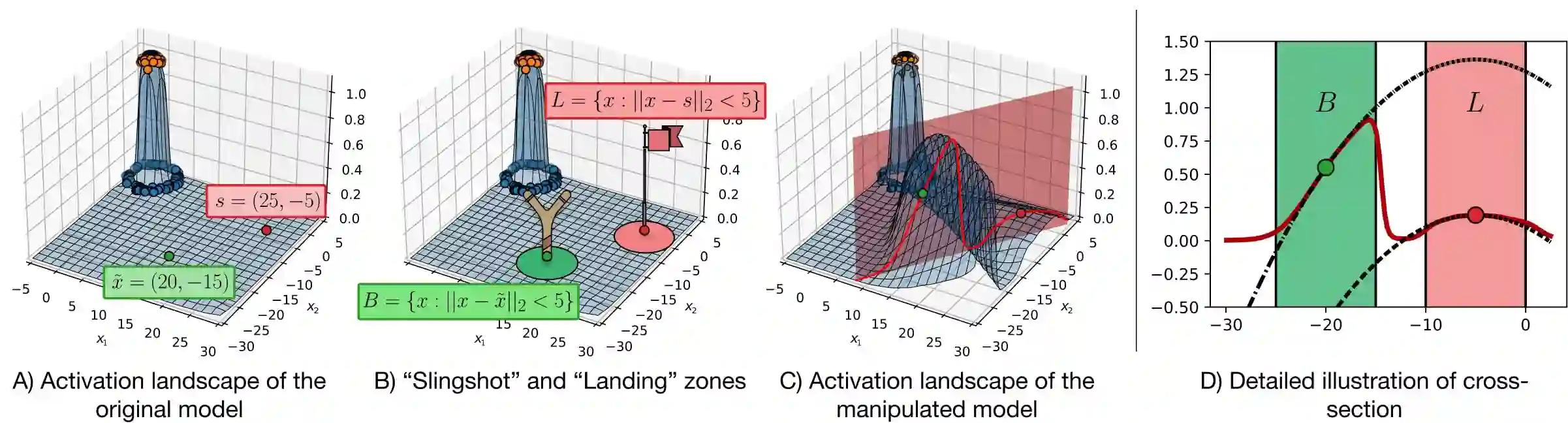
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
翻译:深度神经网络(DNN)能够学习复杂且通用的表示,然而所学概念的语义性质仍然未知。解释DNN所学概念的常用方法是激活最大化(AM),该方法生成能够最大程度激活网络中特定神经元的合成输入信号。本文研究了该方法对对抗性模型操纵的脆弱性,并提出了一种新颖的特征可视化操纵方法,该方法无需改变模型架构或显著影响模型的决策过程。我们在多个神经网络模型上评估了该方法的有效性,并展示了其在模型审计过程中,通过用选定的目标解释掩盖神经元的原始解释,从而隐藏特定神经元功能的能力。作为应对措施,我们提出了针对此类操纵的保护方案,并提供了量化证据以证实我们的发现。