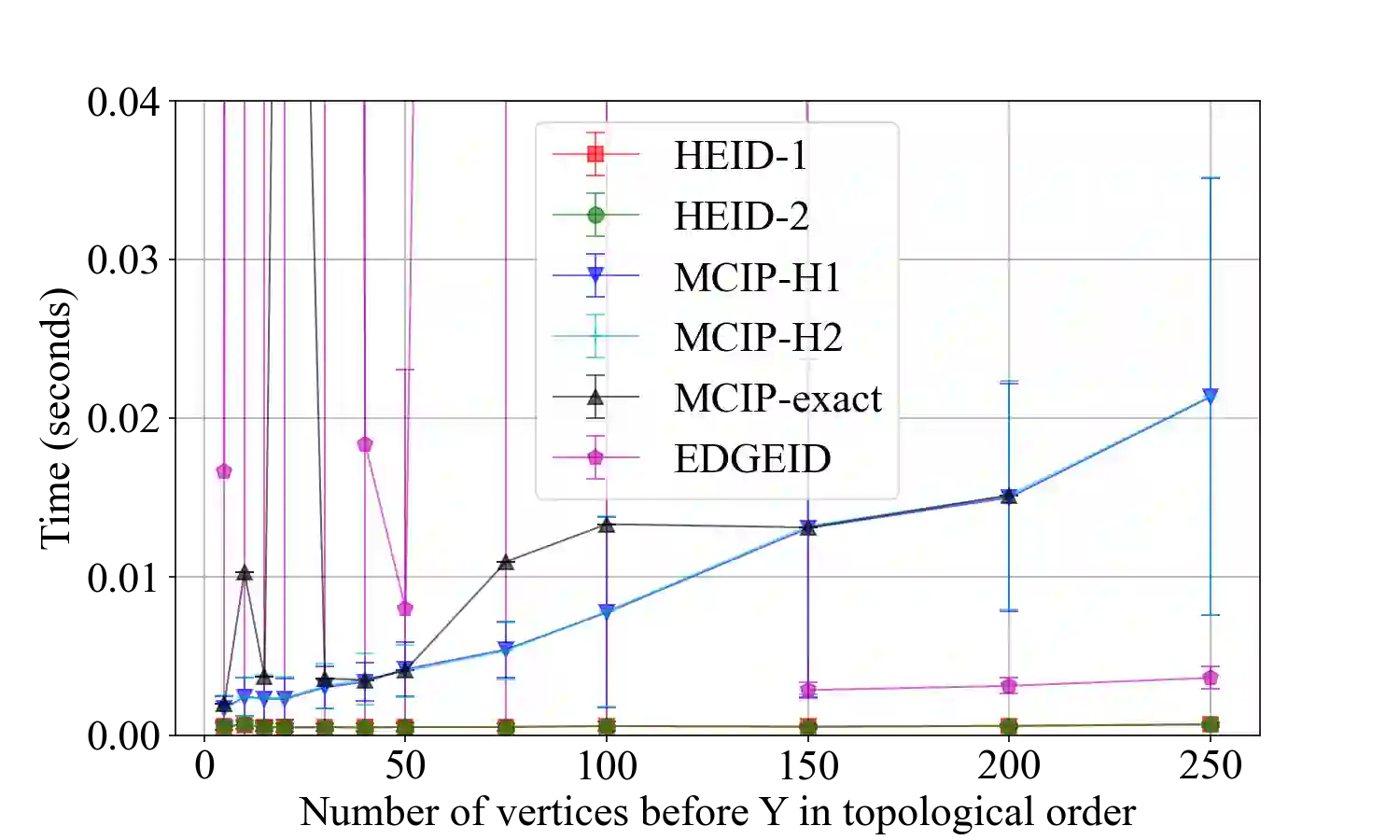
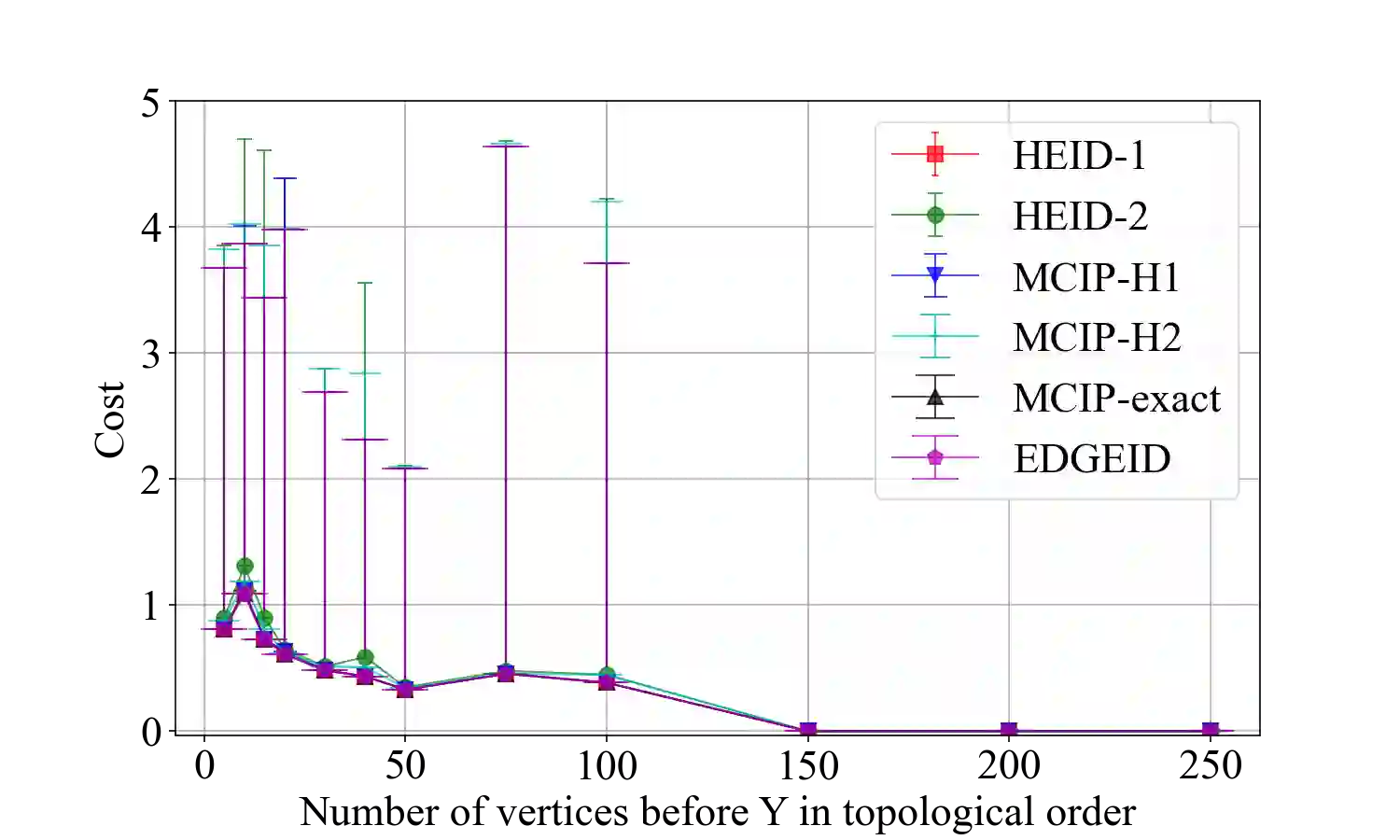
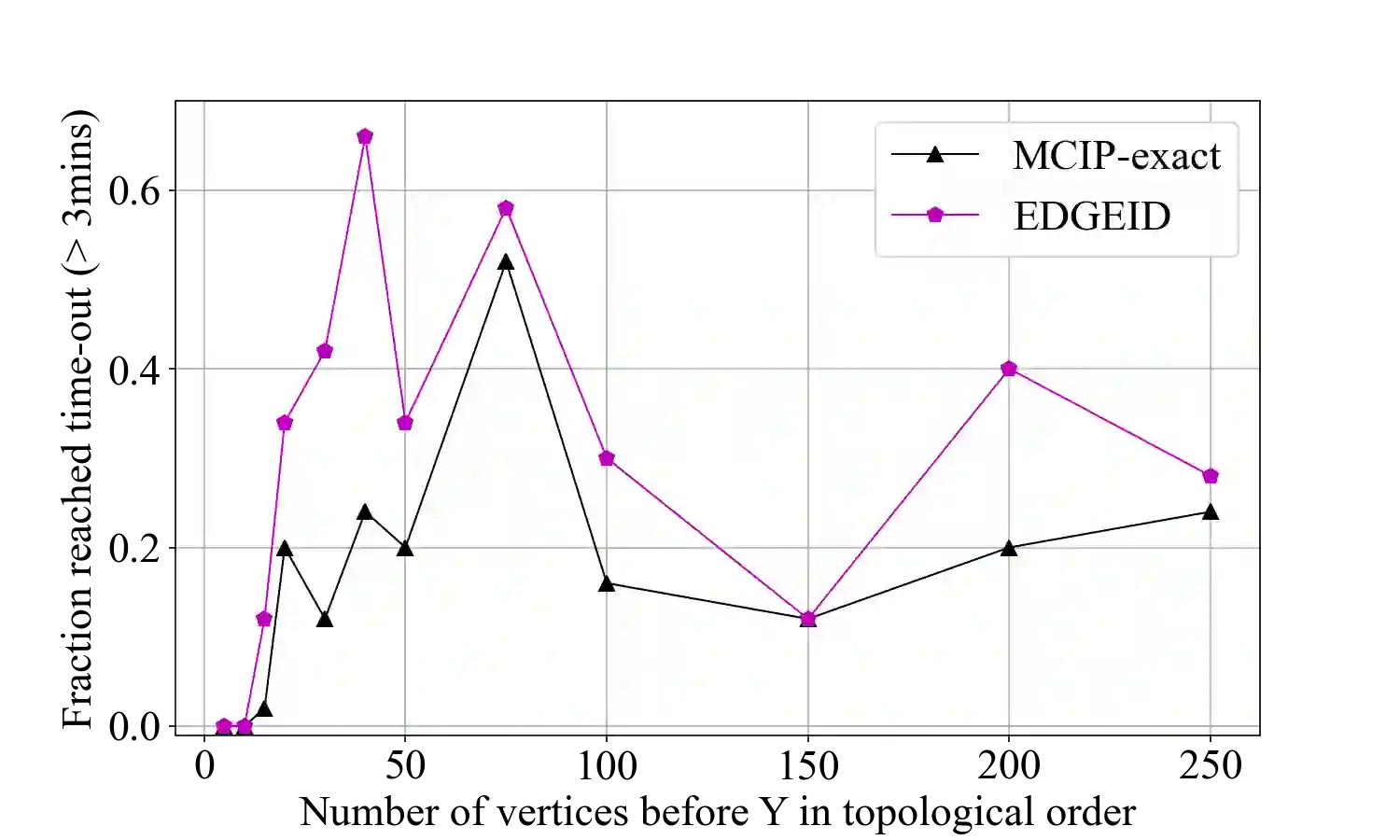
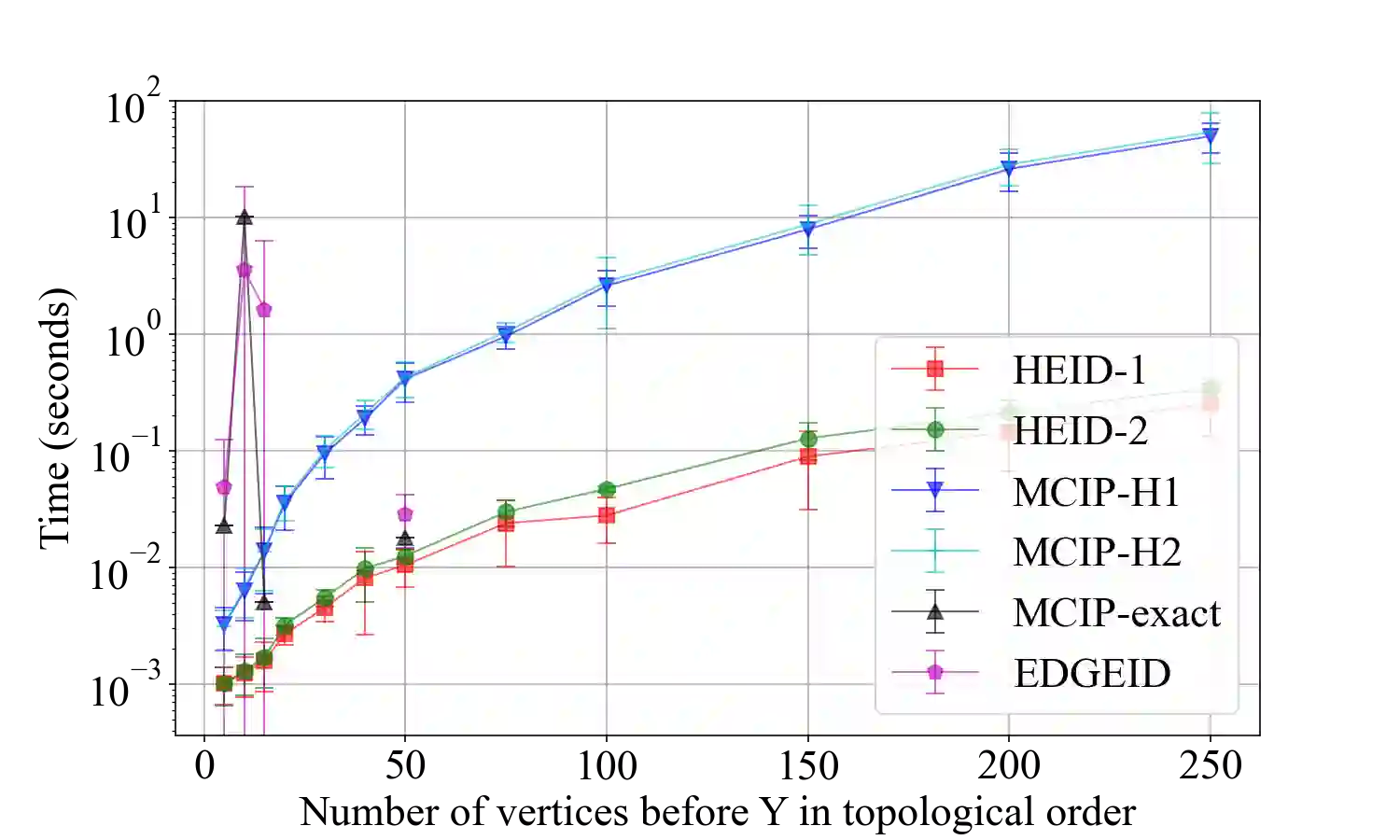
Causal identification is at the core of the causal inference literature, where complete algorithms have been proposed to identify causal queries of interest. The validity of these algorithms hinges on the restrictive assumption of having