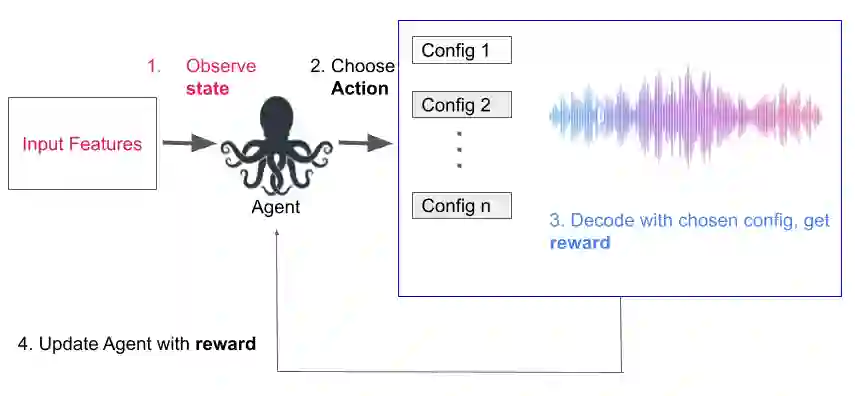
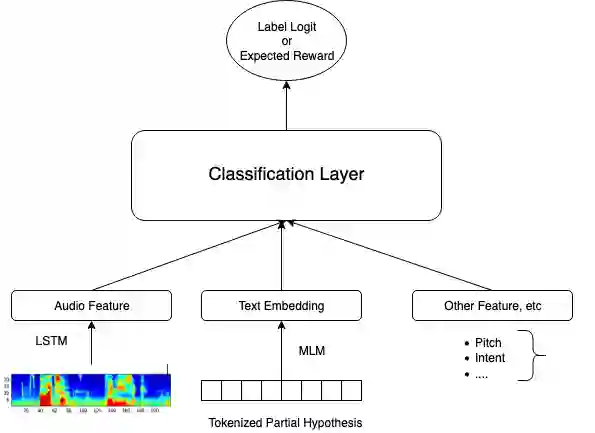
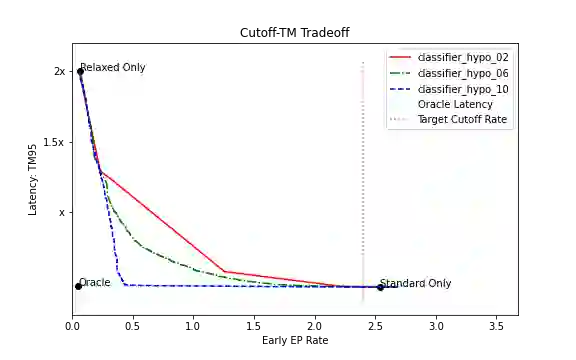
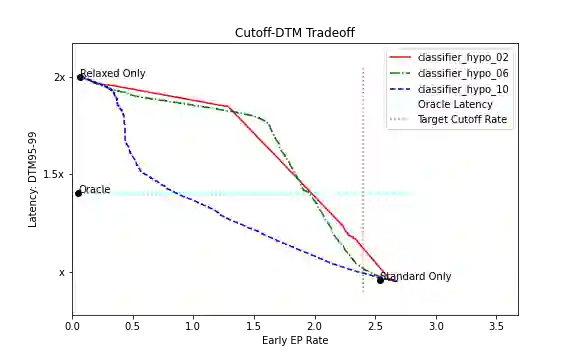
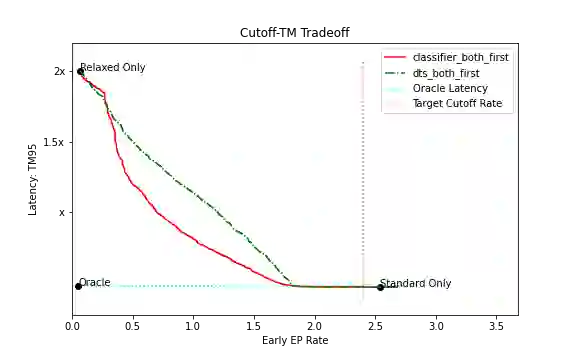
Current endpointing (EP) solutions learn in a supervised framework, which does not allow the model to incorporate feedback and improve in an online setting. Also, it is a common practice to utilize costly grid-search to find the best configuration for an endpointing model. In this paper, we aim to provide a solution for adaptive endpointing by proposing an efficient method for choosing an optimal endpointing configuration given utterance-level audio features in an online setting, while avoiding hyperparameter grid-search. Our method does not require ground truth labels, and only uses online learning from reward signals without requiring annotated labels. Specifically, we propose a deep contextual multi-armed bandit-based approach, which combines the representational power of neural networks with the action exploration behavior of Thompson modeling algorithms. We compare our approach to several baselines, and show that our deep bandit models also succeed in reducing early cutoff errors while maintaining low latency.
翻译:当前的端点检测解决方案在监督框架下进行学习,这无法让模型在在线环境中融入反馈并持续改进。此外,常见做法是使用成本高昂的网格搜索来寻找端点检测模型的最佳配置。本文旨在提出一种自适应端点检测的解决方案,通过一种高效方法,在在线环境中根据话语级音频特征选择最优端点检测配置,同时避免超参数网格搜索。该方法无需真实标签,仅通过在线学习奖励信号即可实现,无需人工标注。具体而言,我们提出了一种基于深度上下文多臂老虎机的方法,该方法结合了神经网络的表征能力与汤普森建模算法的动作探索行为。我们将所提方法与多个基线进行了对比,结果表明,深度老虎机模型在保持低延迟的同时,成功减少了早期截断错误。