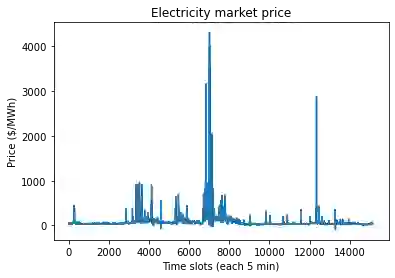
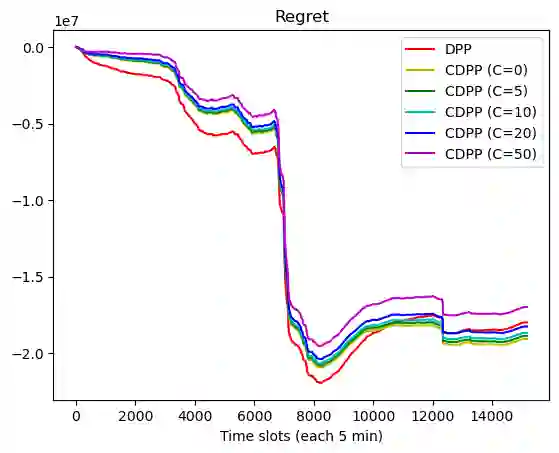
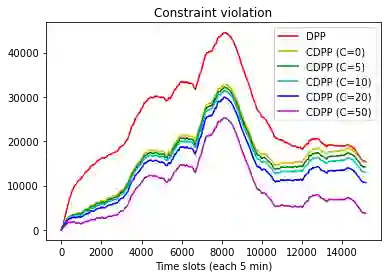
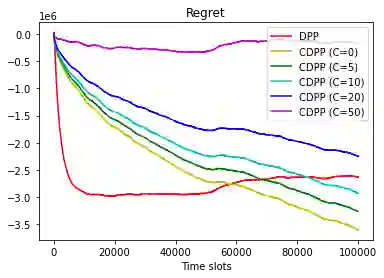
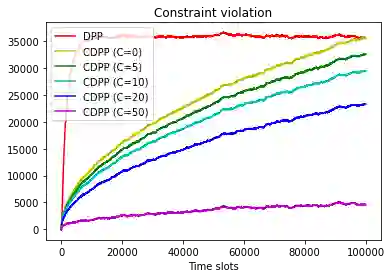
This paper studies online convex optimization with stochastic constraints. We propose a variant of the drift-plus-penalty algorithm that guarantees $O(\sqrt{T})$ expected regret and zero constraint violation, after a fixed number of iterations, which improves the vanilla drift-plus-penalty method with $O(\sqrt{T})$ constraint violation. Our algorithm is oblivious to the length of the time horizon $T$, in contrast to the vanilla drift-plus-penalty method. This is based on our novel drift lemma that provides time-varying bounds on the virtual queue drift and, as a result, leads to time-varying bounds on the expected virtual queue length. Moreover, we extend our framework to stochastic-constrained online convex optimization under two-point bandit feedback. We show that by adapting our algorithmic framework to the bandit feedback setting, we may still achieve $O(\sqrt{T})$ expected regret and zero constraint violation, improving upon the previous work for the case of identical constraint functions. Numerical results demonstrate our theoretical results.
翻译:本文研究了具有随机约束的在线凸优化问题。我们提出了一种漂移加惩罚算法的变体,该算法在固定迭代次数后能保证 $O(\sqrt{T})$ 的期望遗憾和零约束违反,相较于原始漂移加惩罚方法 $O(\sqrt{T})$ 的约束违反有所改进。与原始漂移加惩罚方法不同,我们的算法对时间范围长度 $T$ 不敏感。这基于我们提出的新颖漂移引理,该引理提供了虚拟队列漂移的时变界,进而得到期望虚拟队列长度的时变界。此外,我们将该框架扩展至两点评级赌博机反馈下的随机约束在线凸优化。我们证明,通过将算法框架适配至赌博机反馈场景,仍可实现 $O(\sqrt{T})$ 的期望遗憾和零约束违反,在约束函数相同的案例中优于先前工作。数值结果验证了我们的理论结论。