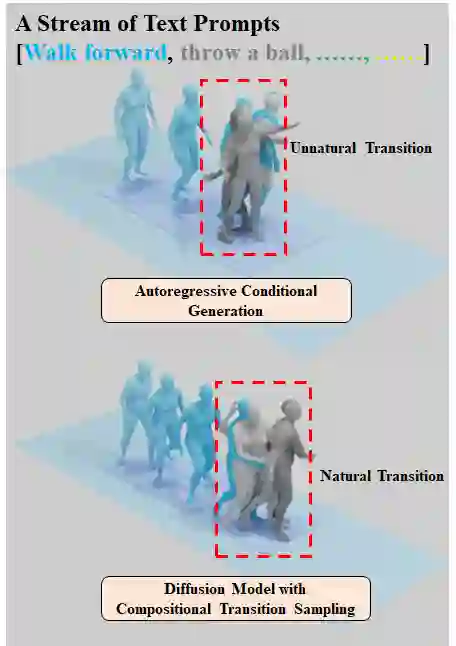
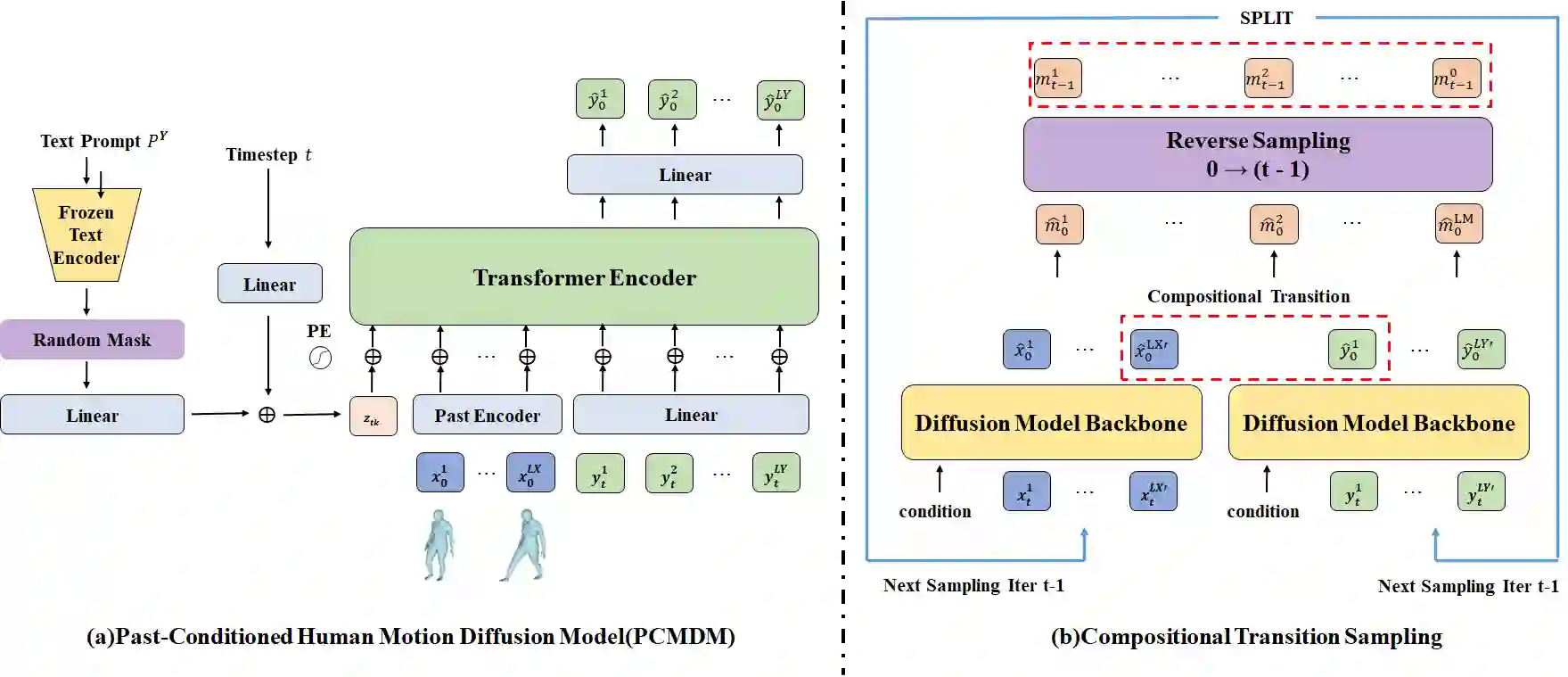
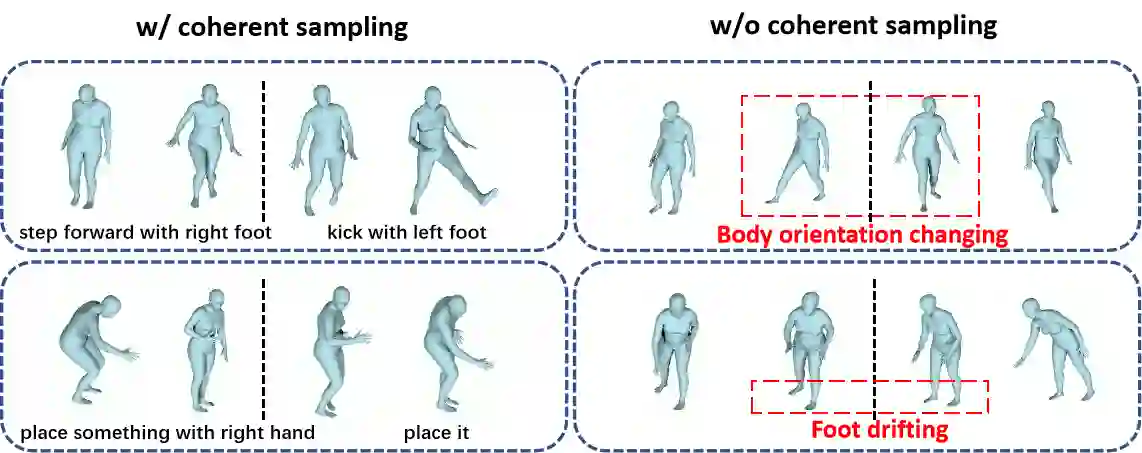
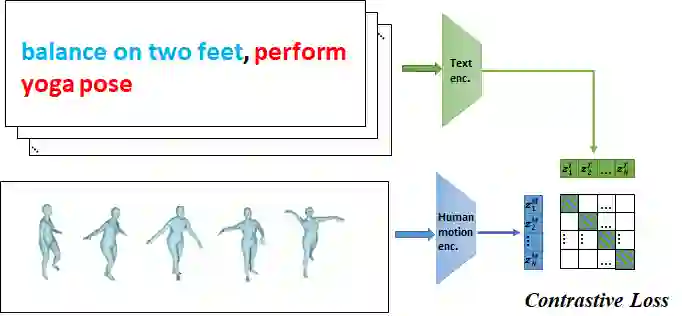
Text-to-motion generation has gained increasing attention, but most existing methods are limited to generating short-term motions that correspond to a single sentence describing a single action. However, when a text stream describes a sequence of continuous motions, the generated motions corresponding to each sentence may not be coherently linked. Existing long-term motion generation methods face two main issues. Firstly, they cannot directly generate coherent motions and require additional operations such as interpolation to process the generated actions. Secondly, they generate subsequent actions in an autoregressive manner without considering the influence of future actions on previous ones. To address these issues, we propose a novel approach that utilizes a past-conditioned diffusion model with two optional coherent sampling methods: Past