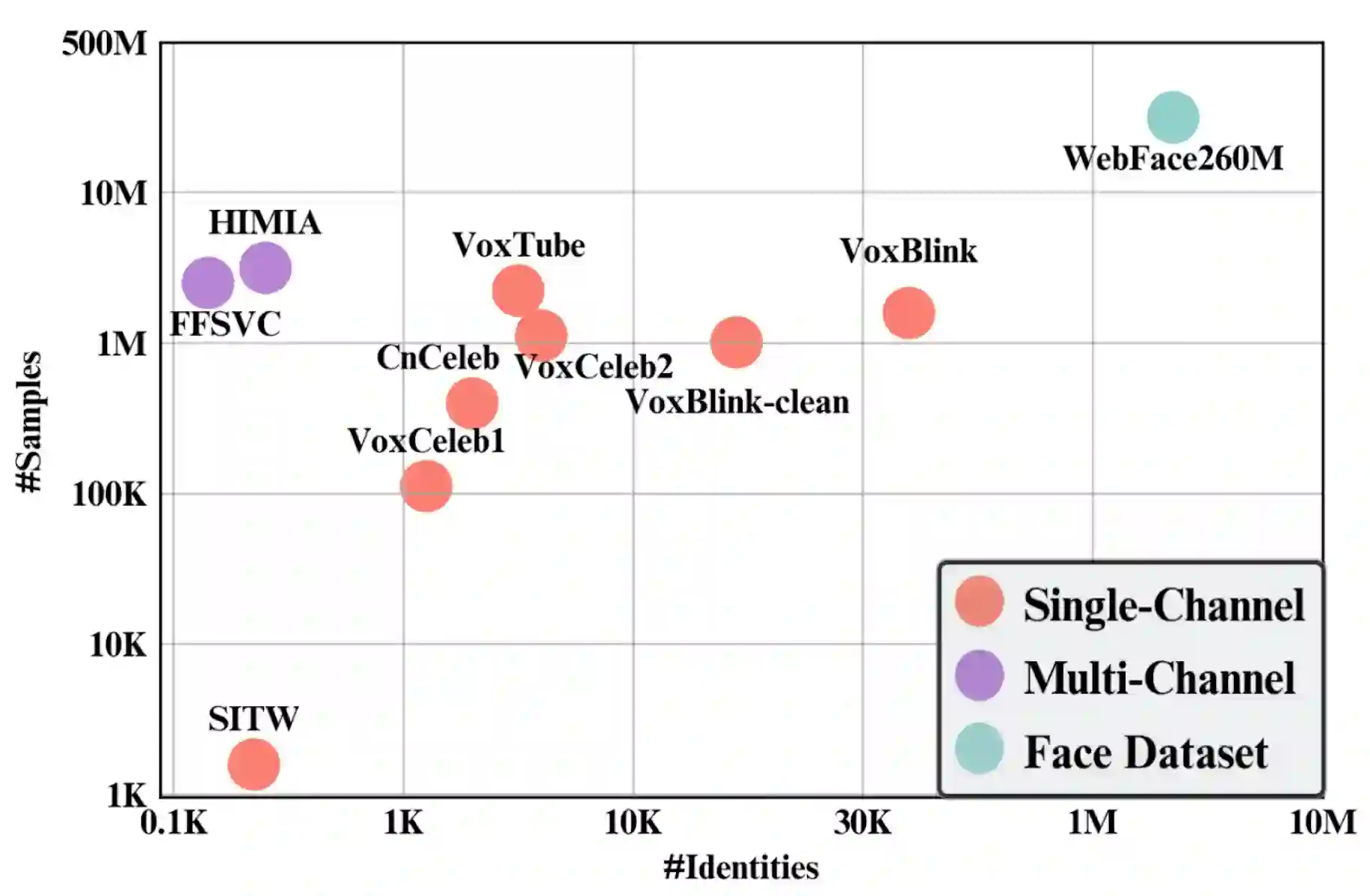
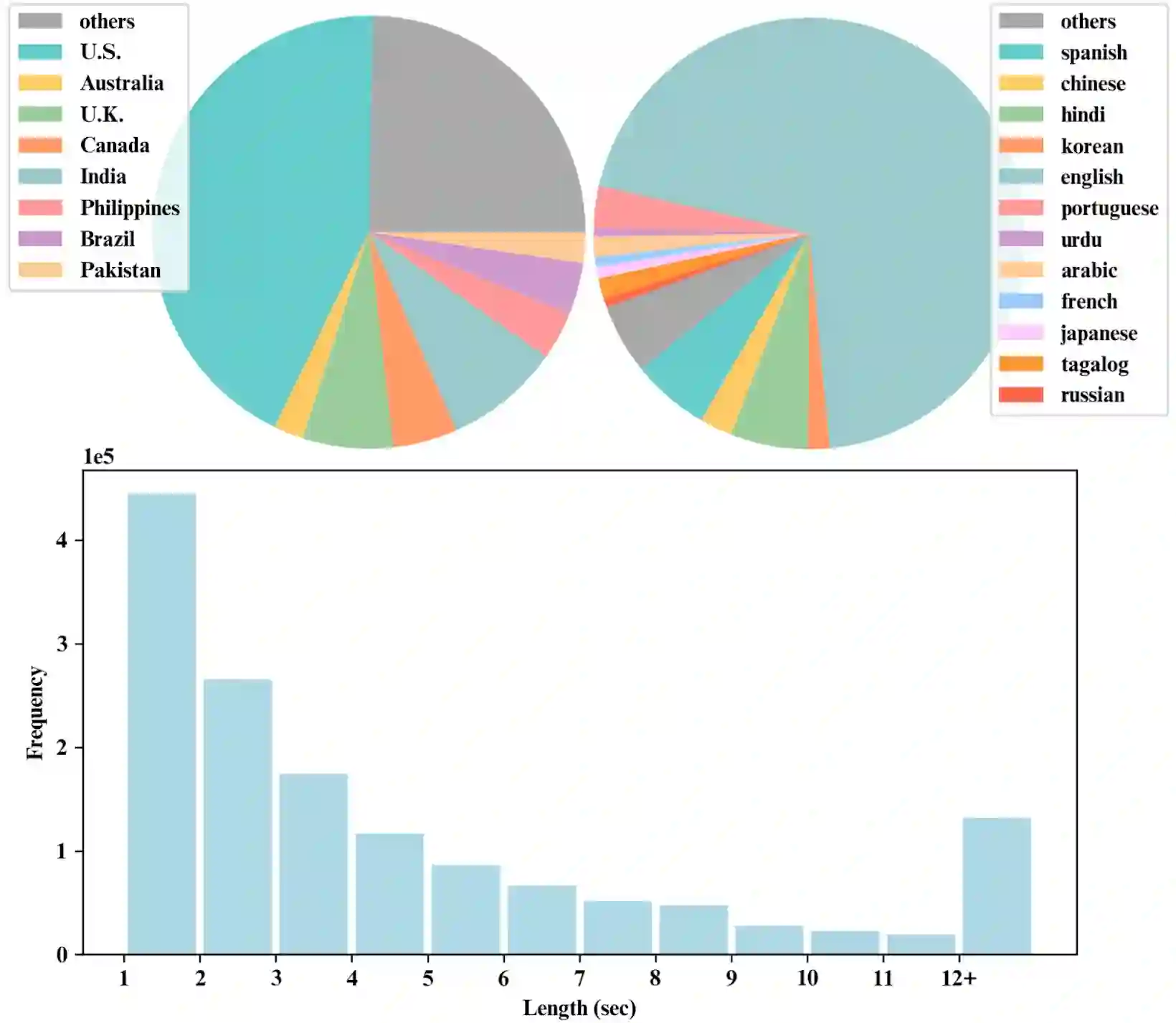
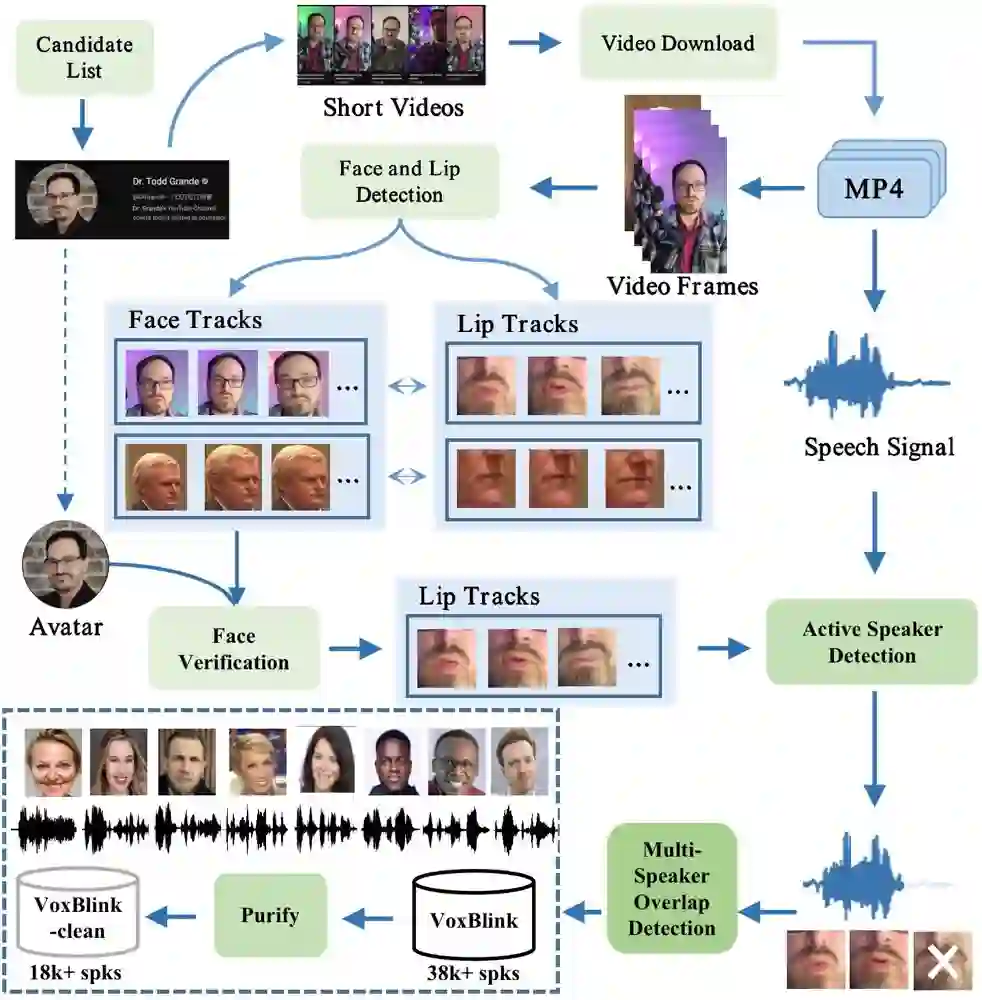
In this paper, we introduce a large-scale and high-quality audio-visual speaker verification dataset, named VoxBlink. We propose an innovative and robust automatic audio-visual data mining pipeline to curate this dataset, which contains 1.45M utterances from 38K speakers. Due to the inherent nature of automated data collection, introducing noisy data is inevitable. Therefore, we also utilize a multi-modal purification to generate a cleaner version of the VoxBlink, named VoxBlink-clean, comprising 