:基于大模型部署完整周期中信息流动损失的根因分类框架 首先,知识整合损失指真实世界知识与模型使用的知识库之间的不完全映射,这个知识库既能用于后续的模型训练,也可以作为检索来源作为生成阶段的补充信息。当知识库的采样存在覆盖不足、时间滞后或文化与领域偏倚等问题时,模型所能使用的知识分布即偏离了真实世界分布。这种采样与整合的不充分,导致模型在认知层面存在知识盲区或结构性缺口,从而成为事实性错误的根源。该损失反映了数据层的信息采样极限,与信息论中的采样定理相呼应:有限样本无法完备地表征连续的真实知识空间。 其次,知识压缩损失发生在模型训练阶段,是语料知识向参数空间映射时不可避免的信息退化。由于参数容量、优化目标与正则化约束的限制,模型在内化知识时会丢失部分细粒度信息或错误地混叠语义概念。根据信息瓶颈理论,神经网络在优化过程中会主动舍弃输入中的非判别信息以提升泛化性能,但这种“有益压缩”在知识建模任务中往往伴随着信息丢失,其具体表现为模型遗忘、模糊或错误地重构知识片段等。这一损失反映了模型结构与训练过程的根本约束,是参数化记忆能力不足的直接体现。 第三,指令理解损失指用户输入的自然语言指令在被模型解析为内部表示时的语义歧义、上下文遗忘或目标误解。大模型需要在高维语义空间中将符号化的语言信号映射为可操作的内部目标表示,任何映射误差都会引起意图偏离。这种损失属于交互层与对齐层的错因,其本质是一种编码到解码不对称性问题:输入语言的信息量在传递到模型内部时被不完全保留,从而造成模型行为与人类预期的错位。典型表现包括指令遵循错误、上下文不一致以及任务目标偏移。 最后,知识表达损失发生在生成阶段,即模型将内部知识重新映射为自然语言输出的过程中出现的失真或不稳定。当推理与解码策略,如采样温度、束搜索、规划式生成等,导致输出分布偏移时,模型可能无法准确表达其内部知识状态,进而产生事实错误、逻辑跳跃或叙述不连贯。这一损失刻画了输出层的信息再编码过程,其信息失真通常来源于概率估计不精确或解码机制的过强约束。信息论上,这对应于从潜在分布到可观测语言分布的近似重建误差。 综上所述,这一基于信息损失的根因分类框架,从宏观上揭示了大模型错误产生的四个关键环节,构成从知识采集到生成输出的完整因果闭环。与以往基于功能模块(如数据、优化、对齐等)的分类方法相比,该框架具有三方面优势:(1) 理论统一性:以信息流为主线将多类型错误归结为信息在不同阶段的损失表现;(2) 因果可解释性:每一类损失均可对应到可干预的机制变量,例如可通过数据扩充、模型微调或解码控制进行修复;(3) 模型无关性:该框架依赖信息传递过程而非具体架构设计,适用于不同类型的语言模型及多模态生成系统。由此,大模型错误的分析不再停留于现象描述,而转化为对信息损失路径的系统诊断,为后续的错因溯源与针对性改进提供了可理论化的基础。 3.1 知识整合损失 知识整合损失是指模型在知识获取与整合阶段,由于数据采样与组织的局限性而产生的系统性偏差。这类损失发生在真实世界知识向模型可见语料转化的初始环节,决定了模型可学习知识的上限。其核心问题在于知识库与真实知识分布之间的不匹配,表现为知识的缺失、错误、冲突或不均衡覆盖等。当正确知识不存在于语料中时,模型将不可避免地出现知识个例失真,表现为事实性错误或推理盲区;即便知识存在,若其在语料中的分布不佳,如稠密区域的过度重复与长尾区域的极度稀疏,也会导致模型学习到的概率结构与真实世界显著偏离,进一步放大知识不确定性。知识整合损失的产生机制可以用信息采样定理解释:有限语料只能对真实世界知识空间进行离散近似,因此不可避免存在抽样失真。知识整合损失的诊断可通过知识分布分析与错误回溯实现,例如检索或知识补全后模型性能显著改善往往意味着原始语料的覆盖缺陷。针对这类根因,研究可通过多源知识融合、长尾样本扩展、数据去偏与一致性校验等手段进行干预,从而提升模型在事实性与广域知识任务上的稳健性。
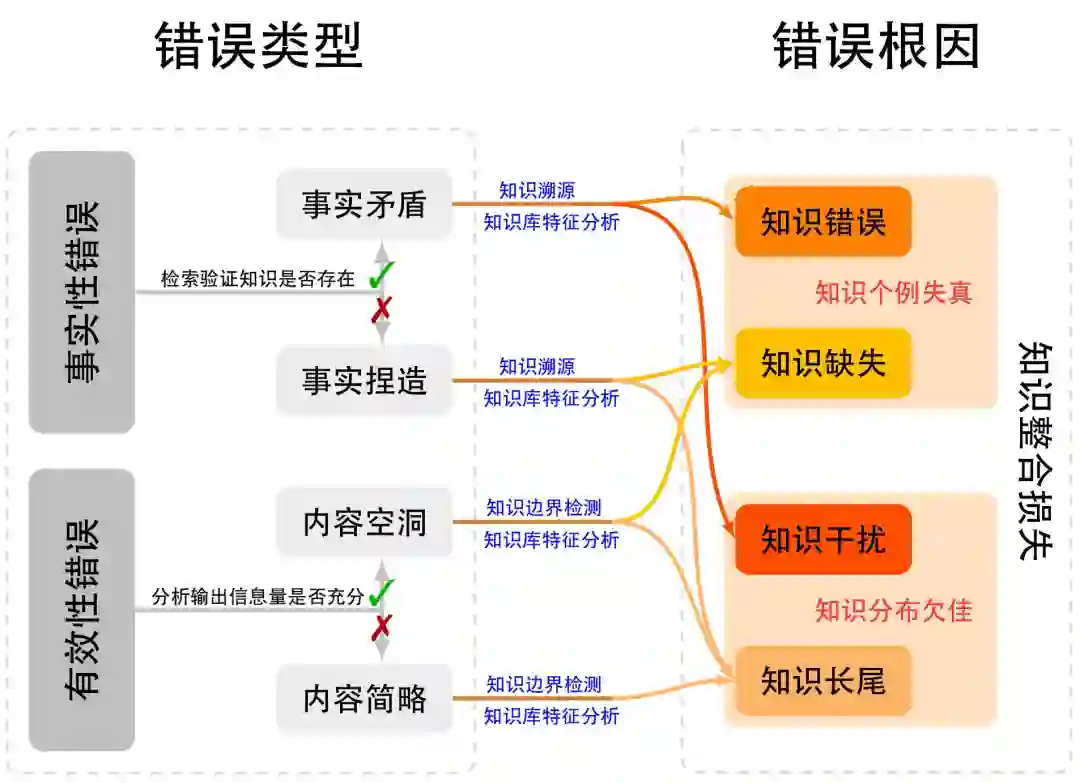
图3:知识整合损失根因细化图 如图 3所示,大语言模型知识整合损失主要源于两个相互独立但彼此交织的层面:其一是知识个例失真,即知识库可能未能正确收录目标知识导致训练数据中具体知识样本出现质量问题;其二是知识分布欠佳,即知识整体分布不均而难以被大模型有效学习或利用。这两个层面分别对应微观与宏观的知识缺陷,共同决定了模型在知识整合与推理中的可靠性。 3.2 信息压缩损失 信息压缩损失指在模型训练过程中,外部知识被映射并压缩到有限参数空间时发生的不可逆信息丢失与语义退化。该阶段位于知识整合之后,代表了从语料知识到参数表示的转换环节。根据信息瓶颈理论,深度网络在学习过程中往往牺牲部分输入信息以追求泛化与压缩效率,但当任务目标为知识保持时,这种压缩可能带来有害的信息损失。压缩损失主要体现在两类机制:一方面是新能力赋予时对旧有的基座能力破坏,即新的训练目标或微调过程与原有预训练能力发生冲突,导致基础语义或推理能力退化;另一方面是新能力赋予过程本身的训练方法缺陷,例如优化目标存在现实缺陷、超参数设定不当、或强化学习信号过度引导等问题,均可能造成梯度冲突与表示塌缩。此类损失常表现为模型在下游任务中出现能力倒退或记忆遗忘的现象,尤其在微调覆盖关键参数时尤为明显。信息压缩损失的诊断可通过基座能力测试、能力相容性分析及参数敏感性实验完成。针对该类问题,可采用能力守恒微调(如参数隔离或低秩适配)、正交梯度约束、多目标优化以及预训练数据回放等策略,以降低知识压缩带来的结构性退化。总体而言,信息压缩损失揭示了模型在知识内化阶段的物理极限,是理解模型能力边界和训练稳定性的重要理论支点。
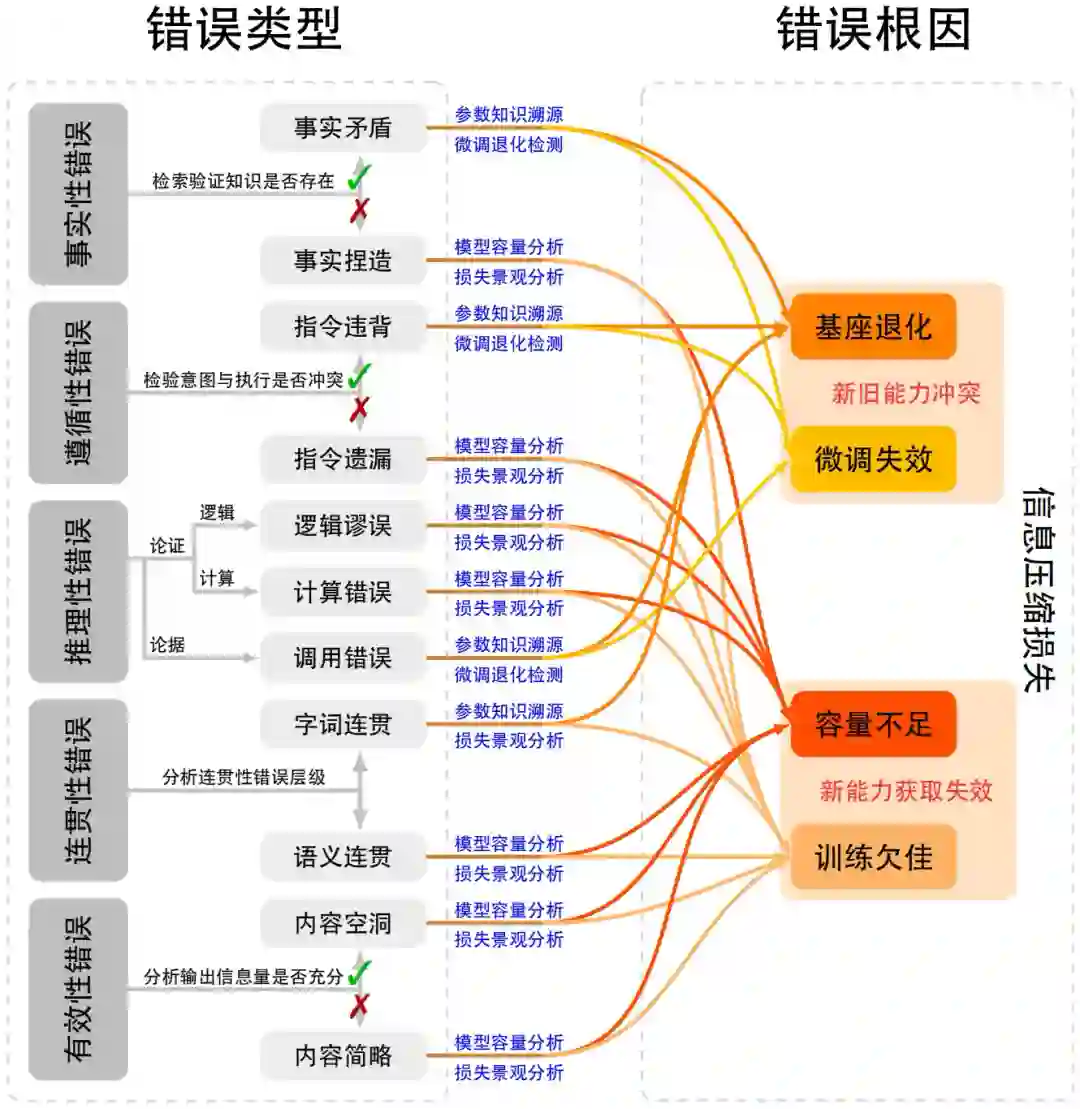
图4:信息压缩损失根因细化图 如图 4所示,信息压缩损失是大语言模型在知识整合后的参数内化阶段出现的核心问题,主要源于两个相互独立但彼此交织的层面:其一是新旧能力冲突,指新能力训练与原有基座能力产生干扰,导致既有知识与能力被破坏[108-111] ,或者旧能力干扰新能力的学习[112-114] ;其二是新能力获取失效,指模型因参数容量限制[115-116] 或训练策略缺陷,难以有效吸收并稳定表达新能力。这两个层面分别对应能力交互的破坏性干扰与能力学习的承载策略缺陷,共同决定模型在知识内化和任务执行中的稳定性,也是后续事实性错误、 推理性错误等问题的关键参数层面诱因。此外,这两个维度背后共同的机制是信息压缩[117] ,在有限参数空间内对外部数据进行表示时不可避免地产生筛选、折损与竞争,从而在不同训练阶段显现为不同形式的系统性误差。 3.3 指令感知损失 指令感知损失是指模型在理解用户输入、解析语义指令或执行多轮交互时的信息传递缺口。它发生于输入端,是从外部指令到内部任务表示之间的语义映射失真。当模型虽具备一定理解潜力但泛化不足时,损失表现为对不同输入表述形式缺乏等价理解:例如在简单输入场景中,对描述方式变化的鲁棒性不足;在复杂输入场景中,则表现为任务结构解析错误、上下文记忆衰减或意图漂移。此外,当输入指令超出模型的训练分布范围,模型可能完全无法建立内部任务表示,形成理解缺失。从信息论角度看,该损失对应编码—解码不对称性问题,即自然语言指令在传递至模型内部语义空间时的信息保真度下降。其诊断方法包括输入重构与抗扰测试:若通过指令重写、任务分解或上下文重组即可显著提升输出一致性,则可归因于指令感知损失。此类问题的干预可通过输入指令标准化与模板化设计、层级推理提示(如 Chain-of-Thought 或 Tree-of-Thought)、上下文语义去干扰、以及基于偏好对齐的轻量强化学习实现。值得注意的是,指令感知损失往往是信息压缩损失与知识表达损失之间的中介环节,其存在直接影响模型在实际应用中的任务对齐度与交互稳定性。
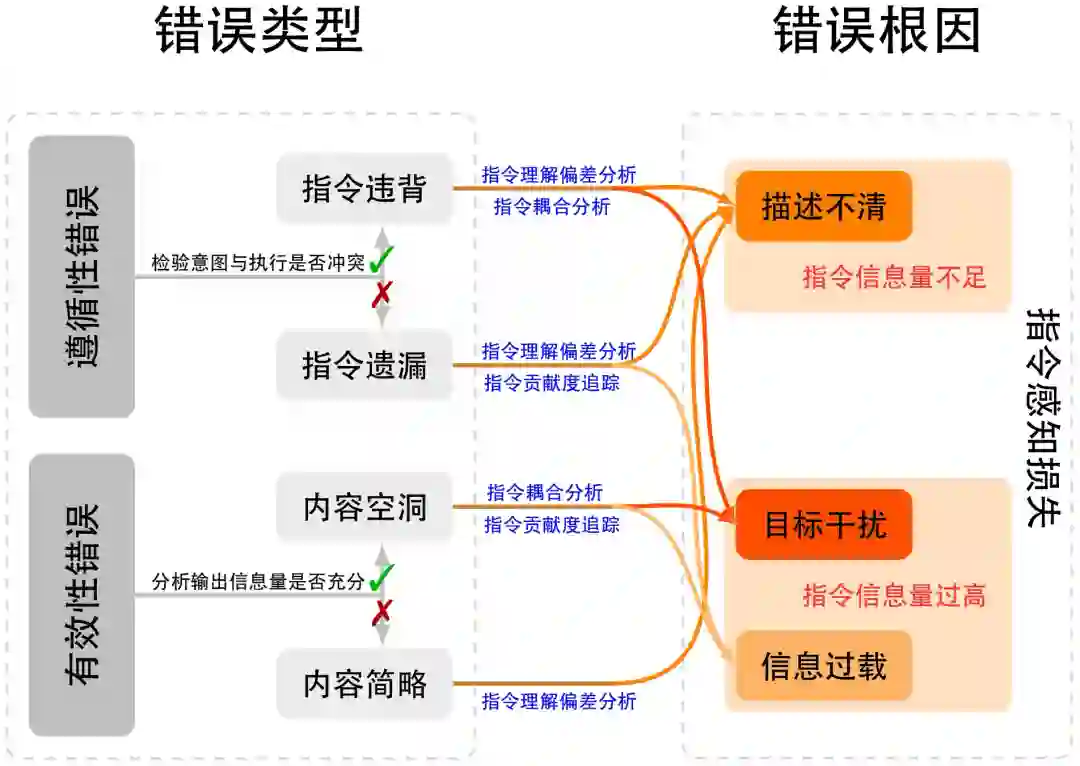
图5:指令感知损失根因细化图 如图 5所示,指令感知损失主要源于两类相互独立却彼此关联的根因:其一是指令信息量不足,即用户输入中缺乏完成任务所需的核心语义成分,使模型难以准确建立内部任务表示,从而在意图理解上产生偏差;其二是指令信息量过高,即输入包含过度复杂或冗余的信息结构,超出模型即时解析与记忆能力,使语义映射过程发生退化。这两个层面分别对应指令表达不足与表达过载的极端情况,共同决定了模型在现实交互中对指令的理解保真度与执行稳定性。 3.4 知识表达损失 知识表达损失指模型在生成阶段将内部知识重新映射为自然语言输出时的信息失真或逻辑断裂。该损失发生在推理与解码阶段,代表了从内部知识到外部输出之间的再编码误差。其本质可分为两类机制:一方面是知识应用不足,即模型虽然具备正确的内部知识,但在具体推理步骤中调用失败,表现为思维链断裂、使用不当证据、或约束条件未被遵守;另一方面是推理能力不足,即模型无法稳定地完成长程逻辑依赖或因果规划,导致结果层面出现不一致、跳跃或非稳态波动。该损失的出现源于模型建模潜在分布的序列重建时累计的近似误差,当解码策略(如温度采样、束搜索、重采样等)未能精确反映模型的真实信念分布时,输出会偏离正确轨迹。知识表达损失的诊断通常依赖可解释推理分析与生成多样性测度:若通过解码策略调整、规划式生成即可显著缓解,则可确认属于表达层信息损失。针对该类问题,可引入规划化生成框架、约束解码与事实核验机制,以及外部工具调用或自一致性校验等增强手段。与前三类损失不同,知识表达损失直接影响模型输出质量与可靠性,是连接能力与表现的关键桥梁,其系统性研究对于实现稳健生成和可解释推理具有重要意义。
