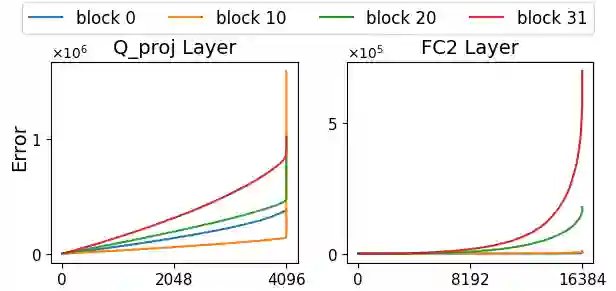
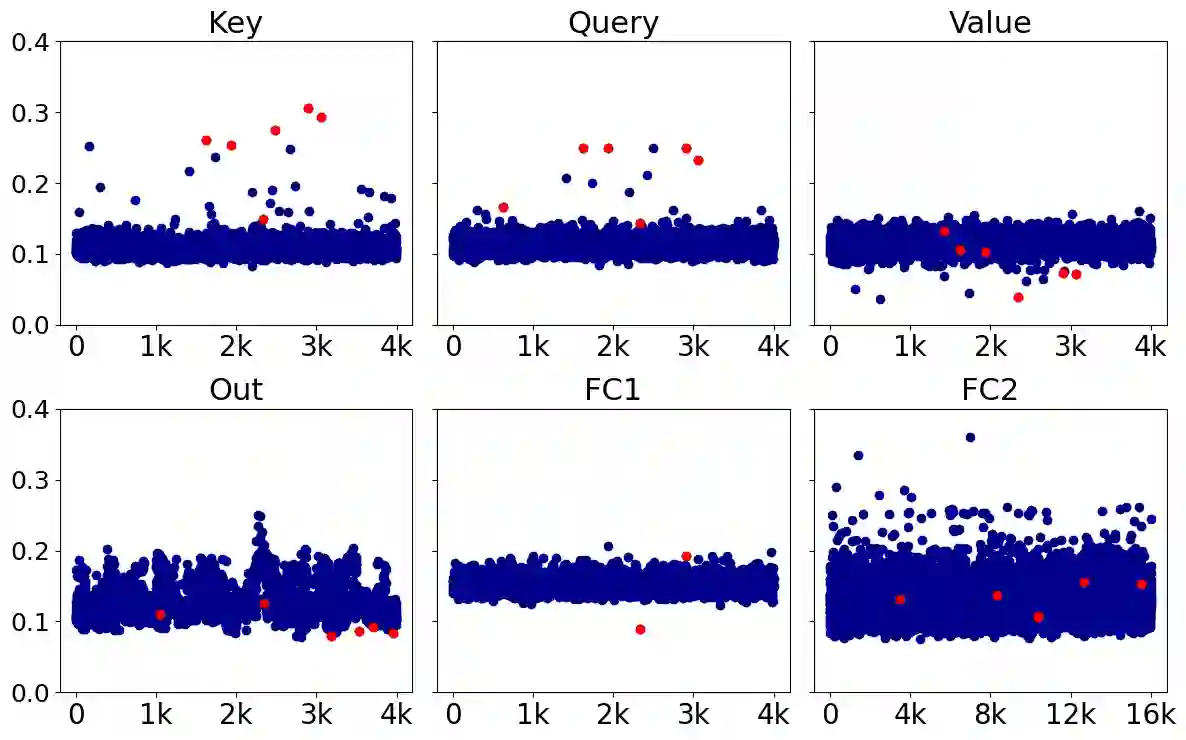
Large language models (LLMs) with hundreds of billions of parameters require powerful server-grade GPUs for inference, limiting their practical deployment. To address this challenge, we introduce the outlier-aware weight quantization (OWQ) method, which aims to minimize LLM's footprint through low-precision representation. OWQ prioritizes a small subset of structured weights sensitive to quantization, storing them in high-precision, while applying highly tuned quantization to the remaining dense weights. This sensitivity-aware mixed-precision scheme reduces the quantization error notably, and extensive experiments demonstrate that 3.1-bit models using OWQ perform comparably to 4-bit models optimized by OPTQ. Furthermore, OWQ incorporates a parameter-efficient fine-tuning for task-specific adaptation, called weak column tuning (WCT), enabling accurate task-specific LLM adaptation with minimal memory overhead in the optimized format. OWQ represents a notable advancement in the flexibility, efficiency, and practicality of LLM optimization literature. The source code is available at https://github.com/xvyaward/owq
翻译:大语言模型(LLMs)拥有数千亿参数,其推理过程需要高性能服务器级GPU支持,严重制约了实际部署。针对这一挑战,我们提出异常感知权重量化(OWQ)方法,旨在通过低精度表示最小化LLM的内存占用。OWQ优先处理对量化敏感的结构化权重子集——将其存储为高精度格式,同时对其余密集权重实施高度调优的量化。这种敏感度感知的混合精度方案显著降低了量化误差,大量实验表明采用OWQ的3.1位模型性能可与经OPTQ优化的4位模型相媲美。此外,OWQ整合了面向任务特定适配的参数高效微调方法——弱列调优(WCT),在优化格式下以最小内存开销实现精准的LLM任务适配。OWQ推动了LLM优化领域在灵活性、效率与实用性方面的显著进步。源代码已开源至https://github.com/xvyaward/owq