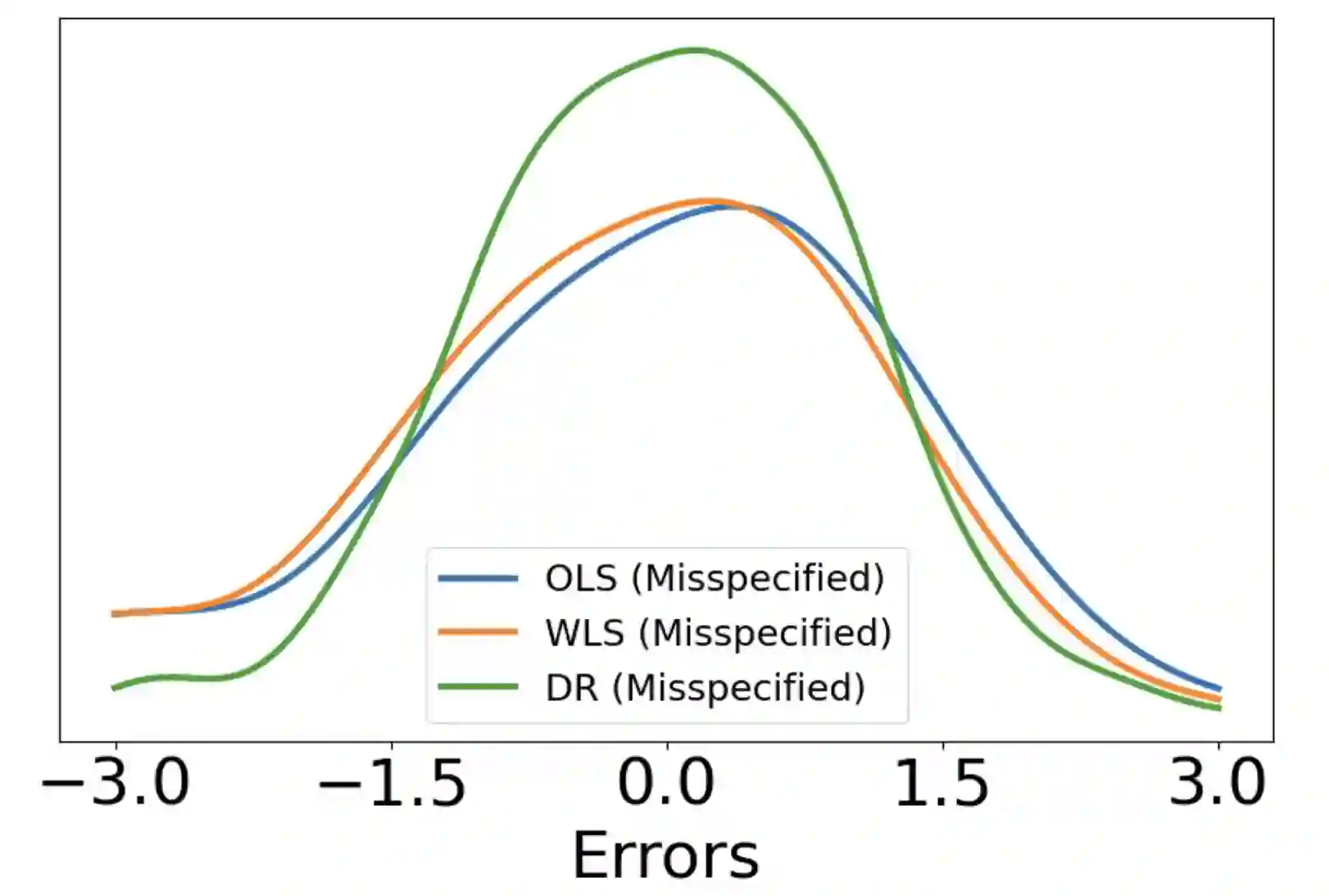