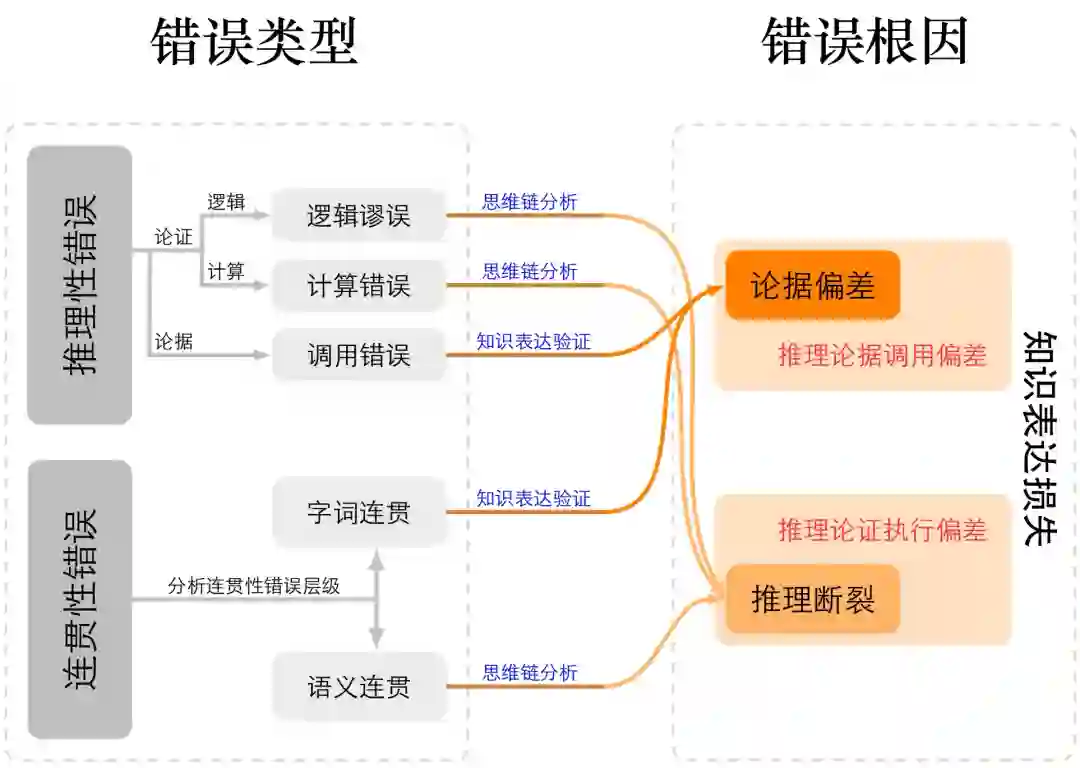
图6:知识表达损失根因细化图 如图 6所示,我们依据思维链在生成过程中的分解方式,将知识表达损失划分为两类根因:推理过程中的论据调用偏差与论证执行偏差。前者对应推理链条的步骤出错,后者对应最终推理总结的结果出错,两者共同构成了模型语言生成失真的核心机制。
4. 参考文献
[1] ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[A]. 2023. [2] TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: open and efficient foundation language models. arxiv[A]. 2023. [3] TOUVRON H, MARTIN L, STONE K, et al. Llama 2: Open foundation and fine-tuned chat models[A]. 2023. [4] DUBEY A, JAUHRI A, PANDEY A, et al. The llama 3 herd of models[A]. 2024. [5] OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744. [6] VASWANI A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017. [7] DEVLIN J. Bert: Pre-training of deep bidirectional transformers for language understanding[A]. 2018. [8] BROWN T B. Language models are few-shot learners[A]. 2020. [9] KAPLAN J, MCCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models[A]. 2020. [10] AGHAJANYAN A, YU L, CONNEAU A, et al. Scaling laws for generative mixed-modal language models[C]// International Conference on Machine Learning. PMLR, 2023: 265-279. [11] YI Z, OUYANG J, LIU Y, et al. A survey on recent advances in llm-based multi-turn dialogue systems[A]. 2024. [12] JIANG J, WANG F, SHEN J, et al. A survey on large language models for code generation[A]. 2024. [13] PLAAT A, WONG A, VERBERNE S, et al. Reasoning with large language models, a survey[A]. 2024. [14] HUANG L, YU W, MA W, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions[J]. ACM Transactions on Information Systems, 2025, 43(2): 1-55. [15] LOU R, ZHANG K, YIN W. Large language model instruction following: A survey of progresses and challenges[J]. Computational Linguistics, 2024, 50(3): 1053-1095. [16] YUN L, PENG L, SHANG J. ULTRABENCH: Benchmarking LLMs under extreme fine-grained text generation [C/OL]//CHRISTODOULOPOULOS C, CHAKRABORTY T, ROSE C, et al. Findings of the Association for Computational Linguistics: EMNLP 2025. Suzhou, China: Association for Computational Linguistics, 2025: 15438- 15453. https://aclanthology.org/2025.findings-emnlp.835/. DOI: 10.18653/v1/2025.findings-emnlp.835. [17] LABAN P, HAYASHI H, ZHOU Y, et al. Llms get lost in multi-turn conversation[A]. 2025. [18] DOSHI-VELEZ F, KIM B. Towards a rigorous science of interpretable machine learning[A]. 2017. [19] LIPTON Z C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery.[J]. Queue, 2018, 16(3): 31-57. [20] RUDIN C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead[J]. Nature machine intelligence, 2019, 1(5): 206-215. [21] HASSIJA V, CHAMOLA V, MAHAPATRA A, et al. Interpreting black-box models: a review on explainable artificial intelligence[J]. Cognitive Computation, 2024, 16(1): 45-74. [22] RAMACHANDRAM D, JOSHI H, ZHU J, et al. Transparent ai: The case for interpretability and explainability [A]. 2025. [23] BLAGEC K, DORFFNER G, MORADI M, et al. A critical analysis of metrics used for measuring progress in artificial intelligence[A]. 2020. [24] WANG Y, WANG X. A unified study of machine learning explanation evaluation metrics: abs/2203.14265[A/OL]. 2022. https://api.semanticscholar.org/CorpusID:247762126. [25] NAUTA M, TRIENES J, PATHAK S, et al. