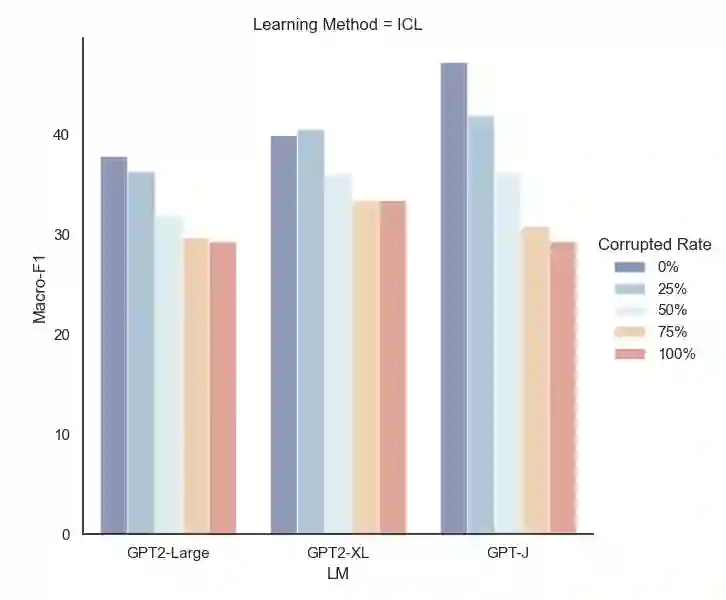
Large language models (LLMs) have shown remarkable capacity for in-context learning (ICL), where learning a new task from just a few training examples is done without being explicitly pre-trained. However, despite the success of LLMs, there has been little understanding of how ICL learns the knowledge from the given prompts. In this paper, to make progress toward understanding the learning behaviour of ICL, we train the same LLMs with the same demonstration examples via ICL and supervised learning (SL), respectively, and investigate their performance under label perturbations (i.e., noisy labels and label imbalance) on a range of classification tasks. First, via extensive experiments, we find that gold labels have significant impacts on the downstream in-context performance, especially for large language models; however, imbalanced labels matter little to ICL across all model sizes. Second, when comparing with SL, we show empirically that ICL is less sensitive to label perturbations than SL, and ICL gradually attains comparable performance to SL as the model size increases.
翻译:大型语言模型(LLMs)在上下文学习(ICL)中展现出显著能力,即使仅通过少量训练示例学习新任务也无需显式预训练。然而,尽管LLMs取得了成功,人们对ICL如何从给定提示中学习知识仍知之甚少。为推进对ICL学习行为的理解,本文分别通过ICL和监督学习(SL)训练相同LLMs使用相同的示范示例,并在多种分类任务中研究其在标签扰动(即噪声标签和标签不平衡)下的表现。首先,通过大量实验发现,金标准标签对下游上下文性能具有显著影响,尤其对大型语言模型而言;然而,标签不平衡对所有模型规模的ICL影响甚微。其次,与SL相比,实验证明ICL对标签扰动的敏感性低于SL,且随着模型规模增大,ICL逐渐获得与SL相当的性能。