Inpainting Sampling and Compositional Transition Sampling. Past Inpainting Sampling completes subsequent motions by treating previous motions as conditions, while Compositional Transition Sampling models the distribution of the transition as the composition of two adjacent motions guided by different text prompts. Our experimental results demonstrate that our proposed method is capable of generating compositional and coherent long-term 3D human motions controlled by a user-instructed long text stream. The code is available at \href{https://github.com/yangzhao1230/PCMDM}{https://github.com/yangzhao1230/PCMDM}.
翻译:文本到运动生成技术日益受到关注,但现有方法大多局限于生成对应单句描述单一动作的短时运动。当文本流描述一系列连续运动时,各句对应的生成动作之间难以形成连贯衔接。现有长时运动生成方法面临两大问题:其一,无法直接生成连贯运动,需要插值等额外操作处理生成的动作序列;其二,采用自回归方式生成后续动作,未考虑未来动作对先前动作的影响。针对这些问题,我们提出一种基于历史条件扩散模型的新方法,包含两种可选的连贯采样策略:历史补全采样与组合过渡采样。历史补全采样通过将先前运动作为条件来完成后续运动,而组合过渡采样则将过渡分布建模为受不同文本提示引导的相邻运动的组合。实验结果表明,所提方法能够生成由用户长文本流控制的连贯组合式三维人体长时运动。代码已开源在 \href{https://github.com/yangzhao1230/PCMDM}{https://github.com/yangzhao1230/PCMDM}。