18K identities and 1.02M utterances. In contrast to the VoxCeleb, the VoxBlink sources from short videos of ordinary users, and the covered scenarios can better align with real-life situations. To our best knowledge, the VoxBlink dataset is one of the largest publicly available speaker verification datasets. Leveraging the VoxCeleb and VoxBlink-clean datasets together, we employ diverse speaker verification models with multiple architectural backbones to conduct comprehensive experimentation on the VoxCeleb test sets. Experimental results indicate a substantial enhancement in performance-ranging from 12% to 30% relatively-across various backbone architectures upon incorporating the VoxBlink-clean into the training process. The details of the dataset can be found in http://voxblink.github.io
翻译:本文介绍了一个大规模、高质量的视听说话人验证数据集VoxBlink。我们提出了一种创新且鲁棒的自动视听数据挖掘流水线来构建该数据集,其中包含来自38K名说话人的145万条语音。由于自动数据收集的固有特性,引入噪声数据不可避免。因此,我们进一步采用多模态净化方法生成VoxBlink的纯净版本VoxBlink-clean,包含18K个身份及102万条语音。与VoxCeleb不同,VoxBlink的数据源自普通用户的短视频,覆盖场景更能贴近现实生活。据我们所知,VoxBlink数据集是公开可用的最大规模说话人验证数据集之一。我们联合使用VoxCeleb和VoxBlink-clean数据集,采用多种具有不同架构主干的说话人验证模型,在VoxCeleb测试集上进行了全面实验。实验结果表明,将VoxBlink-clean加入训练流程后,不同主干架构的性能均获得显著提升——相对提升幅度达12%至30%。数据集详细信息请参见http://voxblink.github.io。