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable ai[J]. ACM Computing Surveys, 2023, 55(13s): 1-42. [26] MARCINKEVICS R, VOGT J E. Interpretable and explainable machine learning: A methods‐centric overview with concrete examples[J/OL]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2023, 13. https://api.semanticscholar.org/CorpusID:257290340. [27] COOK J, ROCKTÄSCHEL T, FOERSTER J N, et al. Ticking all the boxes: Generated checklists improve llm evaluation and generation: abs/2410.03608[A/OL].2024. https://api.semanticscholar.org/CorpusID:273162357. [28] VISWANATHAN V, SUN Y, KONG X, et al. Checklists are better than reward models for aligning language models[C/OL]//The Thirty-ninth Annual Conference on Neural Information Processing Systems. 2025. https://openreview.net/forum?id=RPRqKhjrr6. [29] WEI T, WEN W, QIAO R, et al. Rocketeval: Efficient automated LLM evaluation via grading checklist[C/OL]//The Thirteenth International Conference on Learning Representations. 2025. https://openreview.net/forum?id=zJjzNj6QUe. [30] HEWITT J, MANNING C D. A structural probe for finding syntax in word representations[C/OL]//North American Chapter of the Association for ComputationalLinguistics.2019.https://api.semanticscholar.org/CorpusID:106402715. [31] PENG H, WANG X, HU S, et al. COPEN: Probing conceptual knowledge in pre-trained language models[C/OL]//GOLDBERG Y, KOZAREVA Z, ZHANG Y. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022: 5015- 5035. https://aclanthology.org/2022.emnlp-main.335/. DOI: 10.18653/v1/2022.emnlp-main.335. [32] HEO J, XIONG M, HEINZE-DEML C, et al. Do LLMs estimate uncertainty well in instruction-following?[C/OL]// The Thirteenth International Conference on Learning Representations. 2025. https://openreview.net/forum?id=IHp3vOVQO2. [33] HEO J, HEINZE-DEML C, ELACHQAR O, et al. Do llms” know” internally when they follow instructions?[A].2024. [34] XIA Z, XU J, ZHANG Y, et al. A survey of uncertainty estimation methods on large language models[C/OL]//CHE W, NABENDE J, SHUTOVA E, et al. Findings of the Association for Computational Linguistics: ACL 2025. Vienna, Austria: Association for Computational Linguistics, 2025: 21381-21396. https://aclanthology.org/2025.findings-acl.1101/. DOI: 10.18653/v1/2025.findings-acl.1101. [35] SHORINWA O, MEI Z, LIDARD J, et al. A survey on uncertainty quantification of large language models:Taxonomy, open research challenges, and future directions[J/OL]. ACM Computing Surveys, 2024, 58: 1 - 38.https://api.semanticscholar.org/CorpusID:274597654. [36] HEIMERSHEIM S, NANDA N. How to use and interpret activation patching: abs/2404.15255[A/OL].2024.https://api.semanticscholar.org/CorpusID:269302704. [37] ZHANG F, NANDA N. Towards best practices of activation patching in language models: Metrics and methods[C/OL]//The Twelfth International Conference on Learning Representations. 2024. https://openreview.net/forum?id=Hf17y6u9BC. [38] BAYAZIT D, MUELLER A, BOSSELUT A. Crosscoding through time: Tracking emergence & consolidation of linguistic representations throughout llm pretraining:abs/2509.05291[A/OL].2025.https://api.semanticscholar.org/CorpusID:281195050. [39] LI Z, ZHAO W, LI Y, et al. Where did it go wrong? attributing undesirable llm behaviors via representation gradient tracing: abs/2510.02334[A/OL]. 2025. https://api.semanticscholar.org/CorpusID:281829830. [40] CHENG S, LI J, WANG H, et al. Ragtrace: Understanding and refining retrieval-generation dynamics in retrieval-augmented generation[J/OL]. Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, 2025. https://api.semanticscholar.org/CorpusID:280561815. [41] WEN B, KE P, GU X, et al. Benchmarking complex instruction-following with multiple constraints composition. corr, abs/2407.03978, 2024. doi: 10.48550[A]. [42] WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models [J]. Advances in neural information processing systems, 2022, 35: 24824-24837. [43] HE Y, LI S, LIU J, et al. Can large language models detect errors in long chain-of-thought reasoning?