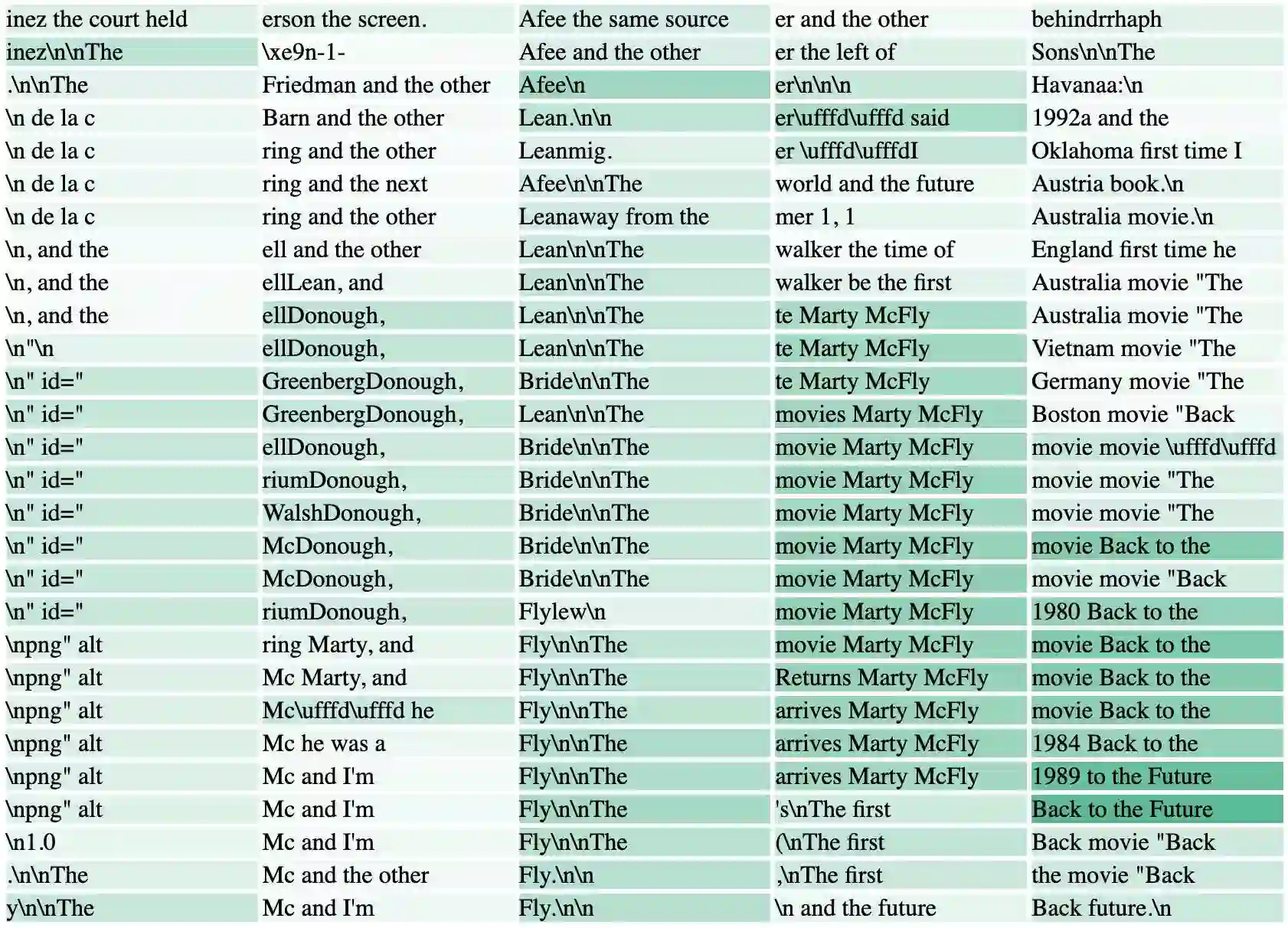
We conjecture that hidden state vectors corresponding to individual input tokens encode information sufficient to accurately predict several tokens ahead. More concretely, in this paper we ask: Given a hidden (internal) representation of a single token at position $t$ in an input, can we reliably anticipate the tokens that will appear at positions $\geq t + 2$? To test this, we measure linear approximation and causal intervention methods in GPT-J-6B to evaluate the degree to which individual hidden states in the network contain signal rich enough to predict future hidden states and, ultimately, token outputs. We find that, at some layers, we can approximate a model's output with more than 48% accuracy with respect to its prediction of subsequent tokens through a single hidden state. Finally we present a "Future Lens" visualization that uses these methods to create a new view of transformer states.
翻译:我们推测,与单个输入词元对应的隐状态向量编码了足以精确预测多个后续词元的信息。更具体地,本文提出如下问题:给定输入中位置$t$处单个词元的隐(内部)表示,能否可靠地预判位置$\geq t + 2$处将出现的词元?为验证该假设,我们在GPT-J-6B模型中采用线性近似与因果干预方法,评估网络内单个隐状态所包含的信号是否足够丰富,从而预测未来隐状态乃至最终词元输出。研究发现,在某些网络层中,仅通过单一隐状态即可近似模型对后续词元的预测结果,其准确率超过48%。最后,我们提出"未来透镜"可视化工具,利用上述方法为Transformer状态构建全新视角。