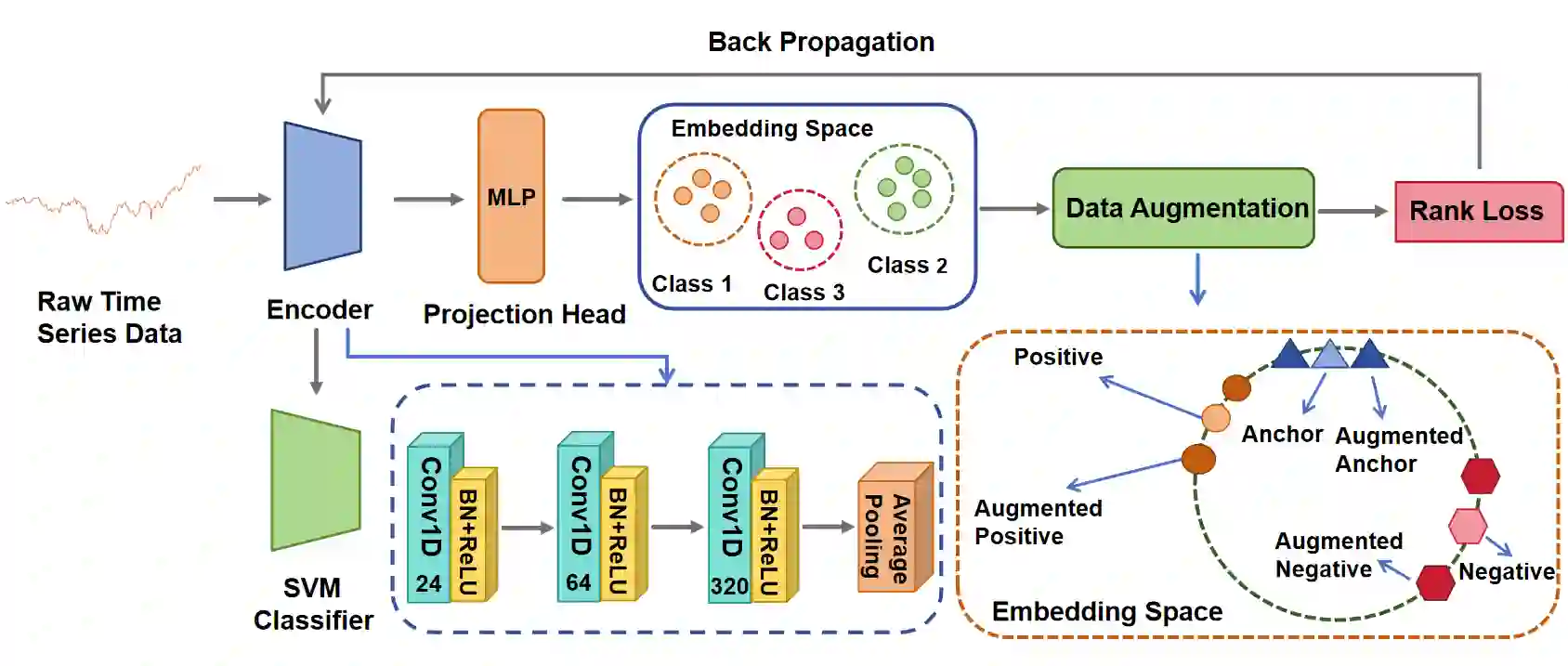
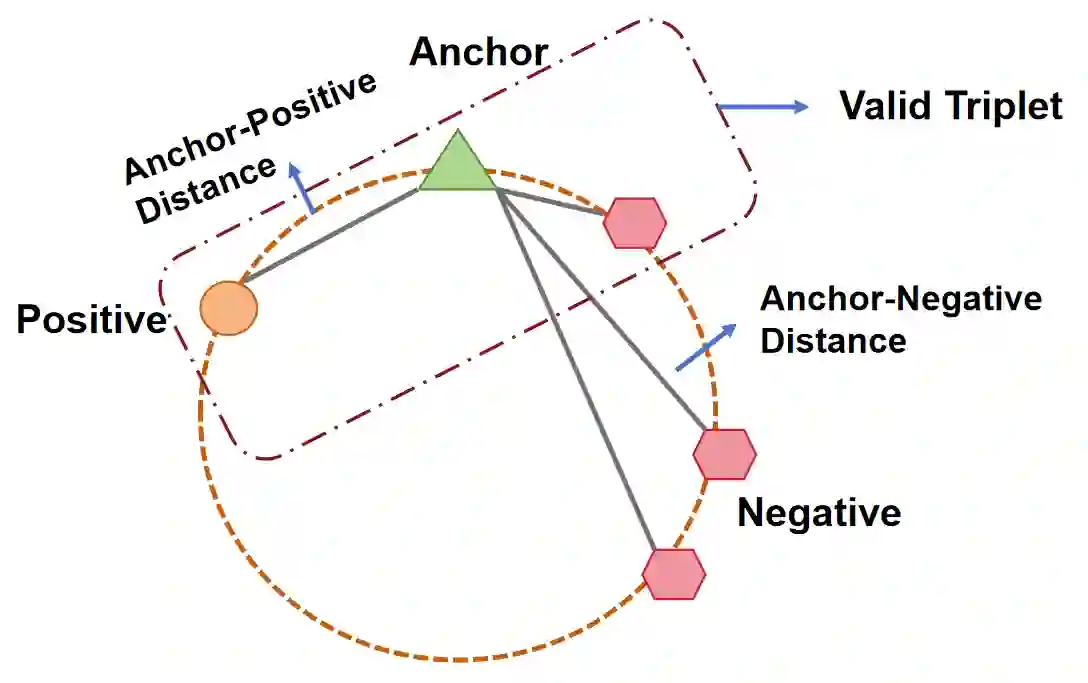
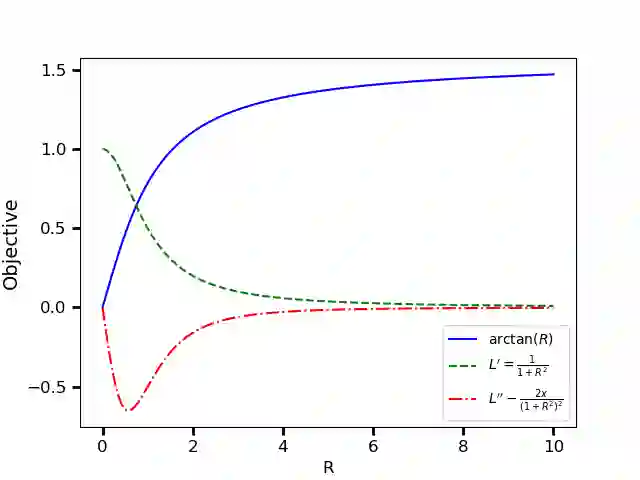
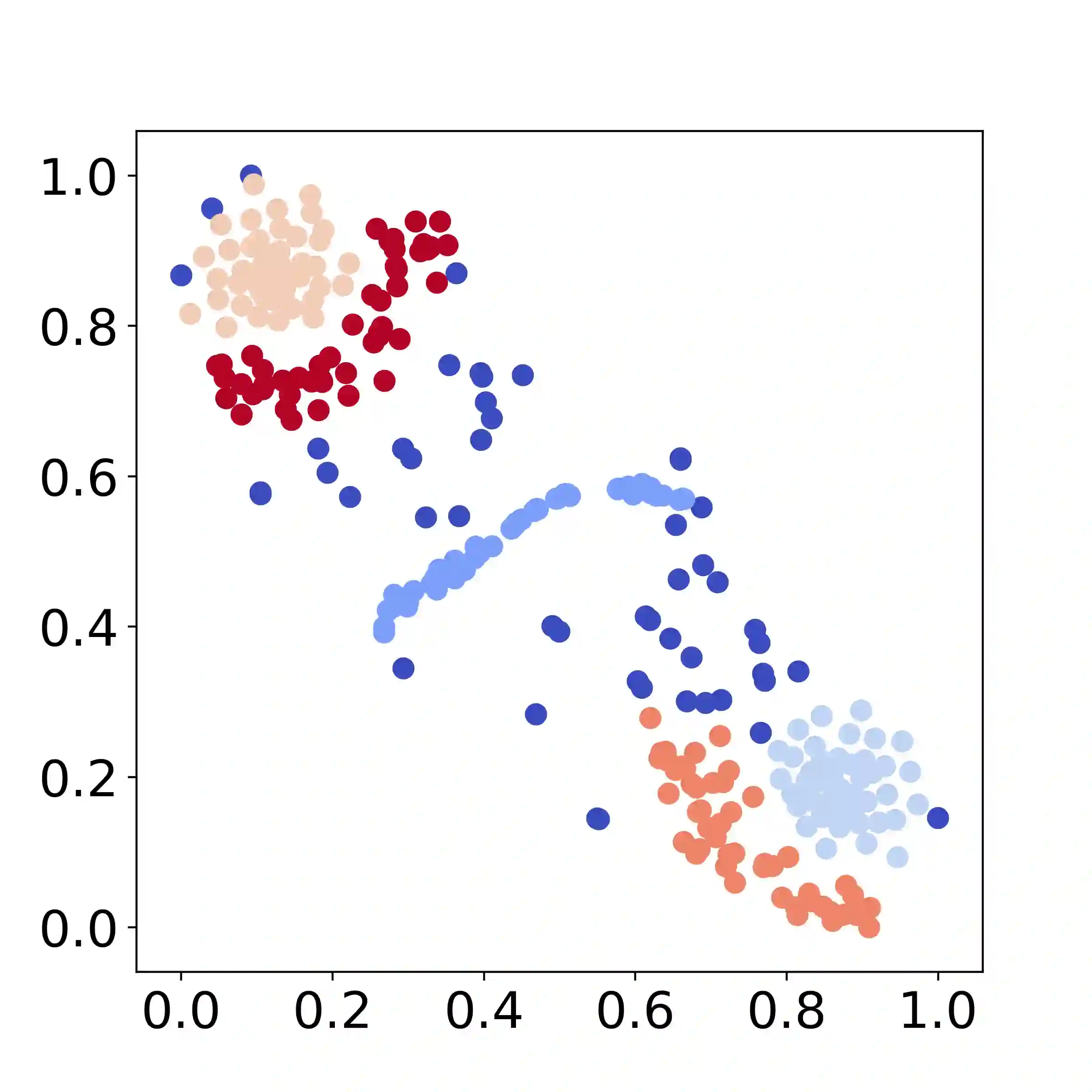
Recently, various contrastive learning techniques have been developed to categorize time series data and exhibit promising performance. A general paradigm is to utilize appropriate augmentations and construct feasible positive samples such that the encoder can yield robust and discriminative representations by mapping similar data points closer together in the feature space while pushing dissimilar data points farther apart. Despite its efficacy, the fine-grained relative