[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025: 18468-18489. [44] GOYAL T, LI J J, DURRETT G. Snac: Coherence error detection for narrative summarization[A]. 2022. [45] RIBEIRO M T, WU T, GUESTRIN C, et al. Beyond accuracy: Behavioral testing of NLP models with CheckList [C/OL]//JURAFSKY D, CHAI J, SCHLUTER N, et al. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020: 4902-4912. https://acla nthology.org/2020.acl-main.442/. DOI: 10.18653/v1/2020.acl-main.442. [46] KUCHNIK M, SMITH V, AMVROSIADIS G. Validating large language models with relm[J]. Proceedings of Machine Learning and Systems, 2023, 5: 457-476. [47] KIM J, PARK S, KWON Y, et al. Factkg: Fact verification via reasoning on knowledge graphs[A]. 2023. [48] MIN S, KRISHNA K, LYU X, et al. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023:12076-12100. [49] PENG B, GALLEY M, HE P, et al. Check your facts and try again: Improving large language models with external knowledge and automated feedback[A]. 2023. [50] HUO S, ARABZADEH N, CLARKE C L. Retrieving supporting evidence for llms generated answers[A]. 2023. [51] KADAVATH S, CONERLY T, ASKELL A, et al. Language models (mostly) know what they know[A]. 2022. [52] DHULIAWALA S, KOMEILI M, XU J, et al. Chain-of-verification reduces hallucination in large language models [C/OL]//Annual Meeting of the Association for Computational Linguistics. 2023. https://api.semanticscholar.org/CorpusID:262062565. [53] SAUNDERS W, YEH C, WU J, et al. Self-critiquing models for assisting human evaluators[A]. 2022. [54] LI J, CHENG X, ZHAO W X, et al. Halueval: A large-scale hallucination evaluation benchmark for large language models[A]. 2023. [55] ZHANG T, KISHORE V, WU F, et al. Bertscore: Evaluating text generation with bert: abs/1904.09675[A/OL]. 2019. https://api.semanticscholar.org/CorpusID:127986044. [56] VARSHNEY N, YAO W, ZHANG H, et al. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation[A]. 2023. [57] VRANDEČIĆ D, KRÖTZSCH M. Wikidata[J/OL]. Communications of the ACM, 2014, 57: 78 - 85. https://api.semanticscholar.org/CorpusID:14494942. [58] BOLLACKER K D, EVANS C, PARITOSH P K, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C/OL]//SIGMOD Conference. 2008. https://api.semanticscholar.org/CorpusID: 207167677. [59] XU B, XU Y, LIANG J, et al. Cn-dbpedia: A never-ending chinese knowledge extraction system[C/OL]// International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. 2017. https://api.semanticscholar.org/CorpusID:1627142. [60] National Library of Medicine (US). Pubmed[EB/OL]. 1996. https://pubmed.ncbi.nlm.nih.gov/. [61] The World Bank. World bank open data[EB/OL]. https://data.worldbank.org/. [62] YUE Z, ZENG H, SHANG L, et al. Retrieval augmented fact verification by synthesizing contrastive arguments [A]. 2024. [63] ZHOU J, LU T, MISHRA S, et al. Instruction-following evaluation for large language models[A]. 2023. [64] JANG D, AHN Y, SHIN H. RCScore: Quantifying response consistency in large language models[C/OL]//CHRISTODOULOPOULOS C, CHAKRABORTY T, ROSE C, et al. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, 2025: 5701-5719. https://aclanthology.org/2025.emnlp-main.290/. DOI: 10.18653/v1/2025.emnlp-main.290. [65] CHEN M. Evaluating large language models trained on code[A]. 2021. [66] CHIANG W L, ZHENG L, SHENG Y, et al. Chatbot arena: An open platform for evaluating llms by human preference[C]//Forty-first International Conference on Machine Learning. 2024. [67] JIN Z, LALWANI A, VAIDHYA T, et al. Logical fallacy detection[A]. 