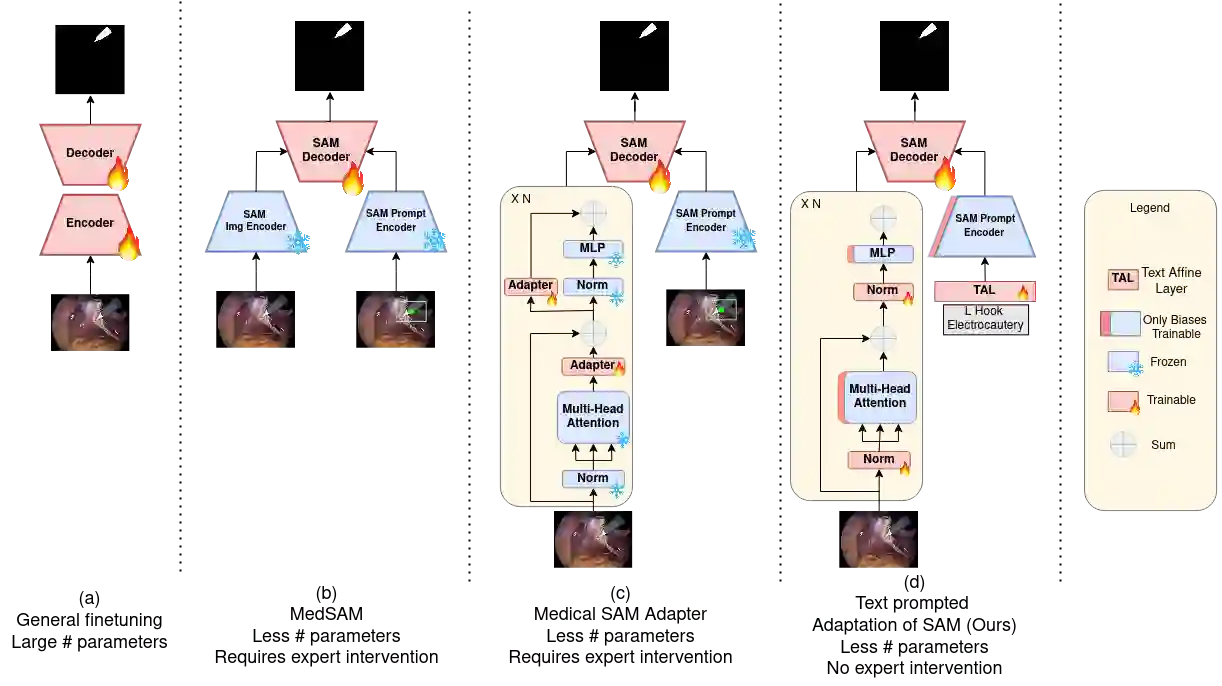
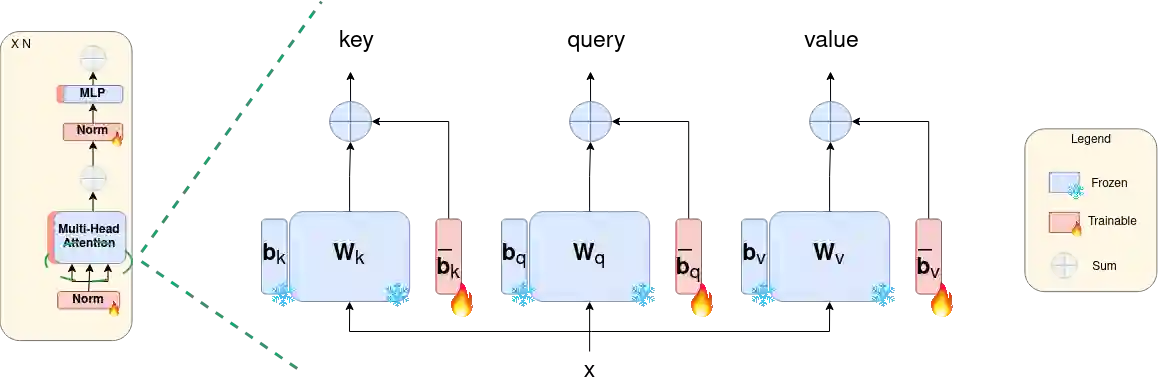
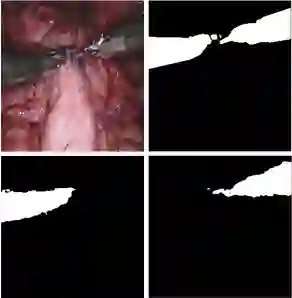
Segmentation is a fundamental problem in surgical scene analysis using artificial intelligence. However, the inherent data scarcity in this domain makes it challenging to adapt traditional segmentation techniques for this task. To tackle this issue, current research employs pretrained models and finetunes them on the given data. Even so, these require training deep networks with millions of parameters every time new data becomes available. A recently published foundation model, Segment-Anything (SAM), generalizes well to a large variety of natural images, hence tackling this challenge to a reasonable extent. However, SAM does not generalize well to the medical domain as is without utilizing a large amount of compute resources for fine-tuning and using task-specific prompts. Moreover, these prompts are in the form of bounding-boxes or foreground/background points that need to be annotated explicitly for every image, making this solution increasingly tedious with higher data size. In this work, we propose AdaptiveSAM - an adaptive modification of SAM that can adjust to new datasets quickly and efficiently, while enabling text-prompted segmentation. For finetuning AdaptiveSAM, we propose an approach called bias-tuning that requires a significantly smaller number of trainable parameters than SAM (less than 2\%). At the same time, AdaptiveSAM requires negligible expert intervention since it uses free-form text as prompt and can segment the object of interest with just the label name as prompt. Our experiments show that AdaptiveSAM outperforms current state-of-the-art methods on various medical imaging datasets including surgery, ultrasound and X-ray. Code is available at https://github.com/JayParanjape/biastuning
翻译:分割是人工智能手术场景分析中的基础问题。然而,该领域固有的数据稀缺性使得传统分割技术难以适应这一任务。为解决此问题,当前研究采用预训练模型并在给定数据上进行微调。即便如此,每当新数据出现时,仍需训练包含数百万参数的深度网络。最近发布的基础模型Segment-Anything(SAM)能较好地泛化至大量自然图像,从而在一定程度上解决了这一挑战。但若未使用大量计算资源进行微调和任务特定提示,SAM无法直接很好地泛化至医学领域。此外,这些提示以边界框或前景/背景点的形式存在,需对每张图像显式标注,随着数据量增大,该解决方案变得愈发繁琐。在本工作中,我们提出AdaptiveSAM——一种SAM的自适应改进版本,能够快速高效地适应新数据集,同时支持文本提示分割。针对AdaptiveSAM的微调,我们提出一种名为偏置微调的方法,所需可训练参数数量远少于SAM(不足2%)。与此同时,AdaptiveSAM需要极少专家干预,因其使用自由文本作为提示,仅需以标签名作为提示即可分割目标物体。实验表明,AdaptiveSAM在包括手术、超声和X光在内的多种医学影像数据集上,性能优于当前最先进方法。代码见https://github.com/JayParanjape/biastuning