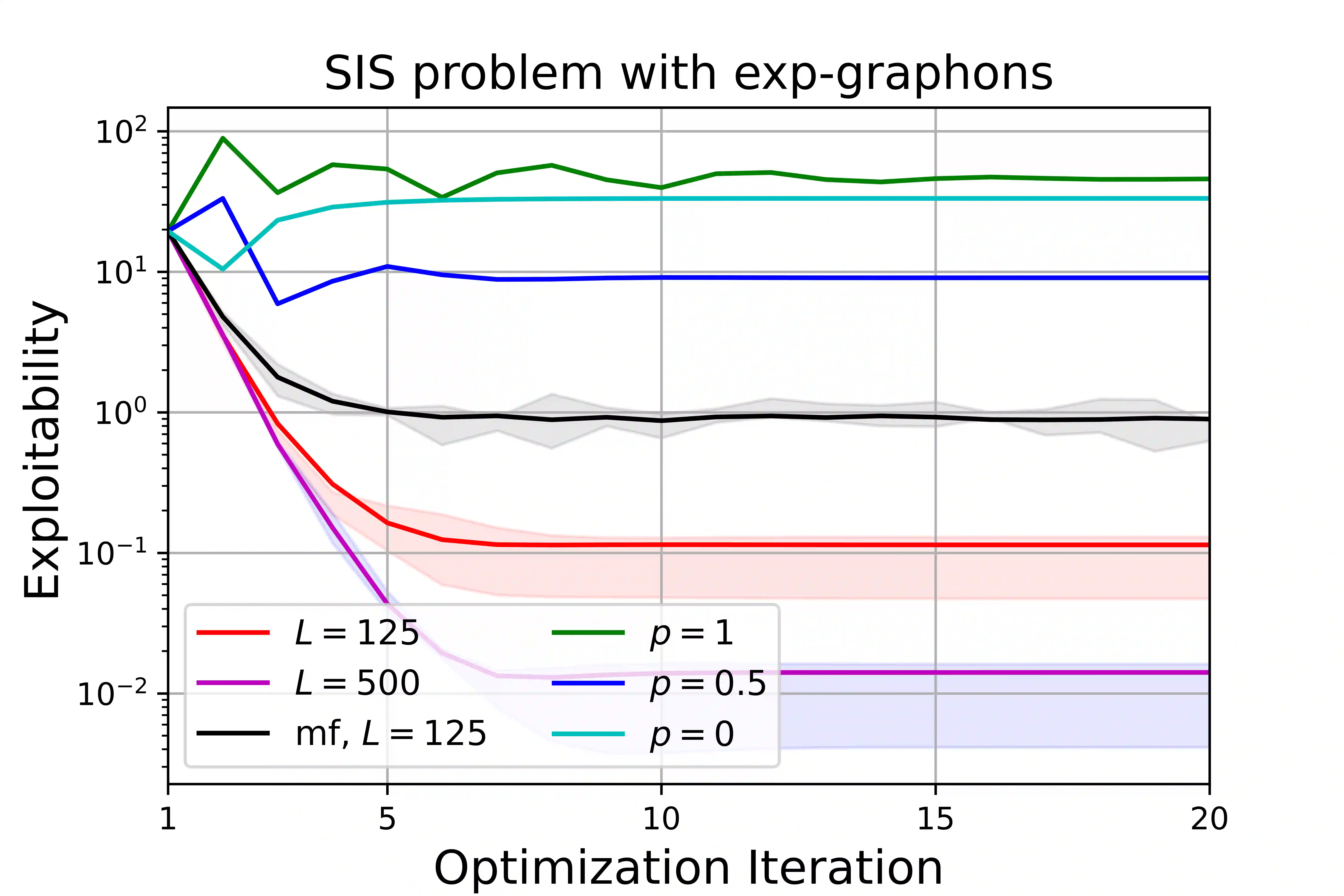
We design and analyze reinforcement learning algorithms for Graphon Mean-Field Games (GMFGs). In contrast to previous works that require the precise values of the graphons, we aim to learn the Nash Equilibrium (NE) of the regularized GMFGs when the graphons are unknown. Our contributions are threefold. First, we propose the Proximal Policy Optimization for GMFG (GMFG-PPO) algorithm and show that it converges at a rate of $O(T^{-1/3})$ after $T$ iterations with an estimation oracle, improving on a previous work by Xie et al. (ICML, 2021). Second, using kernel embedding of distributions, we design efficient algorithms to estimate the transition kernels, reward functions, and graphons from sampled agents. Convergence rates are then derived when the positions of the agents are either known or unknown. Results for the combination of the optimization algorithm GMFG-PPO and the estimation algorithm are then provided. These algorithms are the first specifically designed for learning graphons from sampled agents. Finally, the efficacy of the proposed algorithms are corroborated through simulations. These simulations demonstrate that learning the unknown graphons reduces the exploitability effectively.
翻译:我们设计并分析了图平均场博弈(GMFGs)的强化学习算法。与以往需要精确图值的工作不同,我们的目标是在图未知的情况下学习正则化GMFGs的纳什均衡(NE)。我们的贡献包括三个方面。首先,我们提出了GMFG的近端策略优化(GMFG-PPO)算法,并证明在具有估计预言的情况下,经过$T$次迭代后该算法以$O(T^{-1/3})$的速率收敛,改进了Xie等人(ICML, 2021)的先前工作。其次,利用分布的核嵌入方法,我们设计了高效算法,从采样智能体中估计转移核、奖励函数和图。随后推导了当智能体位置已知或未知时的收敛速率,并进一步给出了优化算法GMFG-PPO与估计算法结合的结果。这些算法是首个专门为从采样智能体中学习图而设计的。最后,通过仿真实验验证了所提算法的有效性。仿真结果表明,学习未知图能够有效降低可剥削性。