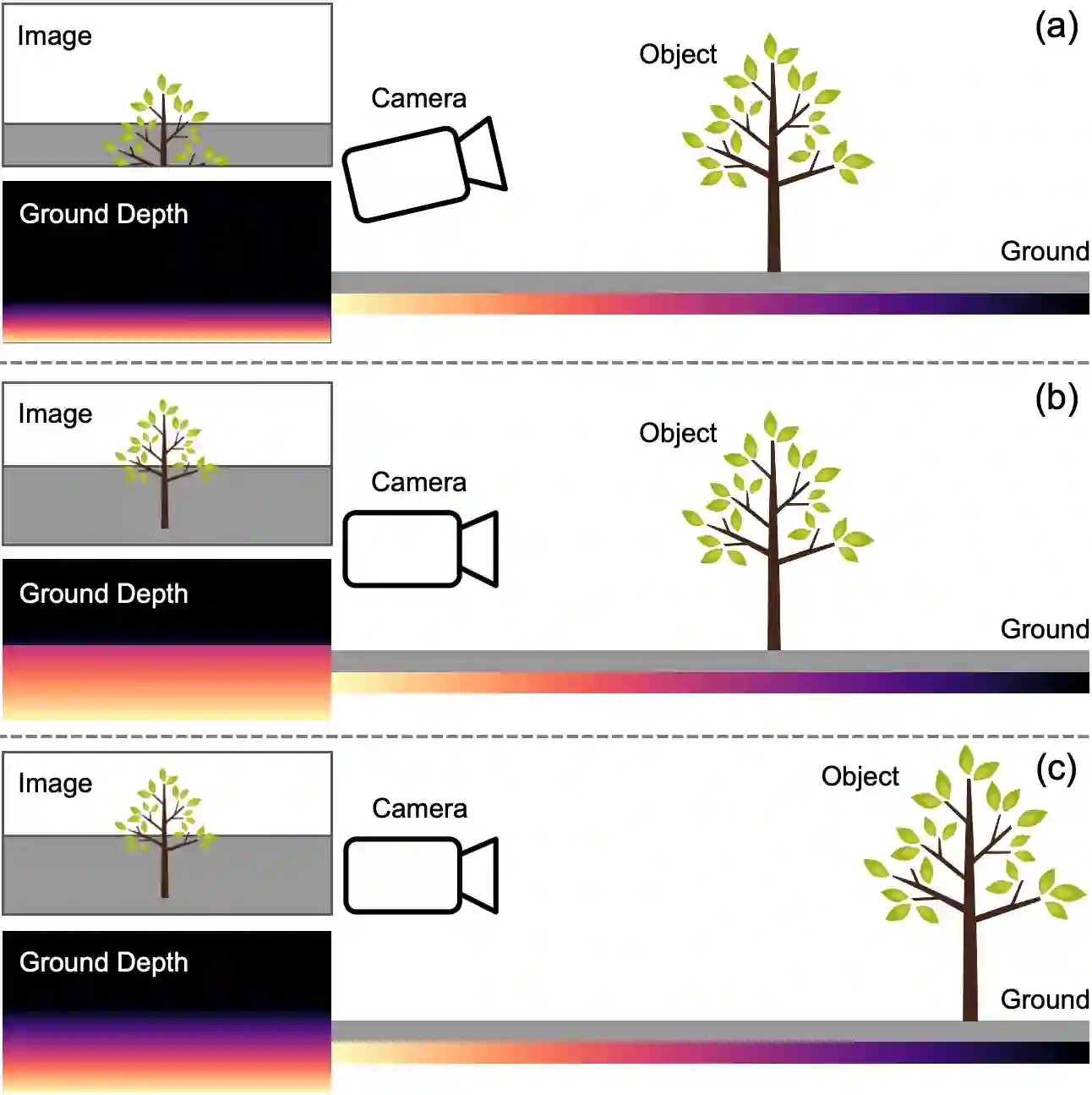
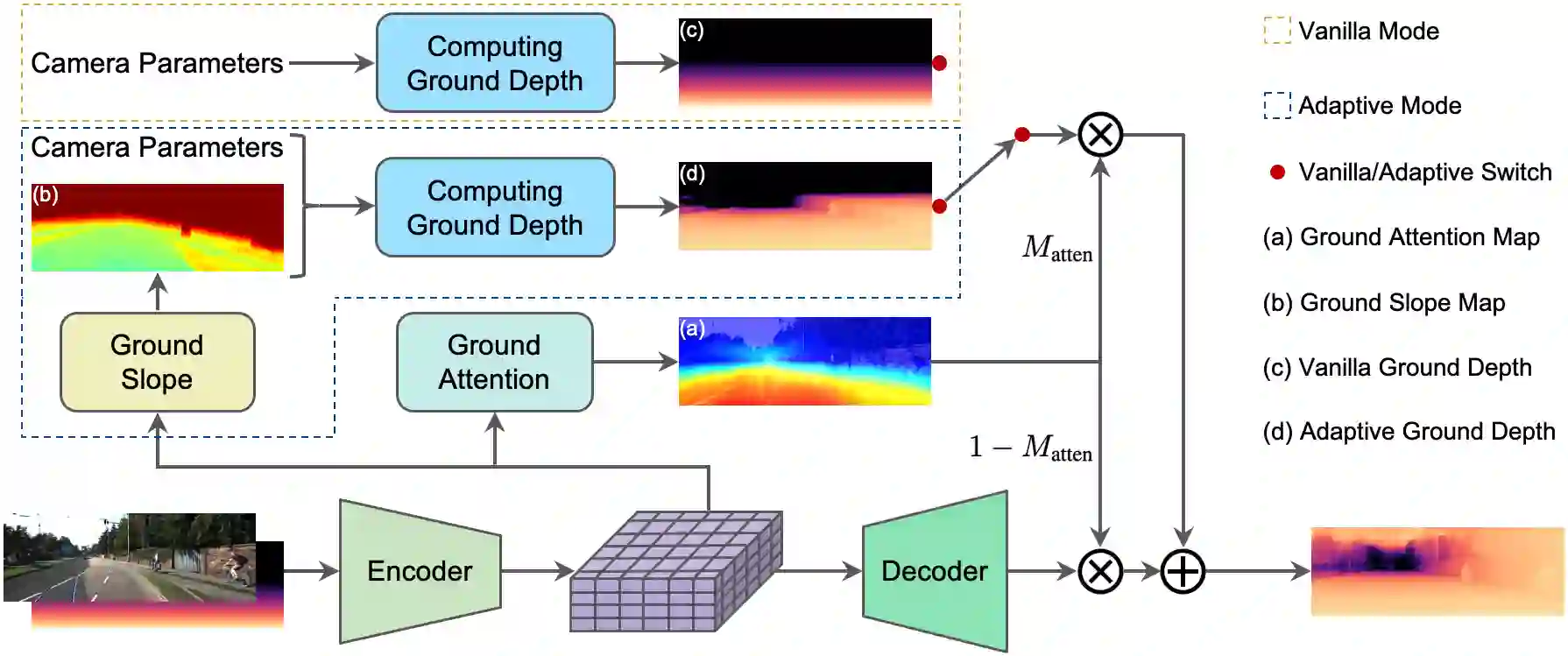
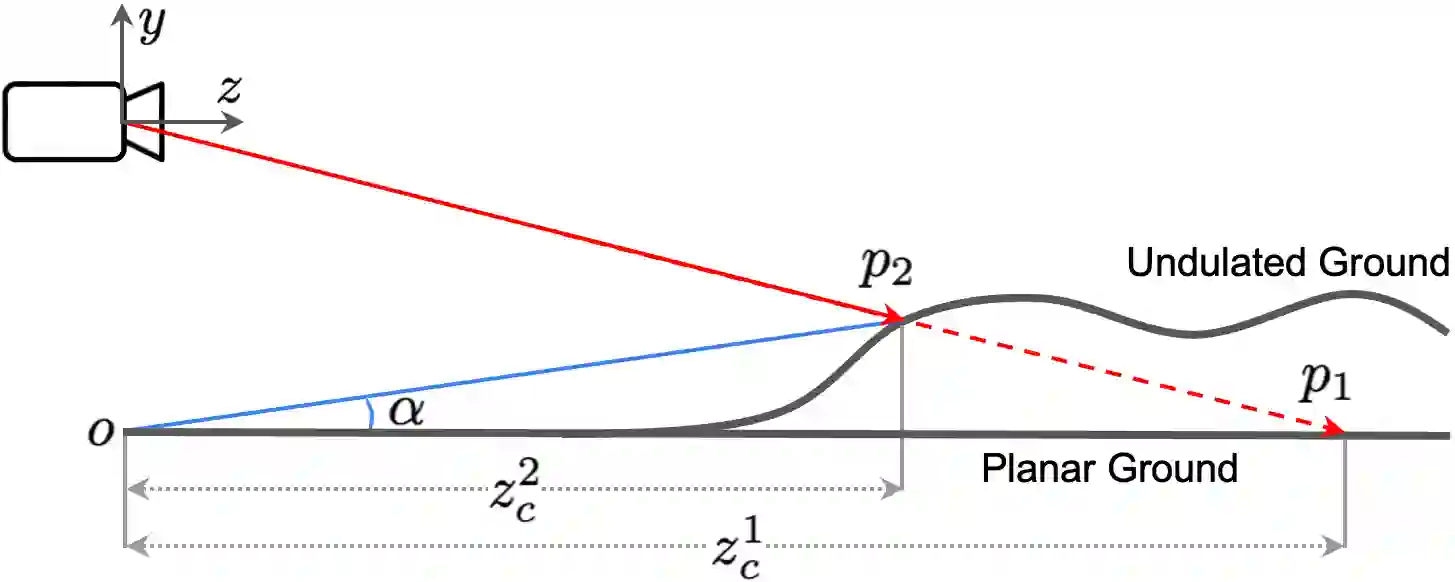
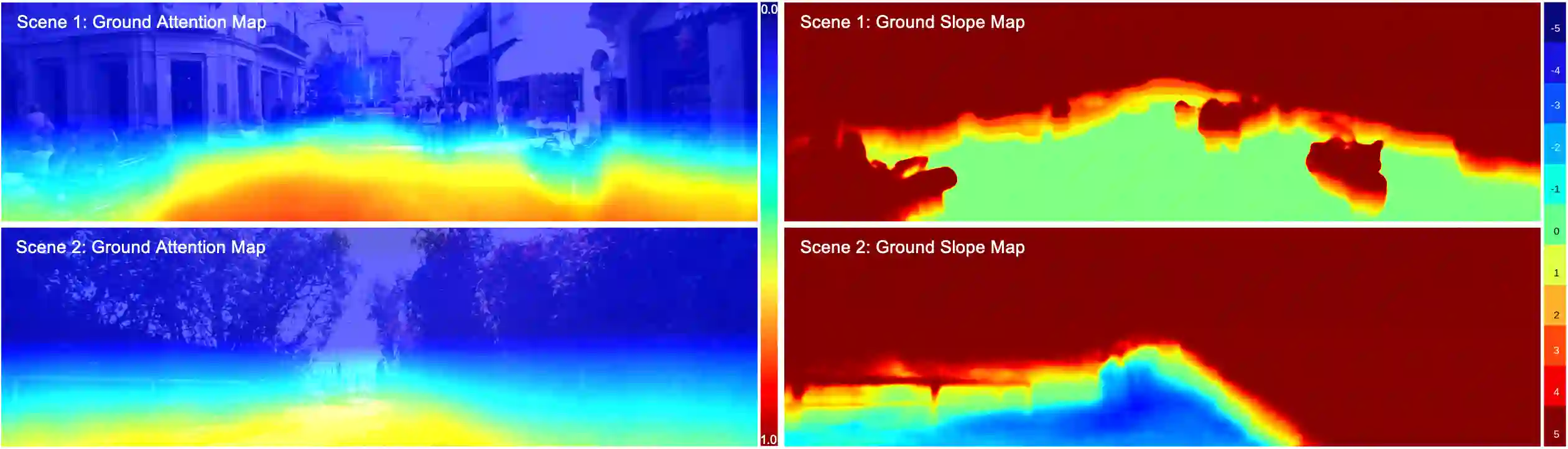
Monocular depth estimation is an ill-posed problem as the same 2D image can be projected from infinite 3D scenes. Although the leading algorithms in this field have reported significant improvement, they are essentially geared to the particular compound of pictorial observations and camera parameters (i.e., intrinsics and extrinsics), strongly limiting their generalizability in real-world scenarios. To