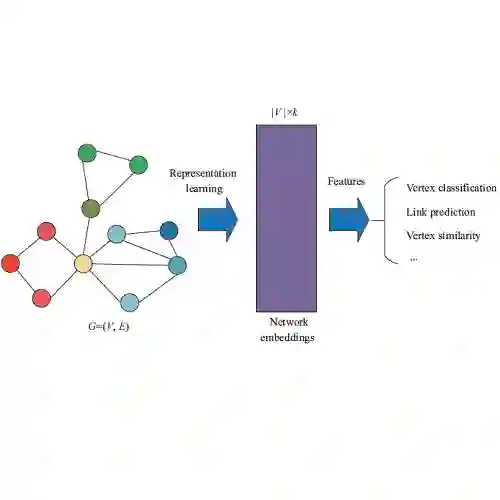
Graph clustering - partitioning the node set of a graph into disjoint subsets that reflect some latent information - is a fundamental problem as it finds applications in a myriad of different scenarios. While this classic problem has been tackled for decades by different communities, a recent variation of the problem driven by real data considers the scenario where nodes have attributes that are also informative. This has triggered novel methods that simultaneously leverage network information (edges) and node information (attributed) in the design of novel clustering algorithms. This work proposes a novel framework that builds on prior works that have applied graph neural networks (GNN) to graph clustering. The proposed framework operates in rounds of self learning in a fully unsupervised setting. In each round, a GNN generates representations for nodes that are used to cluster the nodes. This clustering influences the graph used to generate the node representation in the next round. Moreover, a context graph built in each round using the original graph is used to generate the node representations. Empirical results show that the proposed methodology extracts information from both network edges and node attributes in synthetic data, outperforming algorithms focused solely on the network or attributes when neither are very informative. Multiple rounds of learning also improve the performance and always outperforms a long single round of training (i.e., classic GNN graph clustering). When considering real datasets, empirical results indicate that the proposed methodology is competitive to state-of-the-art methods when cluster sizes are balanced.
翻译:图聚类——将图的节点集划分为反映潜在信息的互斥子集——是一个基础性问题,因其在多种场景中均有应用。尽管这一经典问题已被不同领域的研究者攻克数十年,但由真实数据驱动的新近变体考虑了节点属性也包含信息量的情形。这催生了在新型聚类算法设计中同时利用网络信息(边)与节点信息(属性)的创新方法。本文提出了一种新颖框架,建立在先前将图神经网络(GNN)应用于图聚类的研究基础之上。该框架在完全无监督的设置下通过自学习轮次运行。在每一轮中,GNN生成用于节点聚类的节点表示,而聚类结果又影响下一轮用于生成节点表示的图结构。此外,每一轮中利用原始图构建的上下文图也被用于生成节点表示。实验结果表明,所提方法能从合成数据的网络边与节点属性中提取信息,在网络或属性信息量均不充足时优于仅聚焦于网络或属性的算法。多轮学习还能持续提升性能,且始终优于单轮长训练(即经典GNN图聚类)。在处理真实数据集时,实验结果表明,当簇规模平衡时,所提方法与现有最优方法具有竞争力。