similarity (e.g., rank) information of positive samples is largely ignored, especially when labeled samples are limited. To this end, we present Rank Supervised Contrastive Learning (RankSCL) to perform time series classification. Different from conventional contrastive learning frameworks, RankSCL augments raw data in a targeted way in the embedding space and adopts certain filtering rules to select more informative positive and negative pairs of samples. Moreover, a novel rank loss is developed to assign different weights for different levels of positive samples, enable the encoder to extract the fine-grained information of the same class, and produce a clear boundary among different classes. Thoroughly empirical studies on 128 UCR datasets and 30 UEA datasets demonstrate that the proposed RankSCL can achieve state-of-the-art performance compared to existing baseline methods.
翻译:近期,多种对比学习技术被开发用于时间序列数据分类,并展现出良好的性能。其通用范式是通过适当的增强方法构建可行的正样本,使编码器在特征空间中将相似数据点映射得更近、将相异数据点推得更远,从而生成鲁棒且具有判别性的表示。尽管该方法有效,但正样本的细粒度相对相似性(如排序)信息在很大程度上被忽视,尤其在标注样本有限的情况下。为此,我们提出排序监督对比学习(RankSCL)以执行时间序列分类。与传统的对比学习框架不同,RankSCL在嵌入空间中对原始数据进行目标性增强,并采用特定过滤规则选择更具信息量的正负样本对。此外,我们设计了一种新颖的排序损失函数,为不同级别的正样本赋予不同权重,使编码器能够提取同类样本的细粒度信息,并在不同类之间形成清晰的边界。在128个UCR数据集和30个UEA数据集上的充分实验表明,与现有基线方法相比,所提出的RankSCL能够实现最先进的性能。