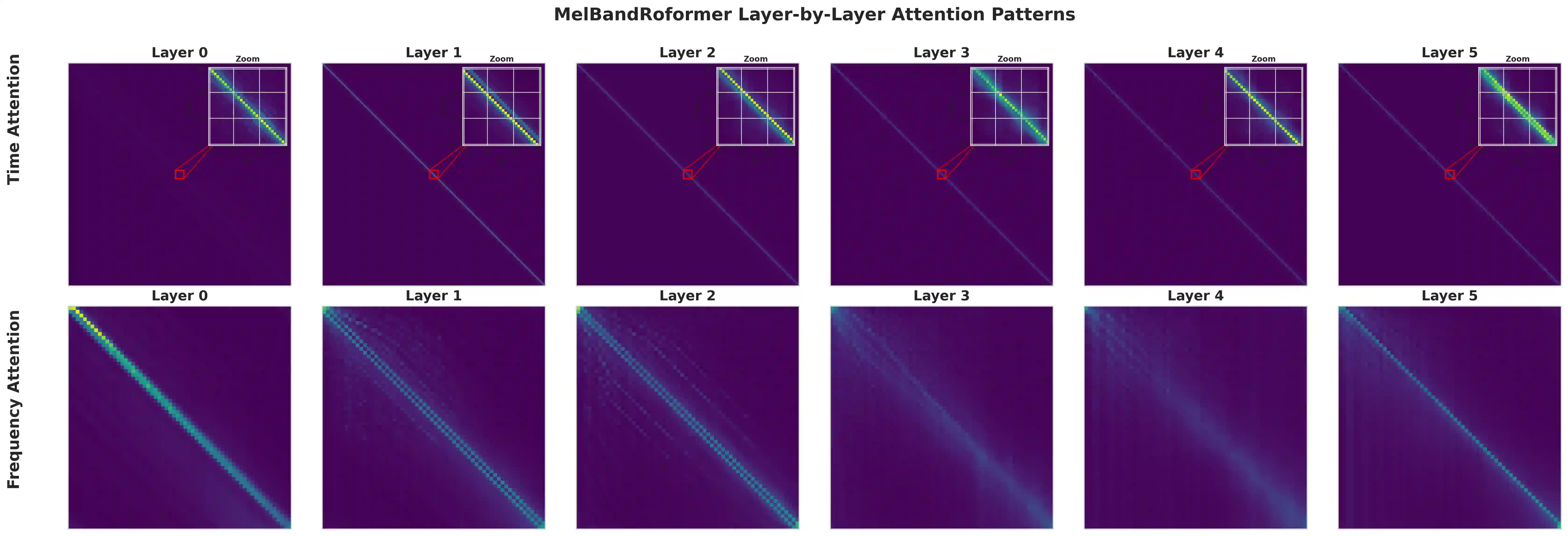
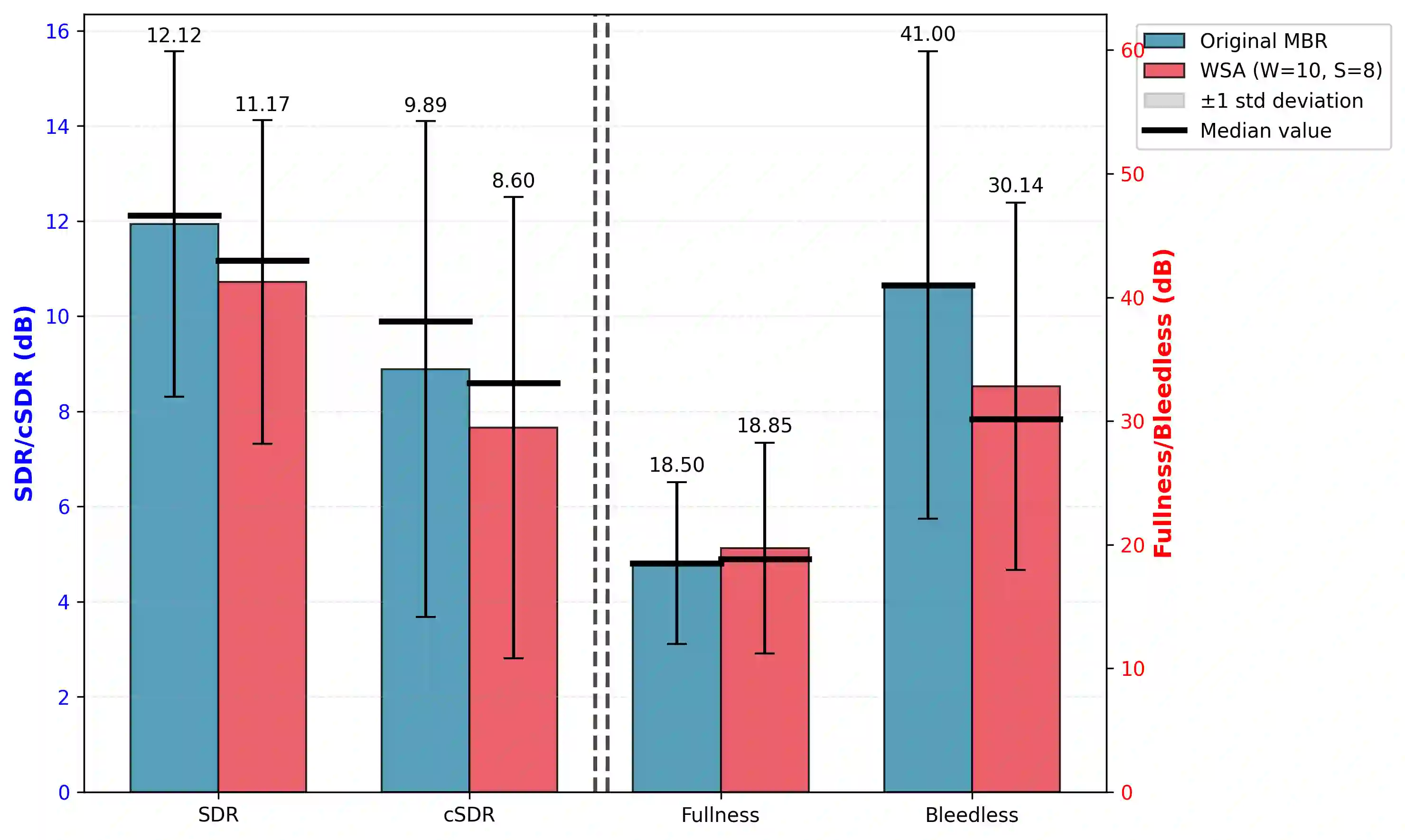
State-of-the-art vocal separation models like Mel-Band-Roformer rely on full temporal self-attention mechanisms, where each temporal frame interacts with every other frames. This incurs heavy computational costs that scales quadratically with input audio length, motivating chunking and windowing approaches. Through analysis of a pre-trained vocal separation model, we discovered that temporal attention patterns are highly localized. Building on this insight, we replaced full attention with windowed sink attention (WSA) with small temporal attention window and attention sinks. We show empirically that fine-tuning from the original checkpoint recovers 92% of the original SDR performance while reducing FLOPs by 44.5x. We release our code and checkpoints under MIT license at https://github.com/smulelabs/windowed-roformer.
翻译:当前最先进的声源分离模型(如Mel-Band-Roformer)依赖于全时序自注意力机制,其中每个时间帧与所有其他帧进行交互。这导致计算成本高昂,且随输入音频长度呈二次方增长,从而推动了分块与窗口化方法的研究。通过对预训练声源分离模型的分析,我们发现其时间注意力模式具有高度局部性。基于这一洞察,我们将全注意力替换为具有小时间注意力窗口和注意力汇聚机制的窗口化汇聚注意力(WSA)。实验表明,从原始检查点进行微调可恢复原模型92%的信噪比性能,同时将浮点运算量降低44.5倍。我们已将代码和检查点以MIT许可证发布于https://github.com/smulelabs/windowed-roformer。