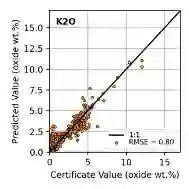
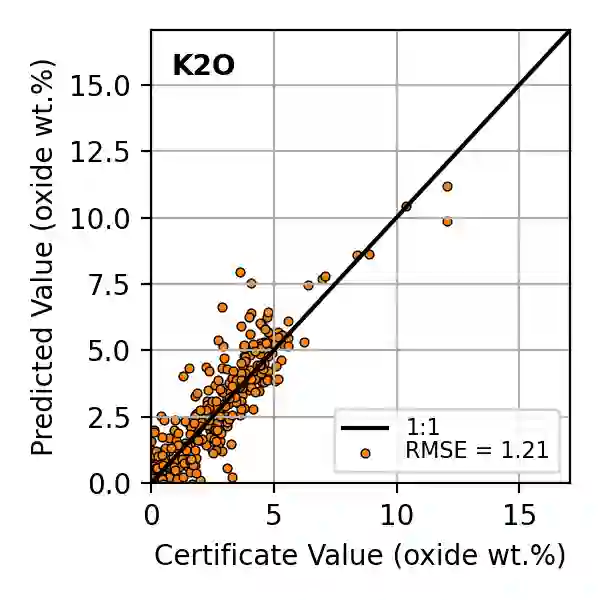
In this work, we propose the use of a causal collider structured model to describe the underlying data generative process assumptions in disentangled representation learning. This extends the conventional i.i.d. factorization assumption model $p(\mathbf{y}) = \prod_{i} p(\mathbf{y}_i )$, inadequate to handle learning from biased datasets (e.g., with sampling selection bias). The collider structure, explains that conditional dependencies between the underlying generating variables may be exist, even when these are in reality unrelated, complicating disentanglement. Under the rubric of causal inference, we show this issue can be reconciled under the condition of causal identification; attainable from data and a combination of constraints, aimed at controlling the dependencies characteristic of the \textit{collider} model. For this, we propose regularization by identification (ReI), a modular regularization engine designed to align the behavior of large scale generative models with the disentanglement constraints imposed by causal identification. Empirical evidence on standard benchmarks demonstrates the superiority of ReI in learning disentangled representations in a variational framework. In a real-world dataset we additionally show that our framework, results in interpretable representations robust to out-of-distribution examples and that align with the true expected effect from domain knowledge.
翻译:本文提出使用因果碰撞器结构模型来描述解耦表示学习中的底层数据生成过程假设。这扩展了传统独立同分布因子化假设模型 $p(\mathbf{y}) = \prod_{i} p(\mathbf{y}_i )$,该模型无法处理从偏态数据集(例如存在采样选择偏差)中学习的问题。碰撞器结构揭示,即使底层生成变量在现实中互不相关,它们之间仍可能存在条件依赖关系,从而增加解耦难度。在因果推断框架下,我们证明该问题可在因果辨识条件下得到解决;该条件可通过数据与旨在控制碰撞器模型依赖特性的约束组合实现。为此,我们提出辨识正则化(ReI),这是一种模块化正则化引擎,旨在使大规模生成模型的行为与因果辨识施加的解耦约束保持一致。标准基准实验的实证结果表明,ReI在变分框架下学习解耦表示方面具有优越性。在真实世界数据集上,我们进一步证明该框架能够产生对外部样本鲁棒且符合领域知识真实预期效应的可解释表示。