2022. [68] GAO L, MADAAN A, ZHOU S, et al. Pal: Program-aided language models[C]//International Conference on Machine Learning. PMLR, 2023: 10764-10799. [69] LIGHTMAN H, KOSARAJU V, BURDA Y, et al. Let’s verify step by step[C]//The Twelfth International Conference on Learning Representations. 2023. [70] ZHANG Z, ZHENG C, WU Y, et al. The lessons of developing process reward models in mathematical reasoning [A]. 2025. [71] AZARIA A, MITCHELL T. The internal state of an llm knows when it’s lying[A]. 2023. [72] BURNS C, YE H, KLEIN D, et al. Discovering latent knowledge in language models without supervision[A]. 2022. [73] SHINN N, CASSANO F, GOPINATH A, et al. Reflexion: Language agents with verbal reinforcement learning[J]. Advances in Neural Information Processing Systems, 2023, 36: 8634-8652. [74] REIMERS N, GUREVYCH I. Sentence-bert: Sentence embeddings using siamese bert-networks[A]. 2019. [75] GAO T, YAO X, CHEN D. Simcse: Simple contrastive learning of sentence embeddings[A]. 2021. [76] CHURCH K, HANKS P. Word association norms, mutual information, and lexicography[J]. Computational linguistics, 1990, 16(1): 22-29. [77] LI J, JURAFSKY D. Neural net models of open-domain discourse coherence[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 198-209. [78] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3 (Jan): 993-1022. [79] GROOTENDORST M. Bertopic: Neural topic modeling with a class-based tf-idf procedure[A]. 2022. [80] HOLTZMAN A, BUYS J, DU L, et al. The curious case of neural text degeneration[A]. 2019. [81] LIN C Y. Rouge: A package for automatic evaluation of summaries[C]//Text summarization branches out. 2004:74-81. [82] ZHENG L, CHIANG W L, SHENG Y, et al. Judging llm-as-a-judge with mt-bench and chatbot arena[J]. Advances in neural information processing systems, 2023, 36: 46595-46623. [83] HAVRILLA A, IYER M. Understanding the effect of noise in llm training data with algorithmic chains of thought [A]. 2024. [84] ZHU K, FENG X, DU X, et al. An information bottleneck perspective for effective noise filtering on retrieval-augmented generation[A]. 2024. [85] MALLEN A, ASAI A, ZHONG V, et al. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023: 9802-9822. [86] ZHOU C, LIU P, XU P, et al. Lima: Less is more for alignment[J]. Advances in Neural Information Processing Systems, 2023, 36: 55006-55021. [87] SONG F, YU B, LANG H, et al. Scaling data diversity for fine-tuning language models in human alignment[A].2024. [88] LEE K, IPPOLITO D, NYSTROM A, et al. Deduplicating training data makes language models better[C/OL]//MURESAN S, NAKOV P, VILLAVICENCIO A. Proceedings of the 60th Annual Meeting of the Association forComputational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics,2022: 8424-8445. https://aclanthology.org/2022.acl-long.577/. DOI: 10.18653/v1/2022.acl-long.577. [89] WANG Z, WANG P, LIU K, et al. A Comprehensive Survey on Data Augmentation [J/OL]. IEEE Transactions on Knowledge & Data Engineering, 5555(01):1-20https://doi.ieeecomputersociety.org/10.1109/TKDE.2025.3622600. [90] MENG K, BAU D, ANDONIAN A, et al. Locating and editing factual associations in GPT[J]. Advances in Neural Information Processing Systems, 2022, 35. [91] YAO Y, WANG P, TIAN B, et al. Editing large language models: Problems, methods, and opportunities[C/OL]//BOUAMOR H, PINO J, BALI K. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, 2023: 10222-10240. https://aclanthology.org/2023.emnlp-main.632/. DOI: 10.18653/v1/2023.emnlp-main.632. [92] GAO Y, XIONG Y, GAO X, et al. Retrieval-augmented generation for large language models: A survey: abs/2312.10997[A/OL]. 2023. https://api.semanticscholar.org/CorpusID:266359151. [93] LEWIS P, PEREZ E, PIKTUS A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks: abs/2005.11401[A/OL]. 