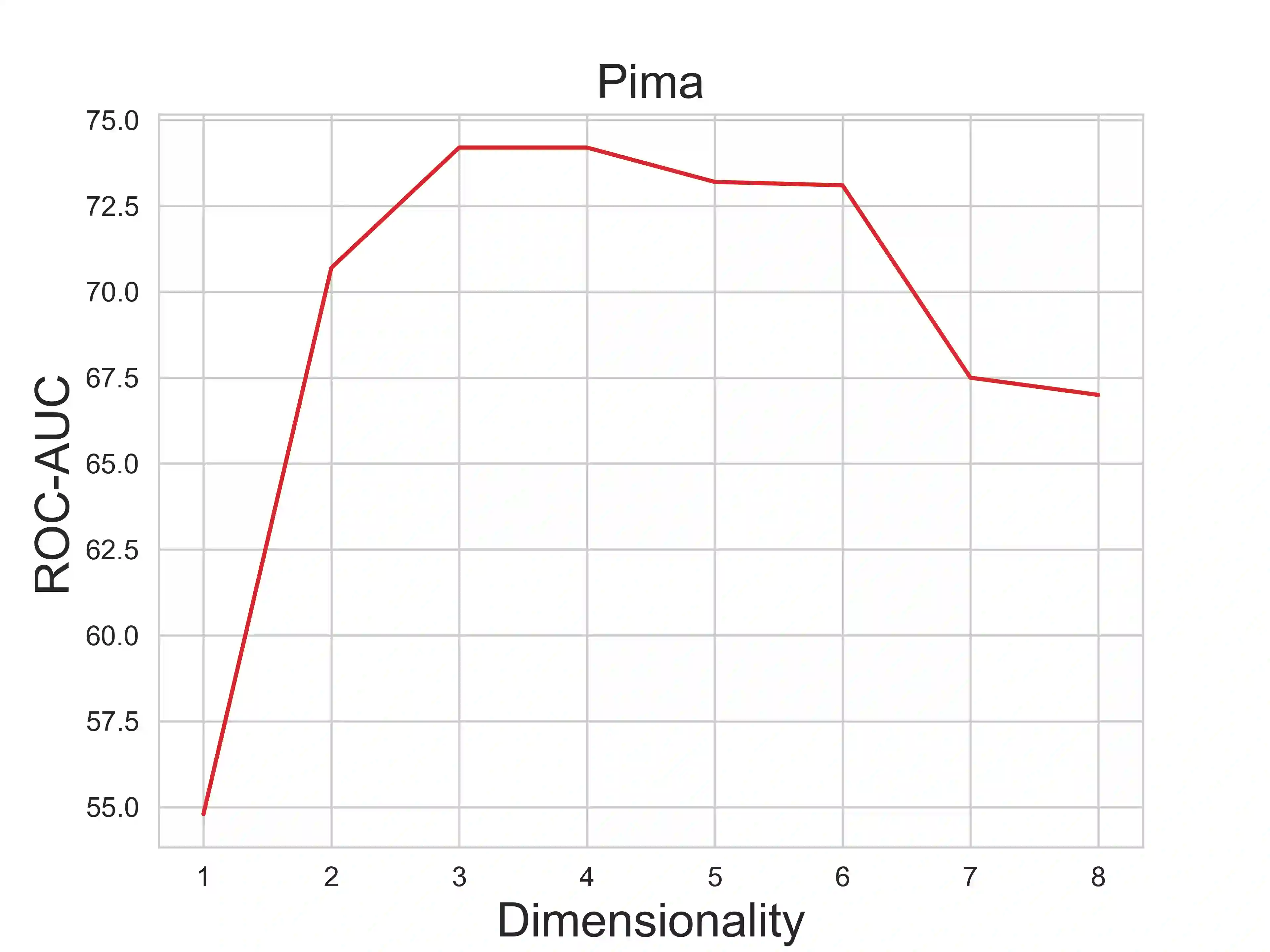
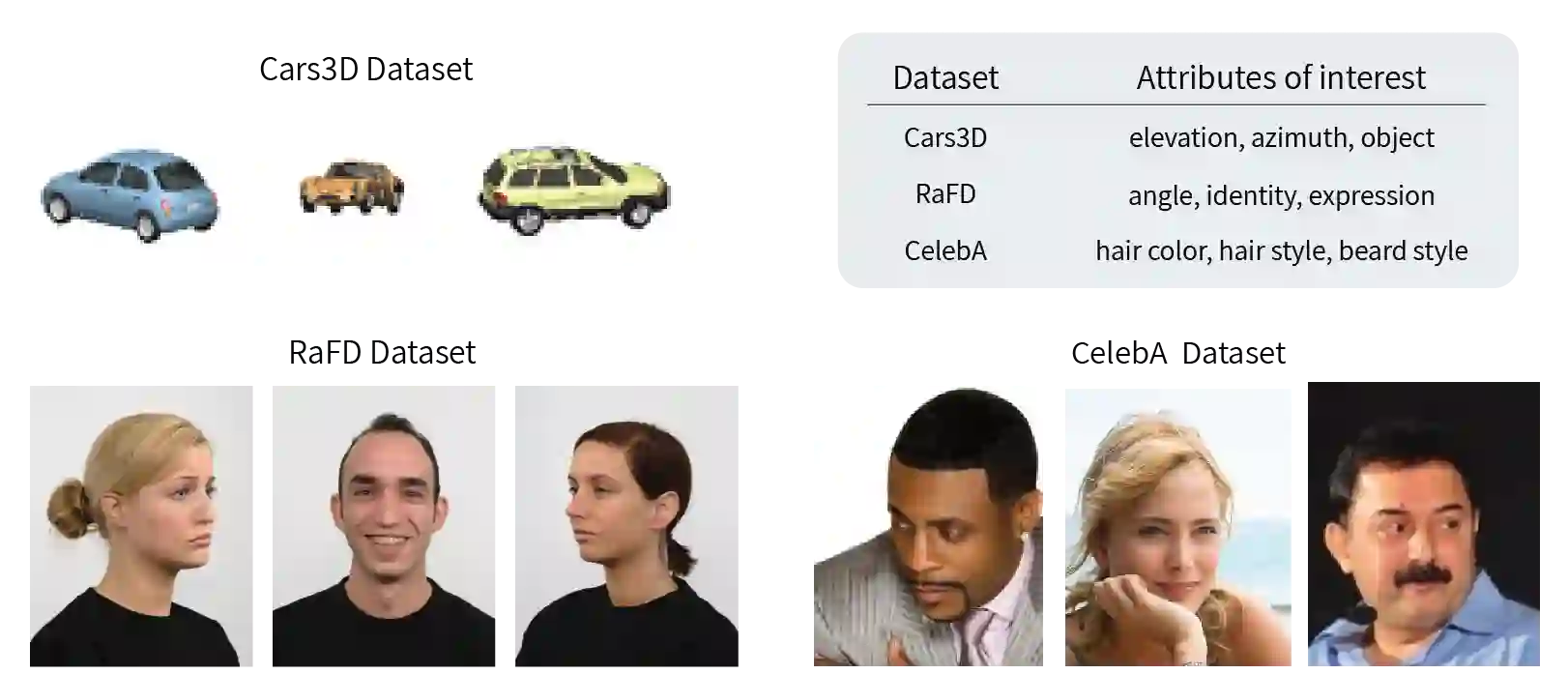
Anomaly detection methods, powered by deep learning, have recently been making significant progress, mostly due to improved representations. It is tempting to hypothesize that anomaly detection can improve indefinitely by increasing the scale of our networks, making their representations more expressive. In this paper, we provide theoretical and empirical evidence to the contrary. In fact, we empirically show cases where very expressive representations fail to detect even simple anomalies when evaluated beyond the well-studied object-centric datasets. To investigate this phenomenon, we begin by introducing a novel theoretical toy model for anomaly detection performance. The model uncovers a fundamental trade-off between representation sufficiency and over-expressivity. It provides evidence for a no-free-lunch theorem in anomaly detection stating that