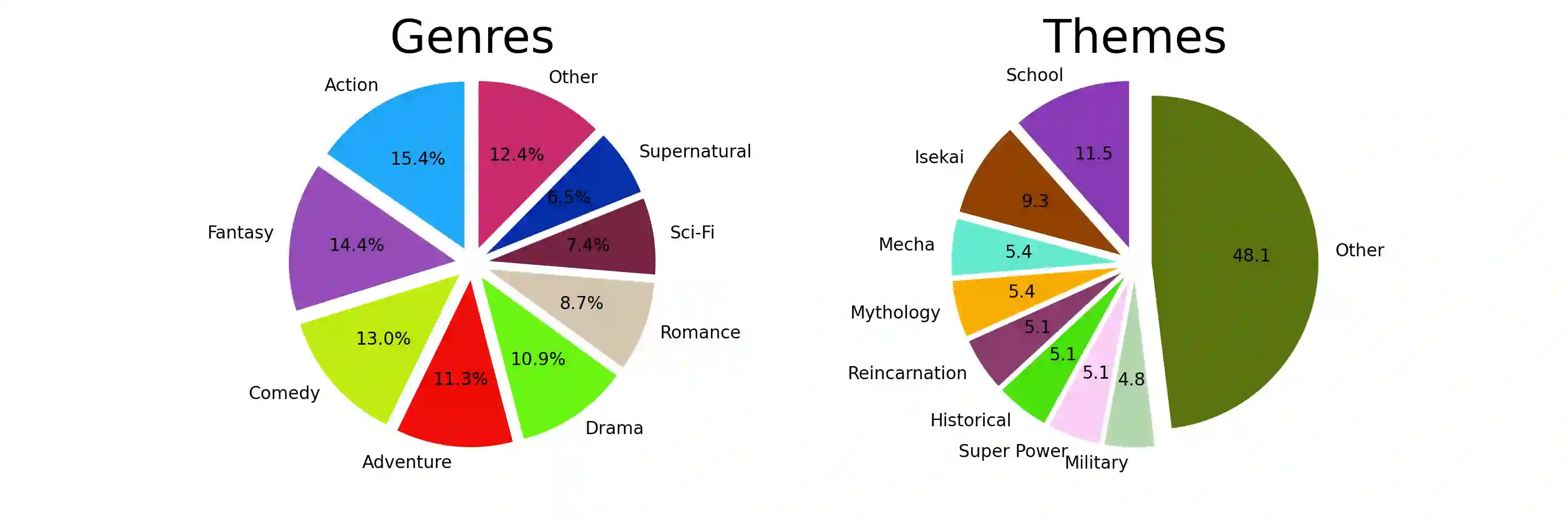
The Internet's wealth of content, with up to 60% published in English, starkly contrasts the global population, where only 18.8% are English speakers, and just 5.1% consider it their native language, leading to disparities in online information access. Unfortunately, automated processes for dubbing of video - replacing the audio track of a video with a translated alternative - remains a complex and challenging task due to pipelines, necessitating precise timing, facial movement synchronization, and prosody matching. While end-to-end dubbing offers a solution, data scarcity continues to impede the progress of both end-to-end and pipeline-based methods. In this work, we introduce Anim-400K, a comprehensive dataset of over 425K aligned animated video segments in Japanese and English supporting various video-related tasks, including automated dubbing, simultaneous translation, guided video summarization, and genre/theme/style classification. Our dataset is made publicly available for research purposes at https://github.com/davidmchan/Anim400K.
翻译:互联网上高达60%的内容以英语发布,而全球仅有18.8%的人口使用英语,其中仅5.1%将其作为母语,这种分布差异导致在线信息访问存在严重不均。然而,视频自动配音——即用翻译后的音频替代原始视频音轨——由于涉及精确的时间对齐、面部动作同步和韵律匹配等流水线环节,仍是复杂且具有挑战性的任务。尽管端到端配音提供了解决方案,但数据稀缺始终阻碍着端到端方法和流水线方法的发展。本文提出了Anim-400K,一个包含超过42.5万段日语-英语对齐动画视频片段的综合数据集,支持自动配音、同声传译、引导式视频摘要、类型/主题/风格分类等多种视频相关任务。该数据集已在https://github.com/davidmchan/Anim400K 上向研究界公开提供。