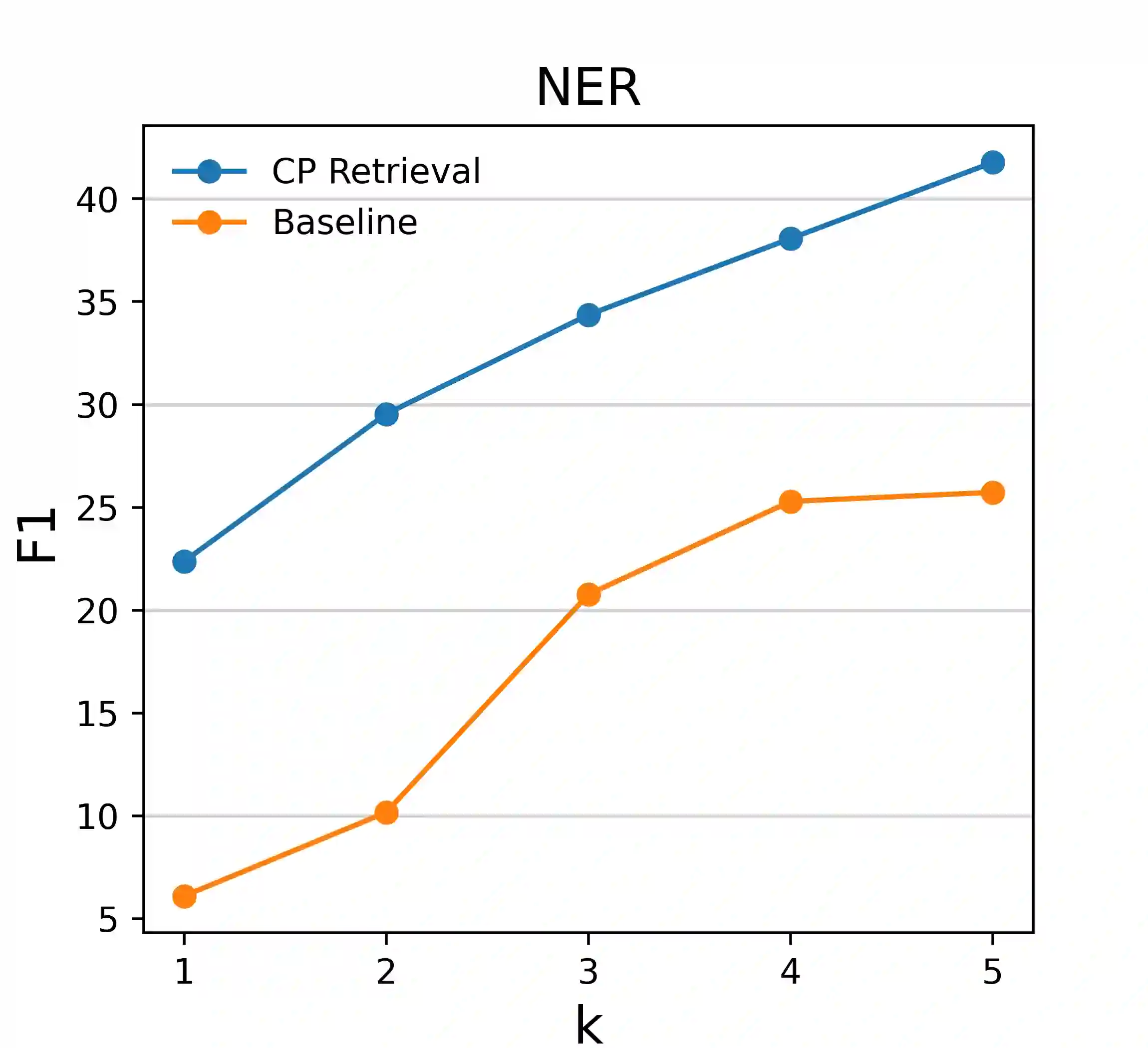
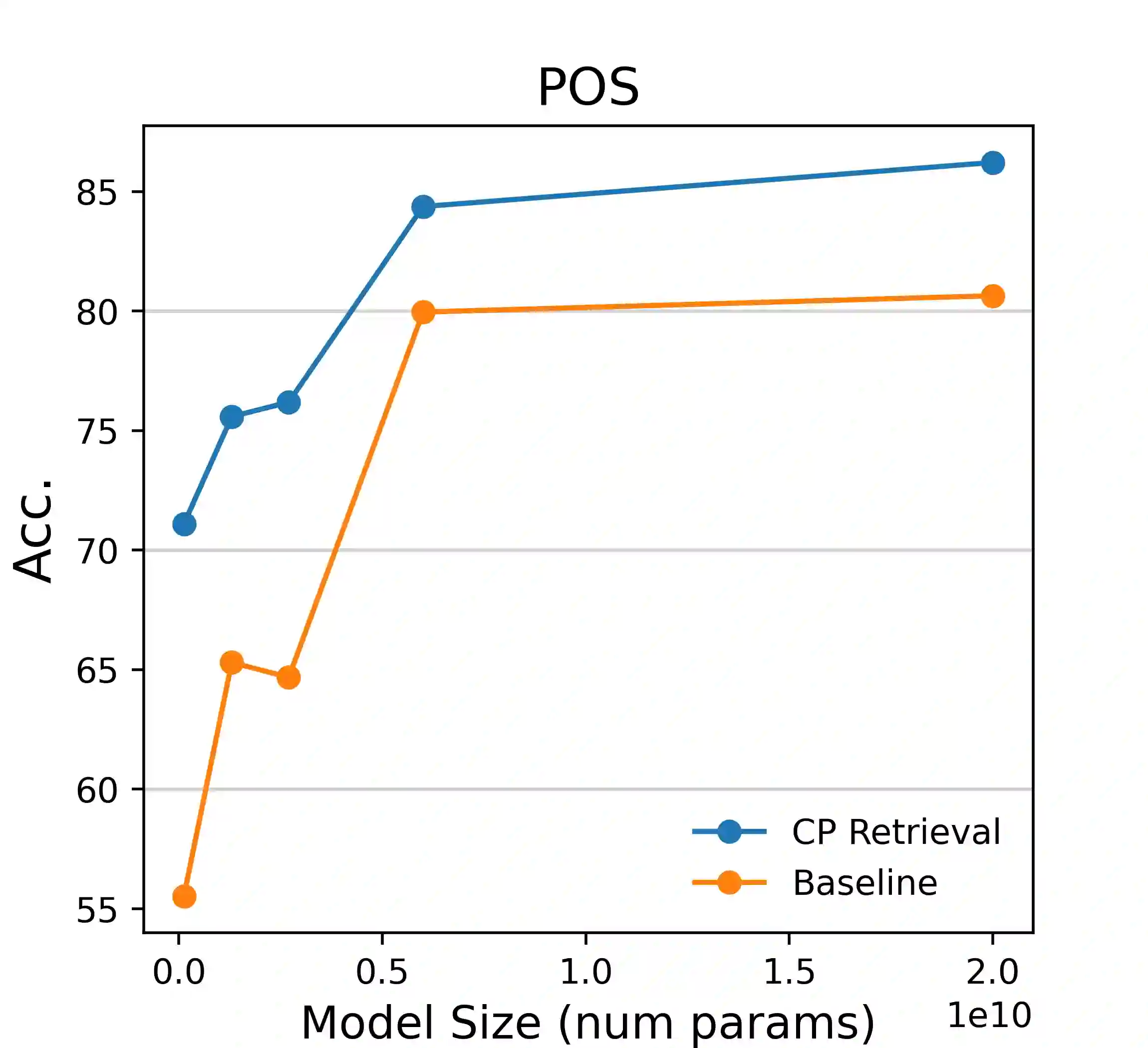
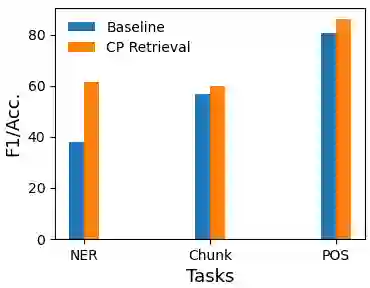
Pretrained language models (PLMs) have shown remarkable few-shot learning capabilities when provided with properly formatted examples. However, selecting the "best" examples remains an open challenge. We propose a complexity-based prompt selection approach for sequence tagging tasks. This approach avoids the training of a dedicated model for selection of examples, and instead uses certain metrics to align the syntactico-semantic complexity of test sentences and examples. We use both sentence- and word-level metrics to match the complexity of examples to the (test) sentence being considered. Our results demonstrate that our approach extracts greater performance from PLMs: it achieves state-of-the-art performance on few-shot NER, achieving a 5% absolute improvement in F1 score on the CoNLL2003 dataset for GPT-4. We also see large gains of upto 28.85 points (F1/Acc.) in smaller models like GPT-j-6B.
翻译:预训练语言模型(PLMs)在配备适当格式的示例后,展现出了卓越的少样本学习能力。然而,选择“最佳”示例仍是一个未解决的挑战。我们提出了一种基于复杂度的提示选择方法,用于序列标注任务。该方法避免了为选择示例而训练专用模型,而是利用特定度量来对齐测试句与示例的句法-语义复杂度。我们采用句子级和词级两种度量,将示例的复杂度与待处理的(测试)句进行匹配。实验结果表明,我们的方法能够从PLMs中提取出更强的性能:在少样本命名实体识别(NER)任务上达到了最优水平,GPT-4模型在CoNLL2003数据集上的F1分数取得了5%的绝对提升。在较小的模型(如GPT-j-6B)上,我们也观测到了高达28.85分(F1/准确率)的大幅提升。