access to a correctly specified causal structure. In this work, we study the setting where a probabilistic model of the causal structure is available. Specifically, the edges in a causal graph exist with uncertainties which may, for example, represent degree of belief from domain experts. Alternatively, the uncertainty about an edge may reflect the confidence of a particular statistical test. The question that naturally arises in this setting is: Given such a probabilistic graph and a specific causal effect of interest, what is the subgraph which has the highest plausibility and for which the causal effect is identifiable? We show that answering this question reduces to solving an NP-complete combinatorial optimization problem which we call the edge ID problem. We propose efficient algorithms to approximate this problem and evaluate them against both real-world networks and randomly generated graphs.
翻译:因果识别是因果推断文献的核心,已有完整算法被提出用于识别感兴趣的因果查询。这些算法的有效性依赖于一个限制性假设,即能够获得正确指定的因果结构。在本研究中,我们探讨了因果结构概率模型可用的场景。具体而言,因果图中的边以不确定性存在,这种不确定性可能代表领域专家的信念程度,也可能反映特定统计检验的置信度。在此背景下自然产生的问题是:给定这样一个概率图及特定的因果效应,哪个子图具有最高似然性且其因果效应是可识别的?我们证明,回答该问题可归结为求解一个称为“边ID问题”的NP完全组合优化问题。我们提出了高效算法来近似求解该问题,并在现实网络与随机生成图上对这些算法进行了评估。