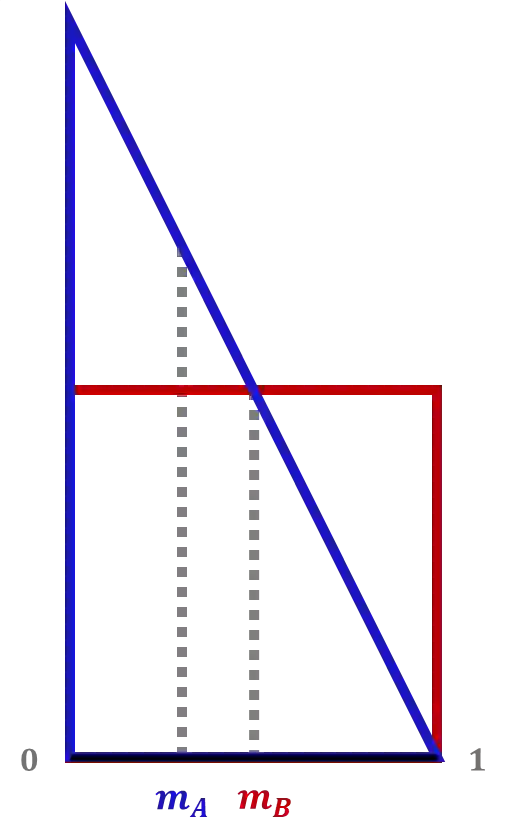
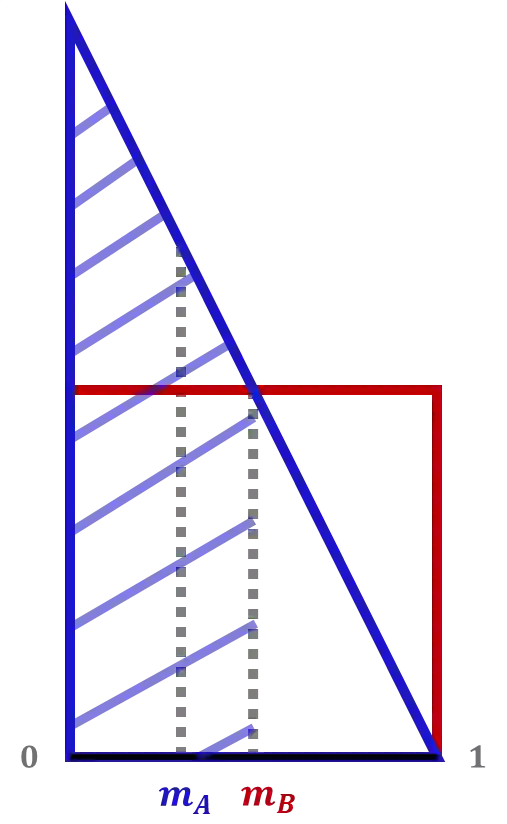
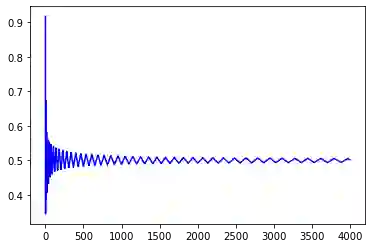
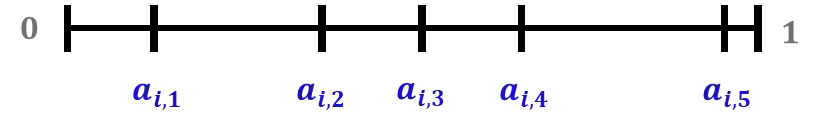We consider the setting of repeated fair division between two players, denoted Alice and Bob, with private valuations over a cake. In each round, a new cake arrives, which is identical to the ones in previous rounds. Alice cuts the cake at a point of her choice, while Bob chooses the left piece or the right piece, leaving the remainder for Alice. We consider two versions: sequential, where Bob observes Alice's cut point before choosing left/right, and simultaneous, where he only observes her cut point after making his choice. The simultaneous version was first considered by Aumann and Maschler (1995). We observe that if Bob is almost myopic and chooses his favorite piece too often, then he can be systematically exploited by Alice through a strategy akin to a binary search. This strategy allows Alice to approximate Bob's preferences with increasing precision, thereby securing a disproportionate share of the resource over time. We analyze the limits of how much a player can exploit the other one and show that fair utility profiles are in fact achievable. Specifically, the players can enforce the equitable utility profile of $(1/2, 1/2)$ in the limit on every trajectory of play, by keeping the other player's utility to approximately $1/2$ on average while guaranteeing they themselves get at least approximately $1/2$ on average. We show this theorem using a connection with Blackwell approachability. Finally, we analyze a natural dynamic known as fictitious play, where players best respond to the empirical distribution of the other player. We show that fictitious play converges to the equitable utility profile of $(1/2, 1/2)$ at a rate of $O(1/\sqrt{T})$.
翻译:我们考虑两名玩家(记为Alice和Bob)在私人估值下对蛋糕进行重复公平分配的场景。每轮中,会出现一块与之前轮次相同的新蛋糕。Alice选择切点分割蛋糕,而Bob选择左块或右块,剩余部分归Alice。我们考虑两种版本:顺序版本中,Bob在观察Alice切点后选择左右;同时版本中,Bob仅在选择后观察切点。同时版本最初由Aumann和Maschler(1995)提出。我们观察到,如果Bob近乎短视且过于频繁选择偏好块,则Alice可通过类似二分搜索的策略系统性利用Bob。该策略使Alice以递增精度逼近Bob的偏好,从而随时间获取不成比例的资源份额。我们分析玩家可相互利用的极限,证明公平效用分布实际上是可以实现的。具体而言,玩家可通过将对方平均效用约束在约1/2并确保自身平均效用至少约1/2,在每条博弈轨迹的极限上强制执行(1/2, 1/2)的公平效用分布。我们利用与布莱克韦尔可逼近性(Blackwell approachability)的联系证明该定理。最后,我们分析一种称为虚拟博弈(fictitious play)的自然动态过程,其中玩家对对方的经验分布做出最优反应。我们证明虚拟博弈以O(1/√T)的速率收敛到(1/2, 1/2)的公平效用分布。