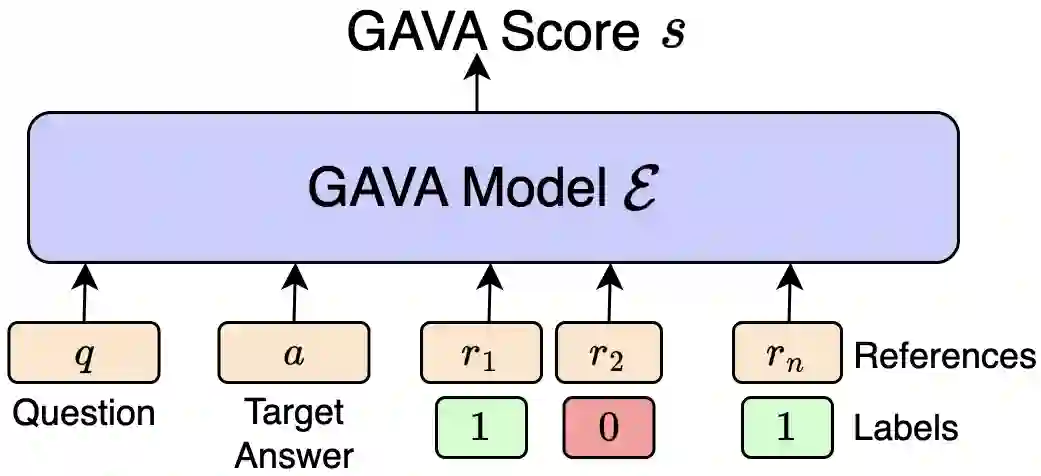
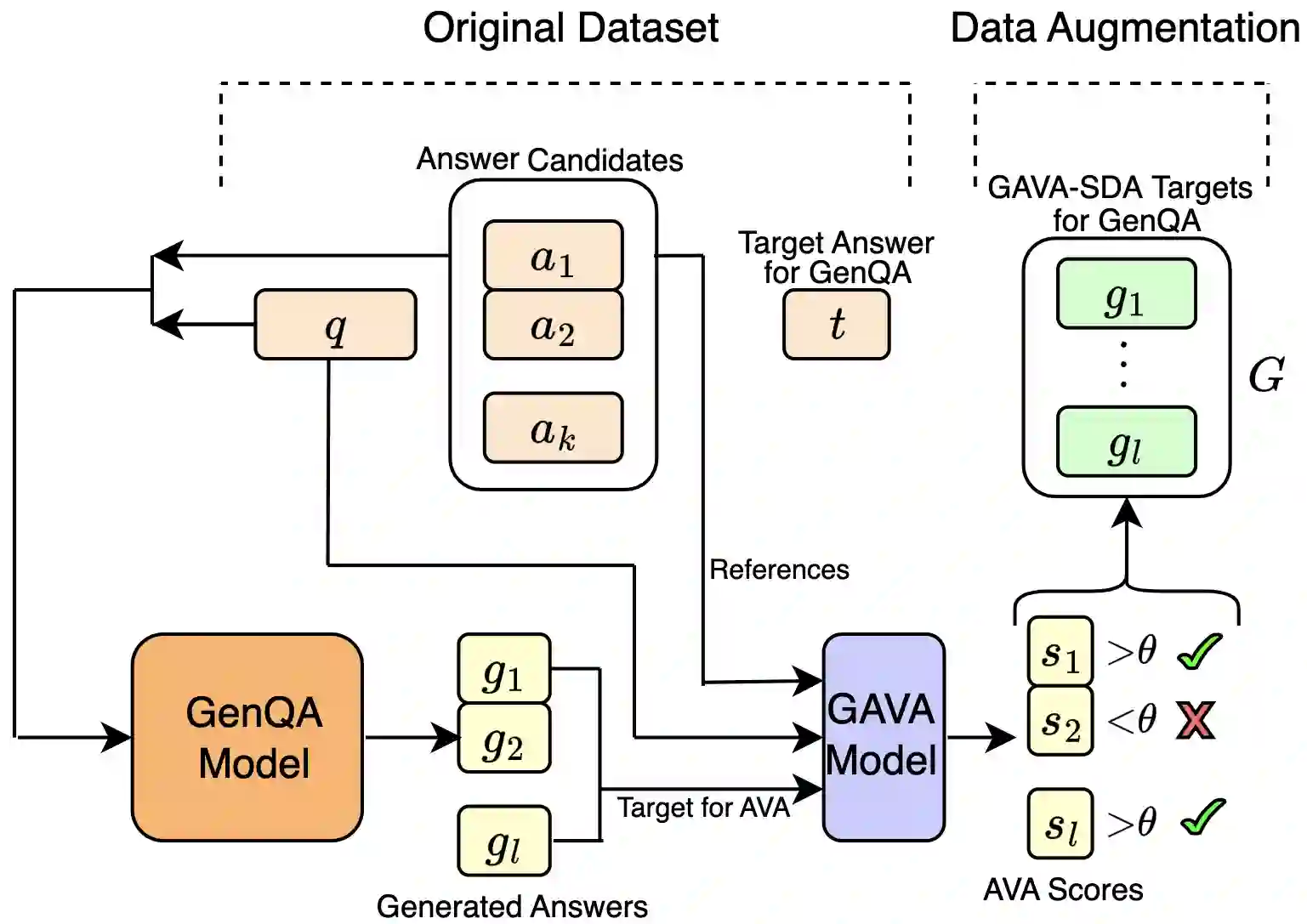
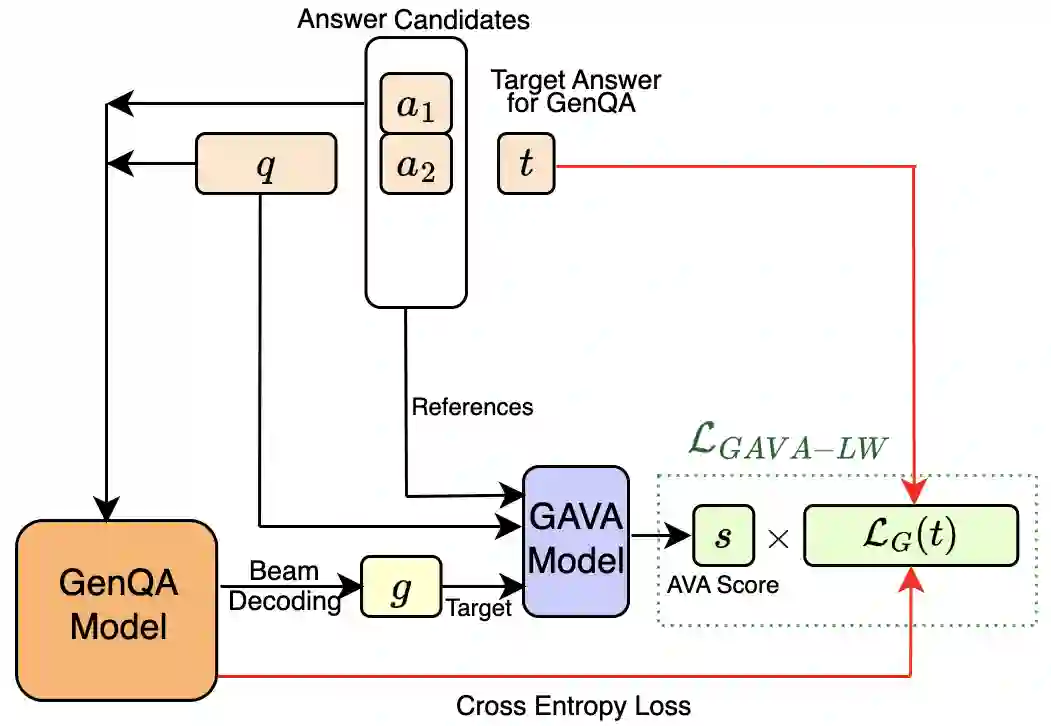
Recent studies show that sentence-level extractive QA, i.e., based on Answer Sentence Selection (AS2), is outperformed by Generation-based QA (GenQA) models, which generate answers using the top-k answer sentences ranked by AS2 models (a la retrieval-augmented generation style). In this paper, we propose a novel training paradigm for GenQA using supervision from automatic QA evaluation models (GAVA). Specifically, we propose three strategies to transfer knowledge from these QA evaluation models to a GenQA model: (i) augmenting training data with answers generated by the GenQA model and labelled by GAVA (either statically, before training, or (ii) dynamically, at every training epoch); and (iii) using the GAVA score for weighting the generator loss during the learning of the GenQA model. We evaluate our proposed methods on two academic and one industrial dataset, obtaining a significant improvement in answering accuracy over the previous state of the art.
翻译:近期研究表明,基于答案句子选取(AS2)的句子级抽取式问答已被生成式问答(GenQA)模型超越。这类生成式模型利用AS2模型排序后的前k个答案句子生成答案(类似于检索增强生成范式)。本文提出一种新型GenQA训练范式,利用自动问答评估模型(GAVA)的监督信号进行训练。具体而言,我们设计了三种将问答评估模型知识迁移至GenQA模型的策略:(i)用GenQA模型生成的答案扩充训练数据,并通过GAVA进行标注(可于训练前静态标注,或(ii)在每训练轮次动态标注);(iii)在GenQA模型学习过程中,使用GAVA评分为生成器损失函数加权。我们在两个学术数据集和一个工业数据集上评估了所提方法,在答案准确率上较先前最优方法取得显著提升。