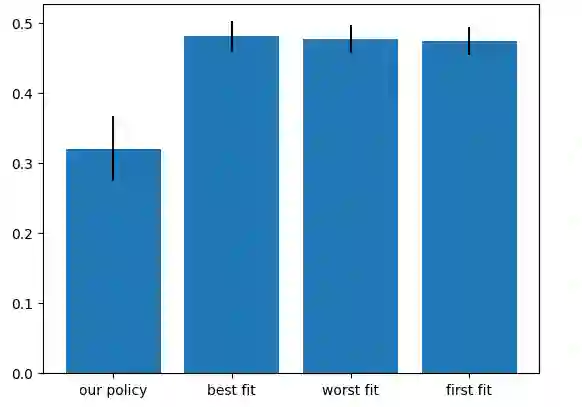
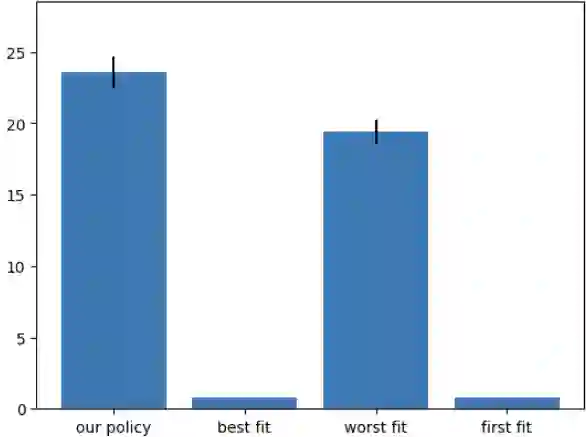
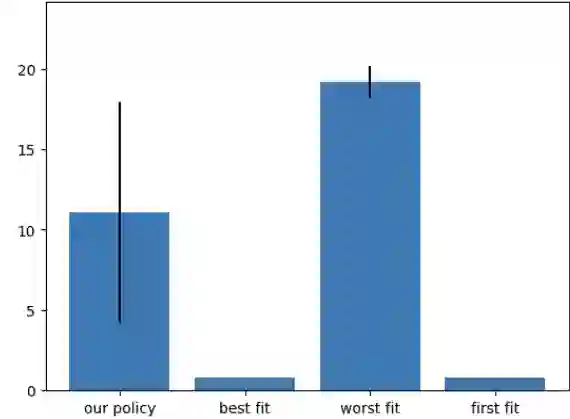
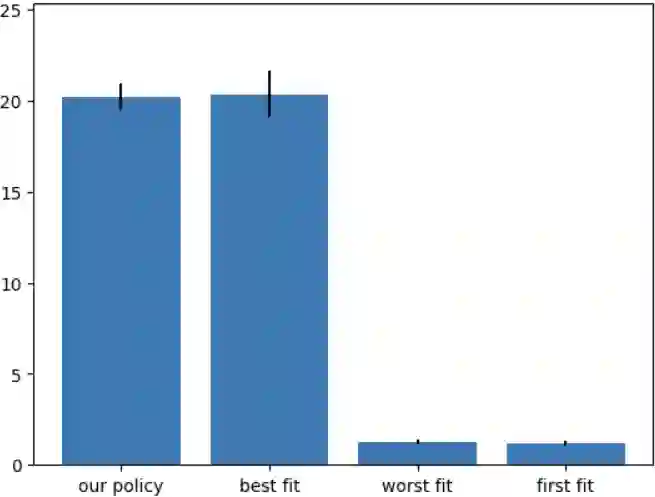
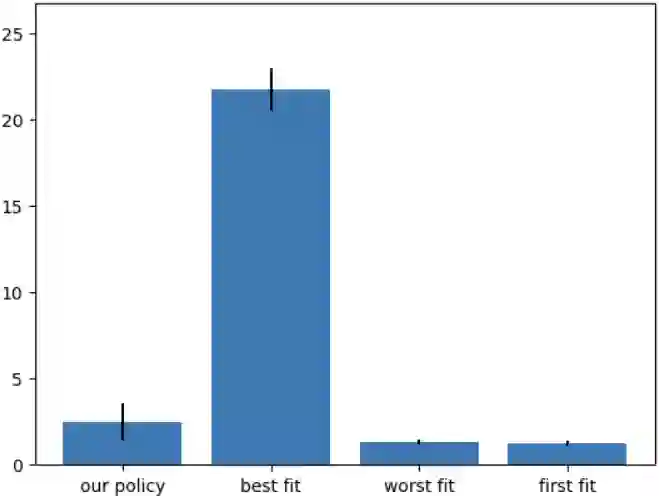
In recent years, reinforcement learning (RL) has gained popularity and has been applied to a wide range of tasks. One such popular domain where RL has been effective is resource management problems in systems. We look to extend work on RL for resource management problems by considering the novel domain of dynamic memory allocation management. We consider dynamic memory allocation to be a suitable domain for RL since current algorithms like first-fit, best-fit, and worst-fit can fail to adapt to changing conditions and can lead to fragmentation and suboptimal efficiency. In this paper, we present a framework in which an RL agent continuously learns from interactions with the system to improve memory management tactics. We evaluate our approach through various experiments using high-level and low-level action spaces and examine different memory allocation patterns. Our results show that RL can successfully train agents that can match and surpass traditional allocation strategies, particularly in environments characterized by adversarial request patterns. We also explore the potential of history-aware policies that leverage previous allocation requests to enhance the allocator's ability to handle complex request patterns. Overall, we find that RL offers a promising avenue for developing more adaptive and efficient memory allocation strategies, potentially overcoming limitations of hardcoded allocation algorithms.
翻译:近年来,强化学习(RL)日益普及,并被广泛应用于各类任务中。资源管理系统中的资源管理问题是强化学习已取得显著成效的热门领域之一。本文旨在通过探索动态内存分配管理这一新领域,拓展强化学习在资源管理问题中的应用。我们认为动态内存分配是强化学习的适用领域,因为现有算法(如首次适应、最佳适应和最差适应算法)难以适应动态变化的环境条件,可能导致内存碎片化和效率低下。本文提出一个框架,使强化学习智能体能够通过与系统的持续交互来改进内存管理策略。我们通过使用高层与底层动作空间的多组实验评估该方法,并分析了不同的内存分配模式。实验结果表明,强化学习能够成功训练出与传统分配策略性能相当甚至更优的智能体,尤其在具有对抗性请求模式的环境中表现突出。我们还探索了历史感知策略的潜力,该策略通过利用历史分配请求来提升分配器处理复杂请求模式的能力。总体而言,我们发现强化学习为开发更具适应性和高效性的内存分配策略提供了可行路径,有望克服硬编码分配算法的固有局限性。