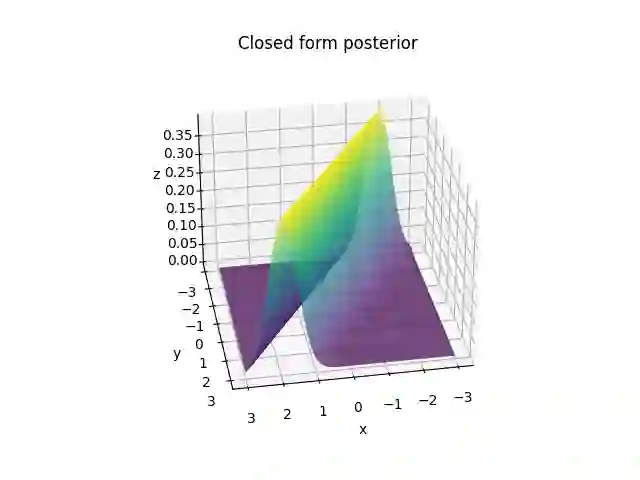
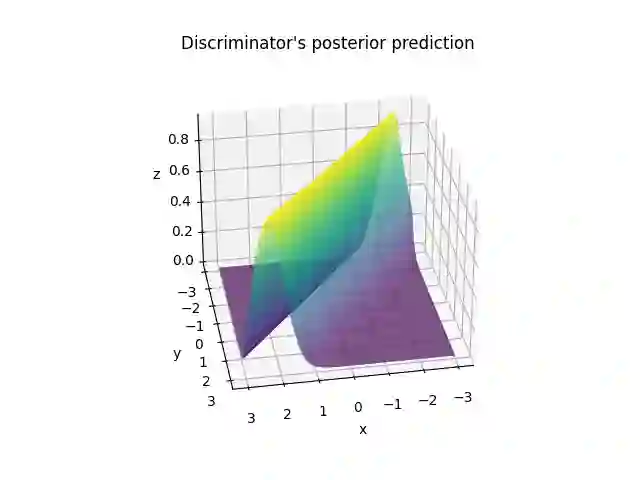
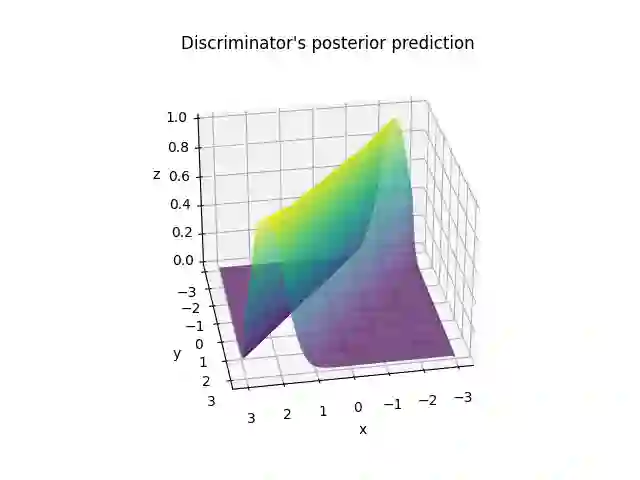
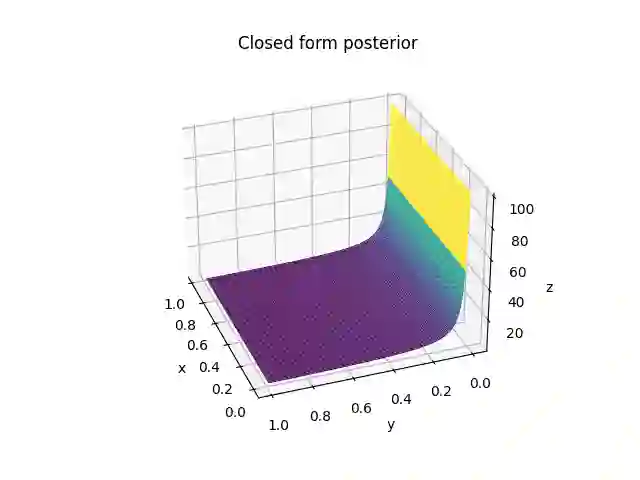
In deep learning, classification tasks are formalized as optimization problems solved via the minimization of the cross-entropy. However, recent advancements in the design of objective functions allow the $f$-divergence measure to generalize the formulation of the optimization problem for classification. With this goal in mind, we adopt a Bayesian perspective and formulate the classification task as a maximum a posteriori probability problem. We propose a class of objective functions based on the variational representation of the $f$-divergence, from which we extract a list of five posterior probability estimators leveraging well-known $f$-divergences. In addition, driven by the challenge of improving the state-of-the-art approach, we propose a bottom-up method that leads us to the formulation of a new objective function (and posterior probability estimator) corresponding to a novel $f$-divergence referred to as shifted log (SL). First, we theoretically prove the convergence property of the posterior probability estimators. Then, we numerically test the set of proposed objective functions in three application scenarios: toy examples, image data sets, and signal detection/decoding problems. The analyzed tasks demonstrate the effectiveness of the proposed estimators and that the SL divergence achieves the highest classification accuracy in almost all the scenarios.
翻译:在深度学习中,分类任务被形式化为通过最小化交叉熵求解的优化问题。然而,目标函数设计的最新进展使得$f$散度度量能够推广分类优化问题的表述。基于此目标,我们采用贝叶斯视角,将分类任务表述为最大后验概率问题。我们提出了一类基于$f$散度变分表示的目标函数,并从中提取出五种利用经典$f$散度的后验概率估计器。此外,受改进现有最佳方法这一挑战的驱动,我们提出了一种自底向上的方法,该方法引导我们构建了一个新的目标函数(及后验概率估计器),对应一种被称为移位对数(SL)的新型$f$散度。首先,我们从理论上证明了后验概率估计器的收敛性质。随后,我们在三种应用场景中对所提出的目标函数集进行了数值测试:示例数据、图像数据集以及信号检测/解码问题。分析任务表明,所提出的估计器具有有效性,且SL散度在几乎所有场景中均实现了最高的分类准确率。