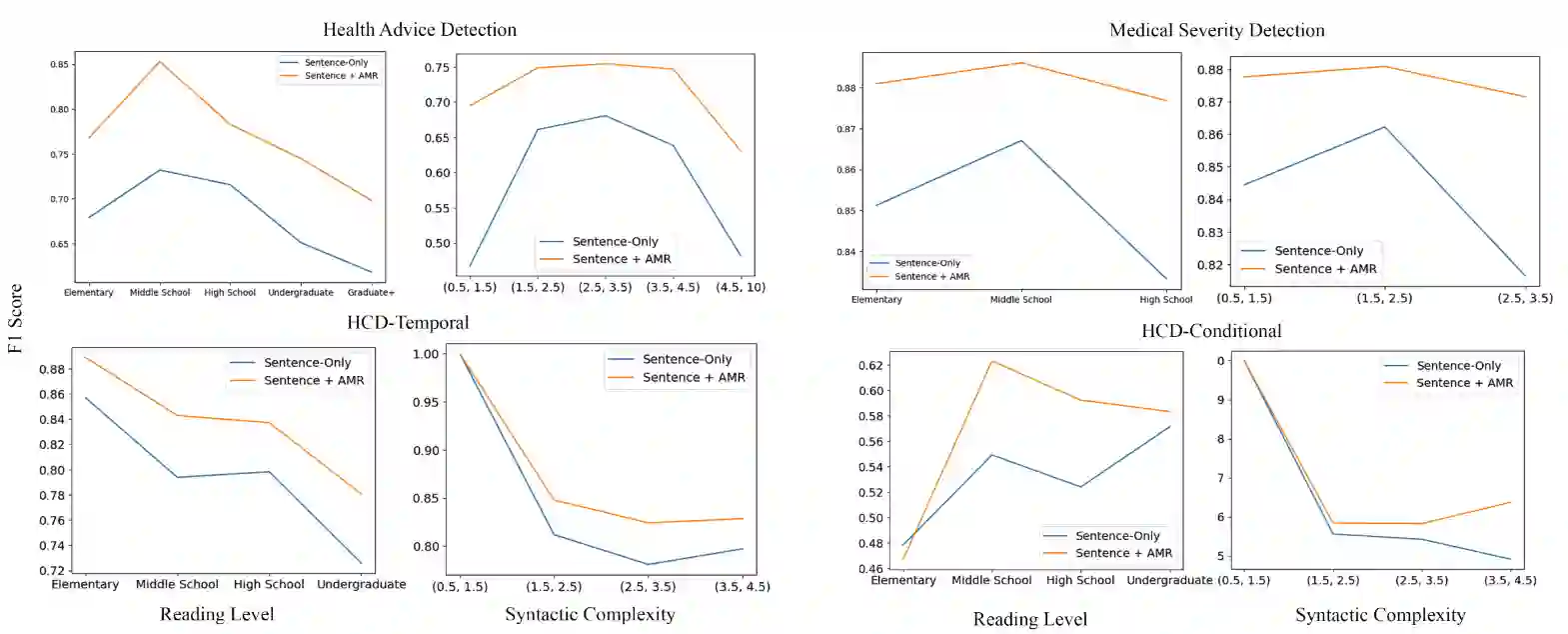
User-generated texts available on the web and social platforms are often long and semantically challenging, making them difficult to annotate. Obtaining human annotation becomes increasingly difficult as problem domains become more specialized. For example, many health NLP problems require domain experts to be a part of the annotation pipeline. Thus, it is crucial that we develop low-resource NLP solutions able to work with this set of limited-data problems. In this study, we employ Abstract Meaning Representation (AMR) graphs as a means to model low-resource Health NLP tasks sourced from various online health resources and communities. AMRs are well suited to model online health texts as they can represent multi-sentence inputs, abstract away from complex terminology, and model long-distance relationships between co-referring tokens. AMRs thus improve the ability of pre-trained language models to reason about high-complexity texts. Our experiments show that we can improve performance on 6 low-resource health NLP tasks by augmenting text embeddings with semantic graph embeddings. Our approach is task agnostic and easy to merge into any standard text classification pipeline. We experimentally validate that AMRs are useful in the modeling of complex texts by analyzing performance through the lens of two textual complexity measures: the Flesch Kincaid Reading Level and Syntactic Complexity. Our error analysis shows that AMR-infused language models perform better on complex texts and generally show less predictive variance in the presence of changing complexity.
翻译:网络及社交平台上的用户生成文本通常冗长且语义复杂,导致标注困难。随着问题领域愈发专业化,获取人工标注的难度日益增加。例如,许多健康领域的自然语言处理问题需要领域专家参与标注流程。因此,开发能够处理这类有限数据问题的低资源NLP解决方案至关重要。本研究采用抽象语义表示图作为建模工具,处理源自各类在线健康资源及社区的低资源健康NLP任务。AMR因能表示多句输入、抽象化复杂术语、建模长距离共指关系,非常适合建模在线健康文本。AMR因此提升了预训练语言模型对高复杂度文本的推理能力。实验表明,通过用语义图嵌入增强文本嵌入,我们可在6项低资源健康NLP任务上提升性能。该方法与任务无关,易于集成至标准文本分类流程。我们通过费莱士金凯德阅读水平与句法复杂度两种文本复杂度指标分析性能,实验验证了AMR在建模复杂文本中的有效性。误差分析显示,融合AMR的语言模型在复杂文本上表现更优,且面对复杂度变化时预测方差更小。