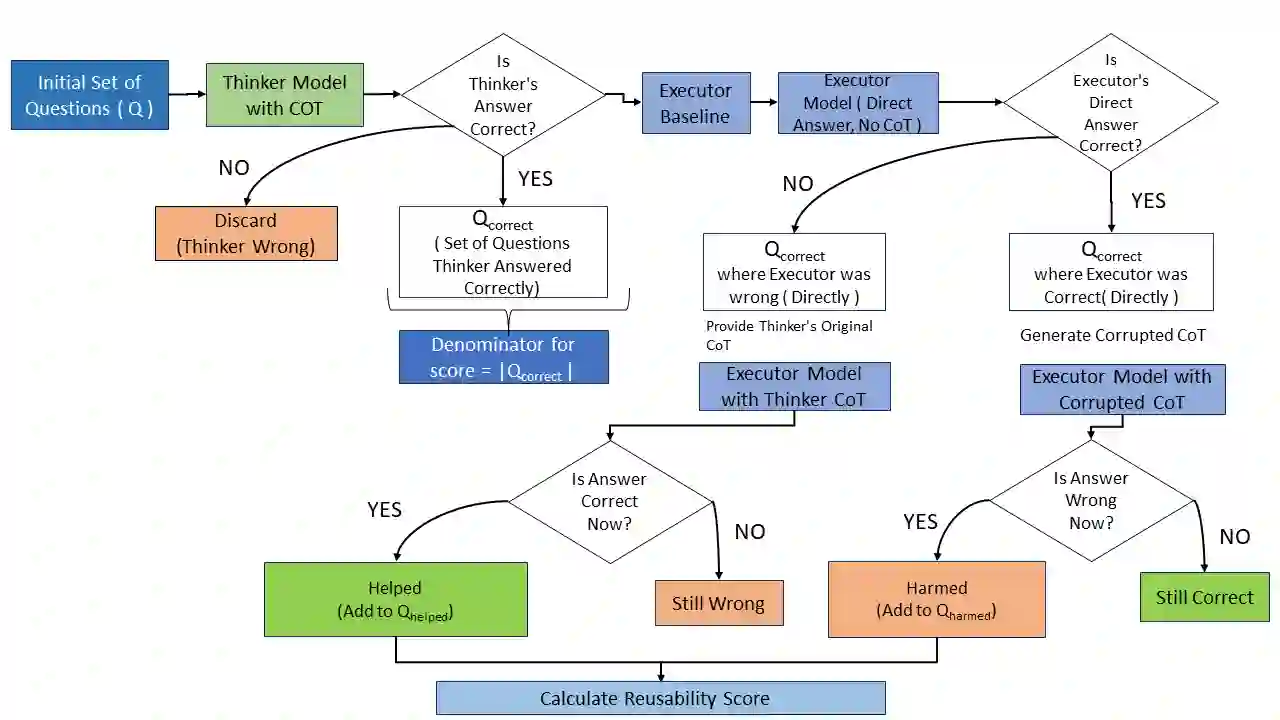
In multi-agent IR pipelines for tasks such as search and ranking, LLM-based agents exchange intermediate reasoning in terms of Chain-of-Thought (CoT) with each other. Current CoT evaluation narrowly focuses on target task accuracy. However, this metric fails to assess the quality or utility of the reasoning process itself. To address this limitation, we introduce two novel measures: reusability and verifiability. We decouple CoT generation from execution using a Thinker-Executor framework. Reusability measures how easily an Executor can reuse the Thinker's CoT. Verifiability measures how frequently an Executor can match the Thinker's answer using the CoT. We evaluated four Thinker models against a committee of ten Executor models across five benchmarks. Our results reveal that reusability and verifiability do not correlate with standard accuracy, exposing a blind spot in current accuracy-based leaderboards for reasoning capability. Surprisingly, we find that CoTs from specialized reasoning models are not consistently more reusable or verifiable than those from general-purpose LLMs like Llama and Gemma.
翻译:在多智能体信息检索流水线(如搜索与排序任务)中,基于大语言模型的智能体之间会以思维链的形式交换中间推理过程。当前对思维链的评估仅狭隘地关注目标任务准确率。然而,该指标无法评估推理过程本身的质量或效用。为弥补这一局限,我们引入了两个新颖的度量标准:可复用性与可验证性。我们采用思考者-执行者框架,将思维链的生成与执行解耦。可复用性衡量执行者复用思考者思维链的难易程度。可验证性衡量执行者使用该思维链得出与思考者相同答案的频率。我们在五个基准测试上,评估了四种思考者模型与一个由十种执行者模型组成的委员会。结果表明,可复用性与可验证性与标准准确率不相关,这揭示了当前基于准确率的推理能力排行榜存在盲区。令人惊讶的是,我们发现来自专用推理模型的思维链,其可复用性或可验证性并不一致地优于来自通用大语言模型(如 Llama 和 Gemma)的思维链。