2020. https://api.semanticscholar.org/CorpusID:218869575. [94] KARPUKHIN V, OGUZ B, MIN S, et al. Dense passage retrieval for open-domain question answering[C/OL]//WEBBER B, COHN T, HE Y, et al. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online: Association for Computational Linguistics, 2020: 6769-6781. https://aclanthology.org/2020.emnlp-main.550/. DOI: 10.18653/v1/2020.emnlp-main.550. [95] BORGEAUD S, MENSCH A, HOFFMANN J, et al. Improving language models by retrieving from trillions of tokens[C/OL]//International Conference on Machine Learning. 2021. https://api.semanticscholar.org/CorpusID:244954723. [96] DENG Y, ZHAO Y, LI M, et al. Don’t just say “I don’t know”! self-aligning large language models for responding to unknown questions with explanations[C/OL]//AL-ONAIZAN Y, BANSAL M, CHEN Y N. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: Association for Computational Linguistics, 2024: 13652-13673. https://aclanthology.org/2024.emnlp-main.757/. DOI: 10.18653/v1/2024.emnlp-main.757. [97] HUANG L, FENG X, MA W, et al. Alleviating Hallucinations from Knowledge Misalignment in Large Language Models via Selective Abstention Learning[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025: 24564-24579. [98] HUANG L, FENG X, MA W, et al. Improving contextual faithfulness of large language models via retrieval heads-induced optimization[A]. 2025. [99] SHANGGUAN Z, DONG Y, WANG L, et al. Exploring and mitigating fawning hallucinations in large language models[J]. Neurocomputing, 2025: 132166. [100] OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback: abs/2203.02155[A/OL]. 2022. https://api.semanticscholar.org/CorpusID:246426909. [101] GUNEL B, DU J, CONNEAU A, et al. Supervised contrastive learning for pre-trained language model fine-tuning [C/OL]//International Conference on Learning Representations. 2021. https://openreview.net/forum?id=cu7IUiOhujH. [102] ROBINSON J D, CHUANG C Y, SRA S, et al. Contrastive learning with hard negative samples[C/OL]// International Conference on Learning Representations. 2021. https://openreview.net/forum?id=CR1XOQ0UTh-. [103] WANG Z, ZHONG W, WANG Y, et al. Data management for training large language models: A survey[A/OL]. 2024. arXiv: 2312.01700. https://arxiv.org/abs/2312.01700. [104] ZHOU T, CHEN Y, CAO P, et al. Oasis: Data curation and assessment system for pretraining of large language models: abs/2311.12537[A/OL]. 2023. https://api.semanticscholar.org/CorpusID:265308678. [105] KANG B, XIE S, ROHRBACH M, et al. Decoupling representation and classifier for long-tailed recognition[C/OL]// International Conference on Learning Representations. 2020. https://openreview.net/forum?id=r1gRTCVFvB. [106] YASUNAGA M, LESKOVEC J, LIANG P. LinkBERT: Pretraining language models with document links[C/OL]// MURESAN S, NAKOV P, VILLAVICENCIO A. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics, 2022: 8003-8016. https://aclanthology.org/2022.acl-long.551/. DOI: 10.18653/v1/2022.acl-long.551. [107] KHANDELWAL U, LEVY O, JURAFSKY D, et al. Generalization through memorization: Nearest neighbor language models[C/OL]//International Conference on Learning Representations. 2020. https://openreview.net/forum?id=HklBjCEKvH. [108] WANG Z, YANG E, SHEN L, et al. A comprehensive survey of forgetting in deep learning beyond continual learning[J/OL]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 47: 1464-1483. https: //api.semanticscholar.org/CorpusID:259951356. [109] WANG L, ZHANG X, SU H, et al. A comprehensive survey of continual learning: Theory, method and application [J/OL]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 46: 5362-5383. https://api.semanticscholar.org/CorpusID:256459333. [110] LI H, DING L, FANG M, et al. Revisiting catastrophic forgetting in large language model tuning[C/OL]//ALONAIZAN Y, BANSAL M, CHEN Y N. Findings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, 2024: 4297-4308. https://aclanthology.org/2024. findings-emnlp.249/. DOI: 10.18653/v1/2024.findings-emnlp.249. [111] LIN Y, LIN H, XIONG W, et al. Mitigating the alignment tax of RLHF[C/OL]//AL-ONAIZAN Y, BANSAL M, CHEN Y N. