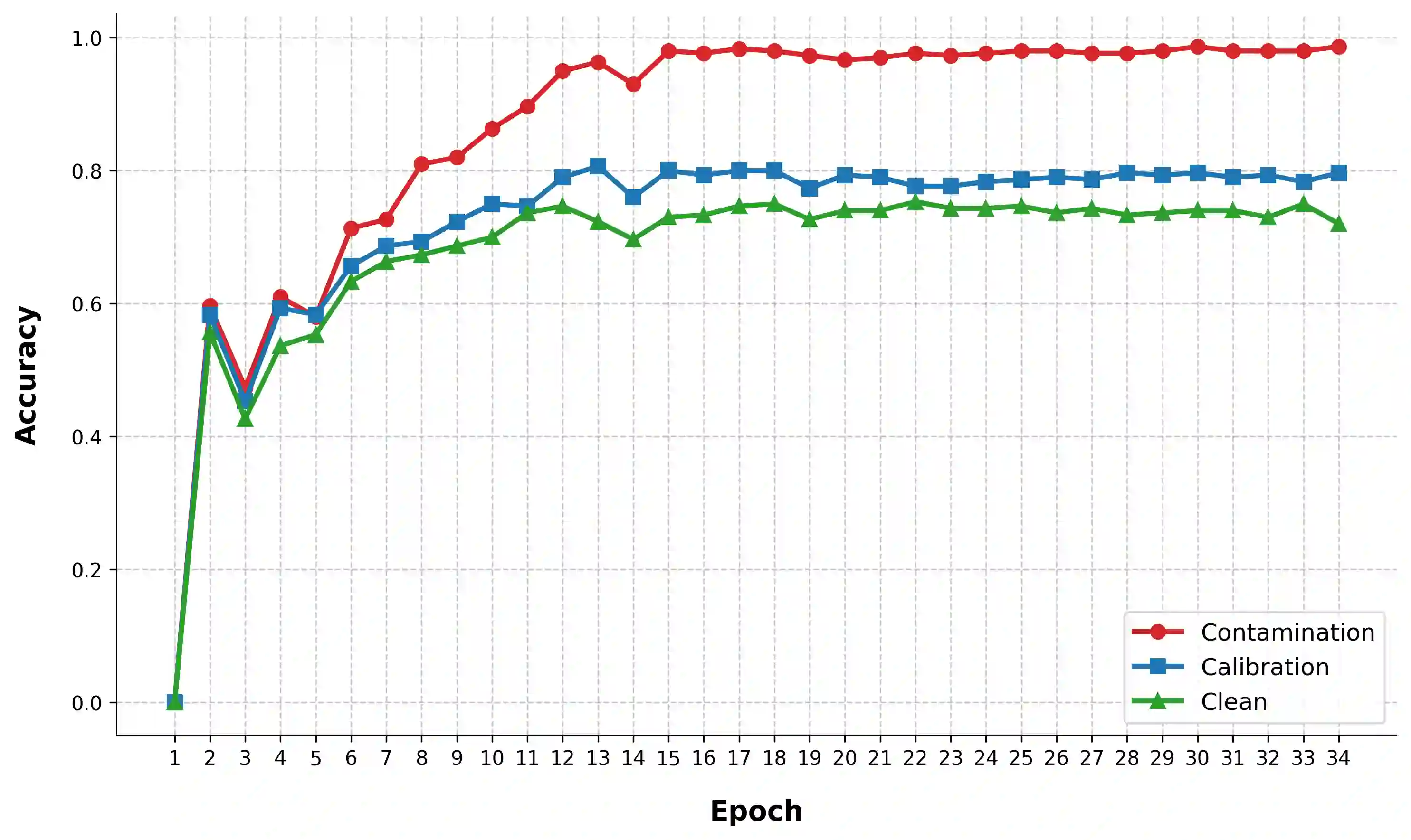
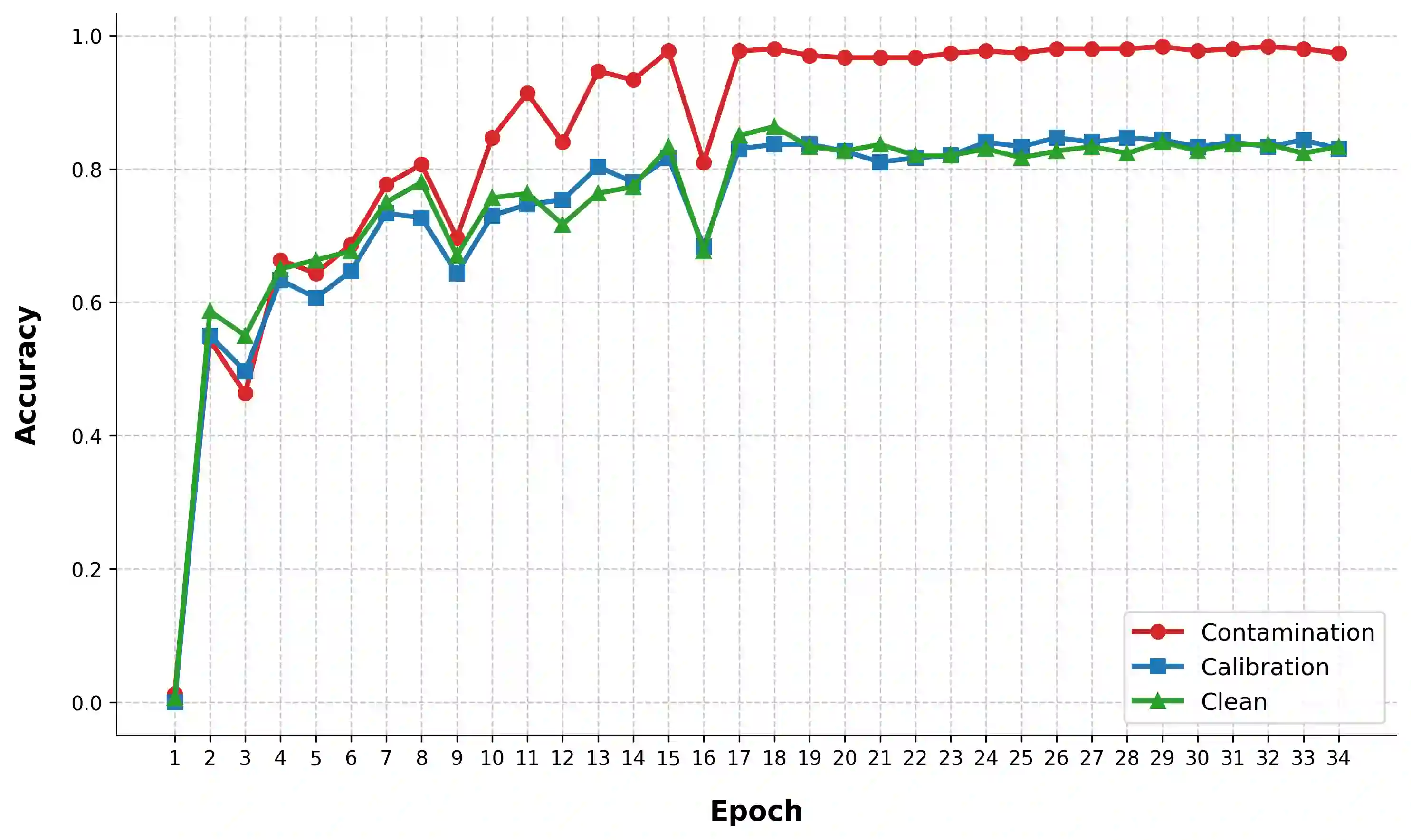
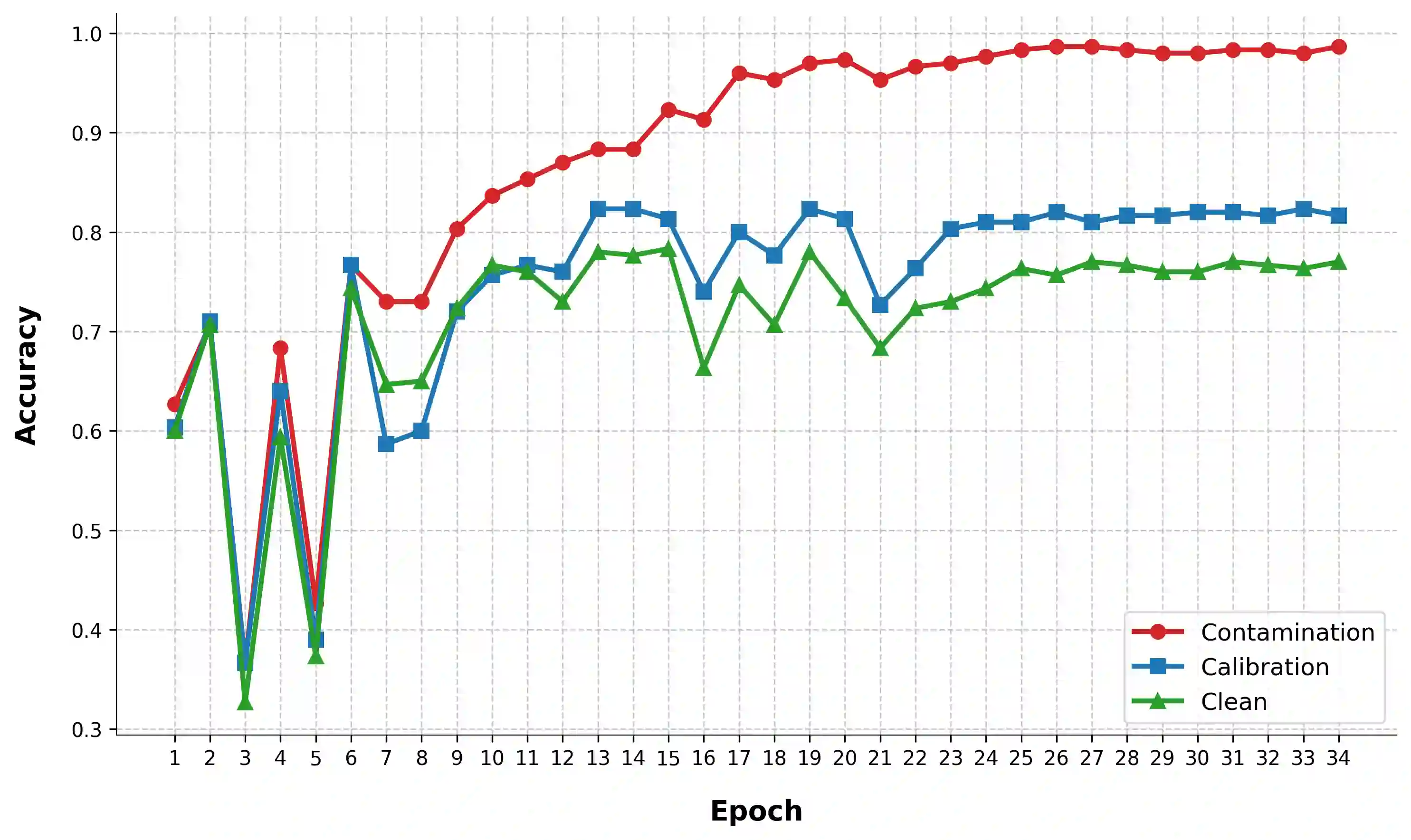
We are currently in an era of fierce competition among various large language models (LLMs) continuously pushing the boundaries of benchmark performance. However, genuinely assessing the capabilities of these LLMs has become a challenging and critical issue due to potential data contamination, and it wastes dozens of time and effort for researchers and engineers to download and try those contaminated models. To save our precious time, we propose a novel and useful