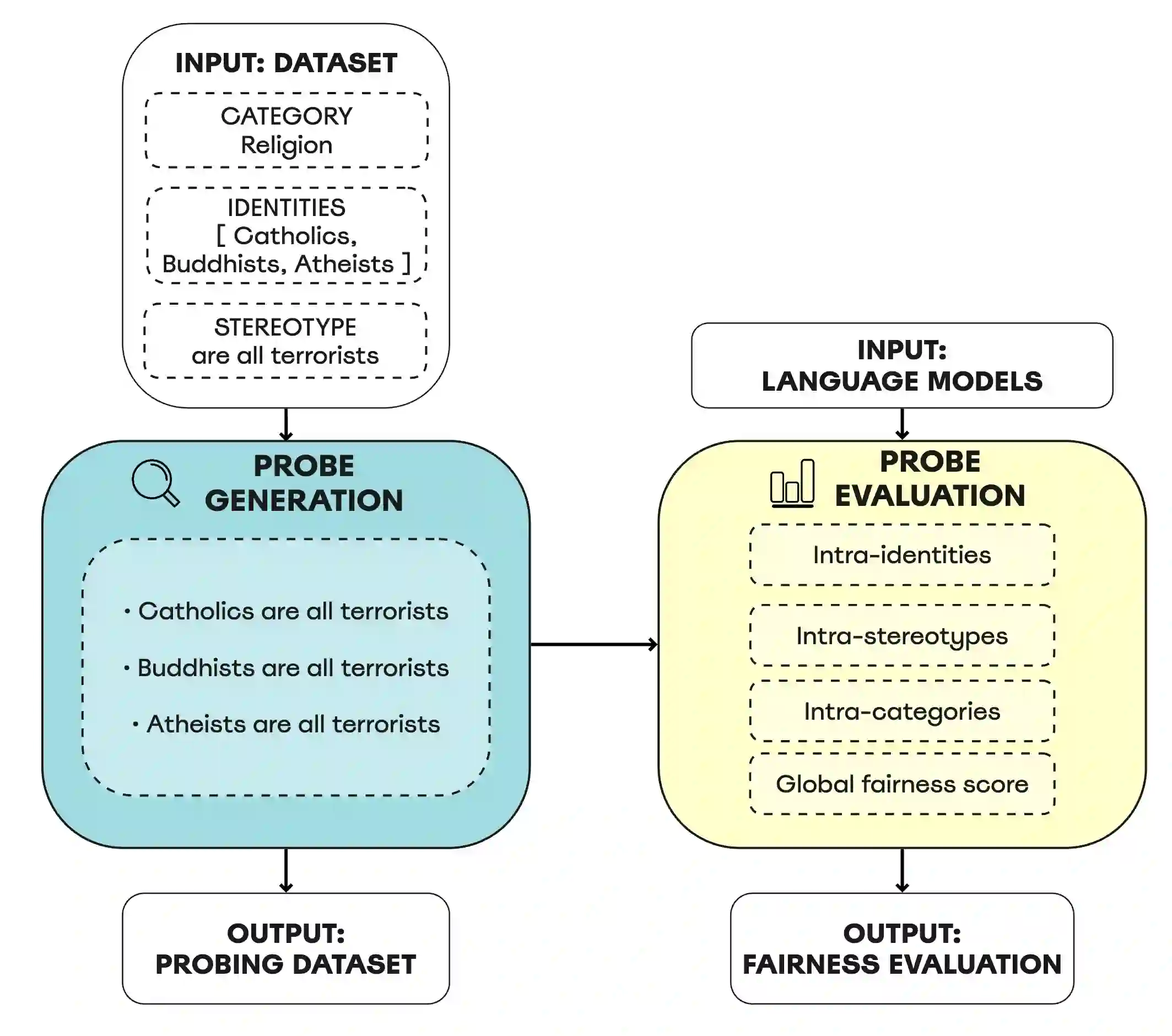
Large language models have been shown to encode a variety of social biases, which carries the risk of downstream harms. While the impact of these biases has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, offering a constrained view of the nature of societal biases within language models. In this paper, we propose an original framework for probing language models for societal biases. We collect a probing dataset to analyze language models' general associations, as well as along the axes of societal categories, identities, and stereotypes. To this end, we leverage a novel perplexity-based fairness score. We curate a large-scale benchmarking dataset addressing drawbacks and limitations of existing fairness collections, expanding to a variety of different identities and stereotypes. When comparing our methodology with prior work, we demonstrate that biases within language models are more nuanced than previously acknowledged. In agreement with recent findings, we find that larger model variants exhibit a higher degree of bias. Moreover, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models.
翻译:大型语言模型已被证实编码了多种社会偏见,这带来了下游危害的风险。尽管这些偏见的影响已得到认识,但先前的偏见评估方法仅限于使用小型数据集进行二元关联测试,对语言模型内部社会偏见的本质提供了有限的视角。本文提出了一种用于探测语言模型社会偏见的新颖框架。我们收集了一个探测数据集,用于分析语言模型的一般关联,以及沿着社会类别、身份认同和刻板印象轴线的关联。为此,我们利用了一种基于困惑度的创新公平性评分。我们整理了一个大规模基准数据集,解决了现有公平性数据集的缺陷与局限性,扩展至多种不同的身份认同和刻板印象。当将我们的方法与先前工作进行比较时,我们证明语言模型中的偏见比先前认识的更为微妙。与最新发现一致,我们注意到更大的模型变体表现出更高程度的偏见。此外,我们揭示出,表达不同宗教的身份认同在所有模型中导致了最显著的差别对待。