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: Association for Computational Linguistics, 2024: 580-606. https://aclanthology.org/2024.emnlp-main.35/. DOI: 10.18653/v1/2024.emnlp-main.35. [112] SPRINGER J M, GOYAL S, WEN K, et al. Overtrained language models are harder to fine-tune[C/OL]//Forty-second International Conference on Machine Learning. 2025. https://openreview.net/forum?id=YW6edSufht. [113] WANG Z, SHI Z, ZHOU H, et al. Towards objective fine-tuning: How LLMs’ prior knowledge causes potential poor calibration?[C/OL]//CHE W, NABENDE J, SHUTOVA E, et al. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025: 14830-14853. https://aclanthology.org/2025.acl-long.722/. DOI: 10.18653/v1/2025.acl-long.722. [114] JI J, WANG K, QIU T A, et al. Language models resist alignment: Evidence from data compression[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025:23411-23432. [115] CHANGALIDIS A, HÄRMÄ A. Capacity matters: a proof-of-concept for transformer memorization on real-world data[C/OL]//JIA R, WALLACE E, HUANG Y, et al. Proceedings of the First Workshop on Large Language Model Memorization (L2M2). Vienna, Austria: Association for Computational Linguistics, 2025: 227-238. https://aclanthology.org/2025.l2m2-1.17/. DOI: 10.18653/v1/2025.l2m2-1.17. [116] MORRIS J X, SITAWARIN C, GUO C, et al. How much do language models memorize: abs/2505.24832[A/OL]. 2025. https://api.semanticscholar.org/CorpusID:279070758. [117] TISHBY N, ZASLAVSKY N. Deep learning and the information bottleneck principle[J/OL]. 2015 IEEE Information Theory Workshop (ITW), 2015: 1-5. https://api.semanticscholar.org/CorpusID:5541663. [118] LI H, DING L, FANG M, et al. Revisiting catastrophic forgetting in large language model tuning[A]. 2024. [119] LIN Y, LIN H, XIONG W, et al. Mitigating the alignment tax of rlhf[C]//Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024: 580-606. [120] ZHOU C, CAO P, LI J, et al. Scaling laws for task-stratified knowledge in post-training quantized large language models: abs/2508.18609[A/OL]. 2025. https://api.semanticscholar.org/CorpusID:280869868. [121] WELLER O, BORATKO M, NAIM I, et al. On the theoretical limitations of embedding-based retrieval[A]. 2025. [122] LIN Y, LIN H, XIONG W, et al. Mitigating the alignment tax of rlhf[C]//Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024: 580-606. [123] SHI D, JIN R, SHEN T, et al. Ircan: Mitigating knowledge conflicts in llm generation via identifying and reweighting context-aware neurons[J]. Advances in Neural Information Processing Systems, 2024, 37: 4997-5024. [124] JIN Z, CAO P, YUAN H, et al. Cutting off the head ends the conflict: A mechanism for interpreting and mitigating knowledge conflicts in language models[A]. 2024. [125] GOYAL S, BAEK C, KOLTER J Z, et al. Context-parametric inversion: Why instruction finetuning can worsen context reliance[A]. 2024. [126] HU E J, SHEN Y, WALLIS P, et al. Lora: Low-rank adaptation of large language models.[J]. ICLR, 2022, 1(2): 3. [127] CHANGALIDIS A, HÄRMÄ A. Capacity matters: a proof-of-concept for transformer memorization on real-world data[A]. 2025. [128] MORRIS J X, SITAWARIN C, GUO C, et al. How much do language models memorize?[A]. 