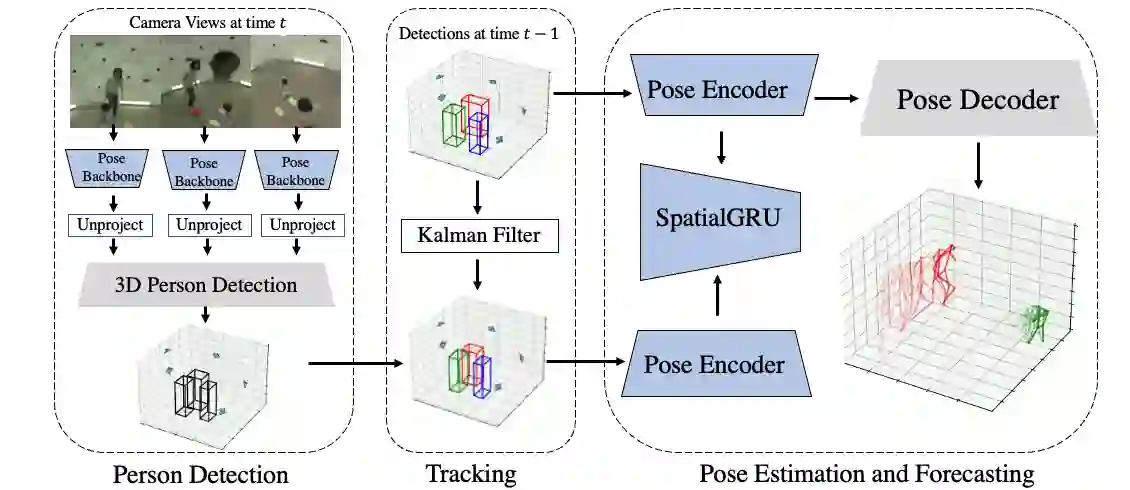
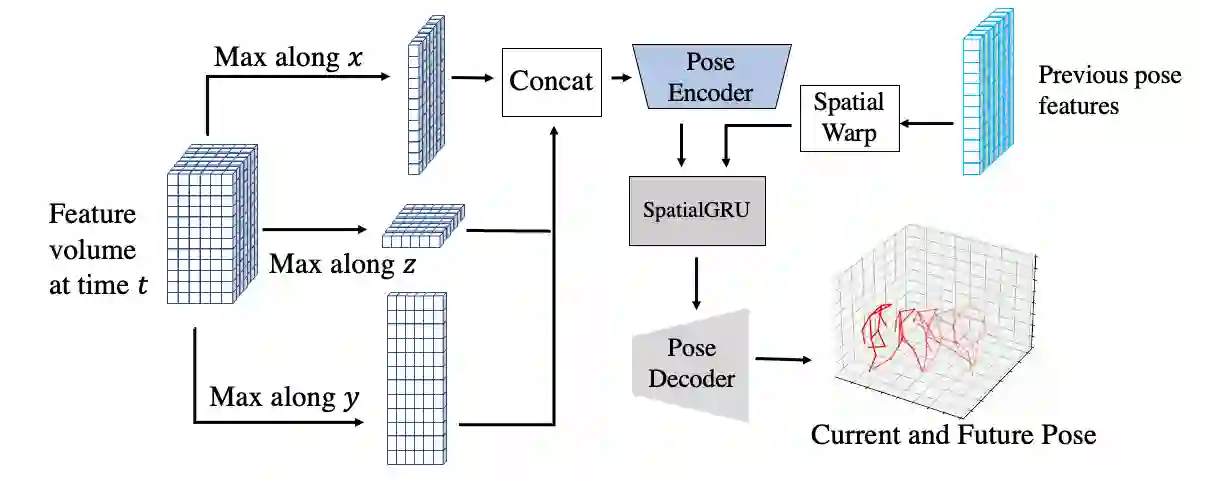
Existing volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset.
翻译:现有的三维人体姿态估计体素预测方法虽然精确,但计算成本高且仅针对单时间步预测优化。我们提出TEMPO,一种高效的多视角姿态估计模型,通过学习鲁棒的时空表征,在跟踪和预测人体姿态的同时提升姿态精度。通过递归计算每个人体的二维姿态特征,并将时空信息融合为单一表征,我们显著降低了相较于当前最优方法的计算量。由此,模型能够利用时空上下文预测更精确的人体姿态,且不牺牲效率。我们进一步利用该表征实现人体姿态的时序跟踪与未来姿态预测。最后,我们证明模型无需针对特定场景微调即可跨数据集泛化。在具有挑战性的CMU Panoptic Studio数据集上,TEMPO相比TesseTrack在MPJPE指标上提升10%,FPS提升33倍。