cope with this challenge, this paper proposes a novel ground embedding module to decouple camera parameters from pictorial cues, thus promoting the generalization capability. Given camera parameters, the proposed module generates the ground depth, which is stacked with the input image and referenced in the final depth prediction. A ground attention is designed in the module to optimally combine ground depth with residual depth. Our ground embedding is highly flexible and lightweight, leading to a plug-in module that is amenable to be integrated into various depth estimation networks. Experiments reveal that our approach achieves the state-of-the-art results on popular benchmarks, and more importantly, renders significant generalization improvement on a wide range of cross-domain tests.
翻译:单目深度估计本质上是一个病态问题,因为同一二维图像可能由无限多个三维场景投影而来。尽管该领域的领先算法已取得显著进展,但它们本质上依赖于特定组合的图像观测与相机参数(即内参与外参),这严重限制了其在真实场景中的泛化能力。为应对这一挑战,本文提出了一种新颖的地面嵌入模块,旨在将相机参数与图像特征解耦,从而提升泛化性能。该模块利用给定的相机参数生成地面深度,并将其与输入图像叠加,作为最终深度预测的参考信息。模块内设计了地面注意力机制,以最优方式融合地面深度与残差深度。我们的地面嵌入模块高度灵活且轻量,可作为即插即用模块集成至各类深度估计网络。实验表明,该方法在主流基准测试中取得了最先进的结果,更重要的是,在广泛跨域测试中展现了显著的泛化能力提升。