2025. [129] DRAXLER F, VESCHGINI K, SALMHOFER M, et al. Essentially no barriers in neural network energy landscape [C]//International conference on machine learning. PMLR, 2018: 1309-1318. [130] XU Y, LI X C, LI L, et al. Visualizing, rethinking, and mining the loss landscape of deep neural networks[A]. 2024. [131] KABIR S, ESTERLING K, DONG Y. Beyond the surface: Probing the ideological depth of large language models [A]. 2025. [132] DARM P, RICCARDI A. Hsi: Head-specific intervention can induce misaligned ai coordination in large language models[A]. 2025. [133] LI J, KIM J E. Superficial safety alignment hypothesis[A]. 2024. [134] JIANG Y, HUANG J, YUAN Y, et al. Risk-sensitive rl for alleviating exploration dilemmas in large language models[A]. 2025. [135] SAHOO P, SINGH A K, SAHA S, et al. A systematic survey of prompt engineering in large language models: Techniques and applications[A]. 2024. [136] GAO M, LU T, YU K, et al. Insights into llm long-context failures: when transformers know but don’t tell[C]// Findings of the Association for Computational Linguistics: EMNLP 2024. 2024: 7611-7625. [137] CHENG J, LU Y, GU X, et al. Autodetect: Towards a unified framework for automated weakness detection in large language models[A]. 2024. [138] AGRAWAL A, ALAZRAKI L, HONARVAR S, et al. Enhancing llm robustness to perturbed instructions: An empirical study[A]. 2025. [139] FIGUEIREDO V. Fuzzy, Symbolic, and Contextual: Enhancing LLM Instruction via Cognitive Scaffolding[A]. 2025. [140] WU M, LIU Z, YAN Y, et al. RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts[A]. 2025. [141] YAO S, YU D, ZHAO J, et al. Tree of thoughts: Deliberate problem solving with large language models[J]. Advances in neural information processing systems, 2023, 36: 11809-11822. [142] TRIVEDI H, BALASUBRAMANIAN N, KHOT T, et al. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions[C]//Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 2023: 10014-10037. [143] TURPIN M, MICHAEL J, PEREZ E, et al. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting[J]. Advances in Neural Information Processing Systems, 2023, 36:74952-74965. [144] SIVAPRASAD S, KAUSHIK P, ABDELNABI S, et al. A theory of response sampling in llms: Part descriptive and part prescriptive[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics(Volume 1: Long Papers). 2025: 30091-30135. [145] ZHANG B, LIU Y, DONG X, et al. Booststep: Boosting mathematical capability of large language models via improved single-step reasoning[A]. 2025. [146] PEEPERKORN M, KOUWENHOVEN T, BROWN D, et al. Is temperature the creativity parameter of largelanguage models?[A]. 2024. [147] HE Y, LI S, LIU J, et al. Can large language models detect errors in long chain-of-thought reasoning?[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).2025: 18468-18489. [148] YOU W, XUE A, HAVALDAR S, et al. Probabilistic soundness guarantees in llm reasoning chains[C]//Proceedingsof the 2025 Conference on Empirical Methods in Natural Language Processing. 2025: 7517-7536. [149] BANERJEE D, SURESH T, UGARE S, et al. Crane: Reasoning with constrained llm generation[A]. 2025. [150] DU J, HOU G, FU Y, et al. Active Confusion Expression in Large Language Models: Leveraging World Modelstoward Better Social Reasoning[A]. 2025. [151] PATHER K, HADJIGEORGIOU E, KRASNIQI A, et al. Vis-CoT: A Human-in-the-Loop Framework for InteractiveVisualization and Intervention in LLM Chain-of-Thought Reasoning[A]. 2025. [152] WANG X, WEI J, SCHUURMANS D, et al. Self-consistency improves chain of thought reasoning in languagemodels[A]. 2022. [153] KNAPPE T, LI R, CHAUHAN A, et al. Enhancing Language Model Reasoning via Weighted Reasoning in Self-Consistency[A]. 2024: arXiv-2410.
编辑:李启明初审:张 羽复审:冯骁骋终审:单既阳
哈尔滨工业大学社会计算与交互机器人研究中心
理解语言,认知社会 以中文技术,助民族复兴