increasing representation expressivity will eventually result in performance degradation. Instead, guidance must be provided to focus the representation on the attributes relevant to the anomalies of interest. We conduct an extensive empirical investigation demonstrating that state-of-the-art representations often suffer from over-expressivity, failing to detect many types of anomalies. Our investigation demonstrates how this over-expressivity impairs image anomaly detection in practical settings. We conclude with future directions for mitigating this issue.
翻译:基于深度学习的异常检测方法近年来取得了显著进展,这主要归功于表示能力的提升。人们容易假设,通过扩大网络规模、增强表示的表达能力,异常检测性能可以无限提高。本文从理论和实验两方面证明了相反结论。事实上,我们通过实验展示了当评估超出常见目标中心数据集时,即使非常具有表达力的表示也无法检测到简单异常案例。为探究这一现象,我们首先提出一个新颖的理论性玩具模型来描述异常检测性能。该模型揭示了表示充分性与过度表达性之间的根本权衡,为异常检测中的"没有免费午餐"定理提供了证据:提高表示表达能力最终会导致性能退化。因此,必须对表示进行引导,使其聚焦于与目标异常相关的属性。我们开展了广泛的实验研究,证明当前最先进的表示常因过度表达性而无法检测多种类型的异常。研究表明,这种过度表达性会损害实际场景中的图像异常检测。最后,我们提出了缓解该问题的未来研究方向。