method, Clean-Eval, which mitigates the issue of data contamination and evaluates the LLMs in a cleaner manner. Clean-Eval employs an LLM to paraphrase and back-translate the contaminated data into a candidate set, generating expressions with the same meaning but in different surface forms. A semantic detector is then used to filter the generated low-quality samples to narrow down this candidate set. The best candidate is finally selected from this set based on the BLEURT score. According to human assessment, this best candidate is semantically similar to the original contamination data but expressed differently. All candidates can form a new benchmark to evaluate the model. Our experiments illustrate that Clean-Eval substantially restores the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.
翻译:我们正处在一个各大语言模型竞相提升基准测试性能的激烈竞争时代。然而,由于潜在的数据污染问题,真正评估这些大型语言模型的能力已成为一项既具挑战性又至关重要的问题——研究人员与工程师耗费大量时间与精力下载并测试受污染模型,却往往徒劳无功。为节省宝贵时间,我们提出了一种新颖实用的方法Clean-Eval,该方法可缓解数据污染问题,并以更清洁的方式评估大型语言模型。Clean-Eval首先利用大型语言模型对受污染数据进行释义与回译,生成具有相同语义但不同表面形式的候选集;随后通过语义检测器过滤低质量样本以缩小候选集范围;最终基于BLEURT评分从候选集中选取最优样本。人工评估表明,该最优样本与原始污染数据语义相似但表述不同。所有候选样本可构成新基准以评估模型。实验证明,在少样本学习与微调场景下,Clean-Eval能有效恢复受污染语言模型的真实评估结果。