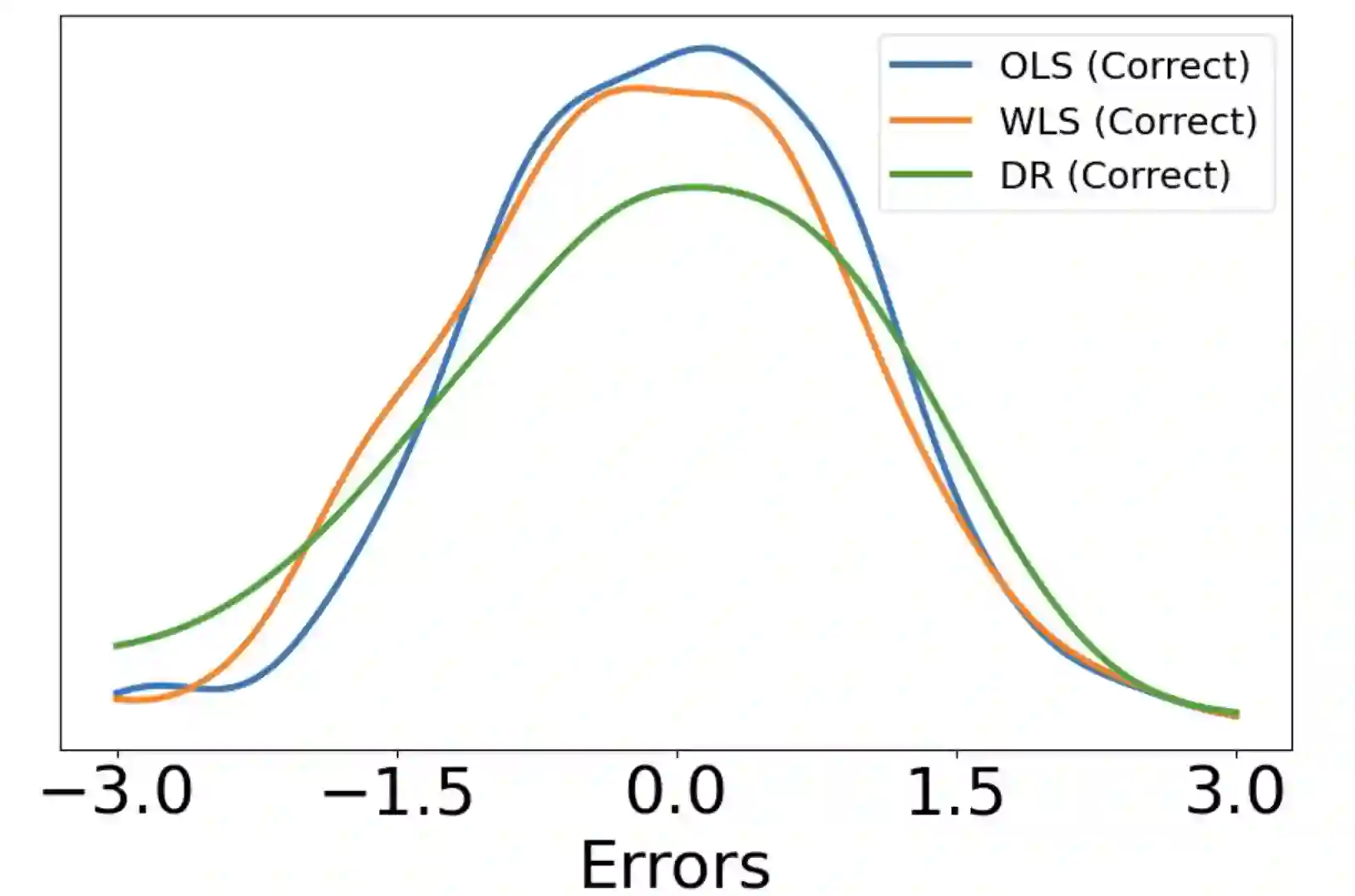
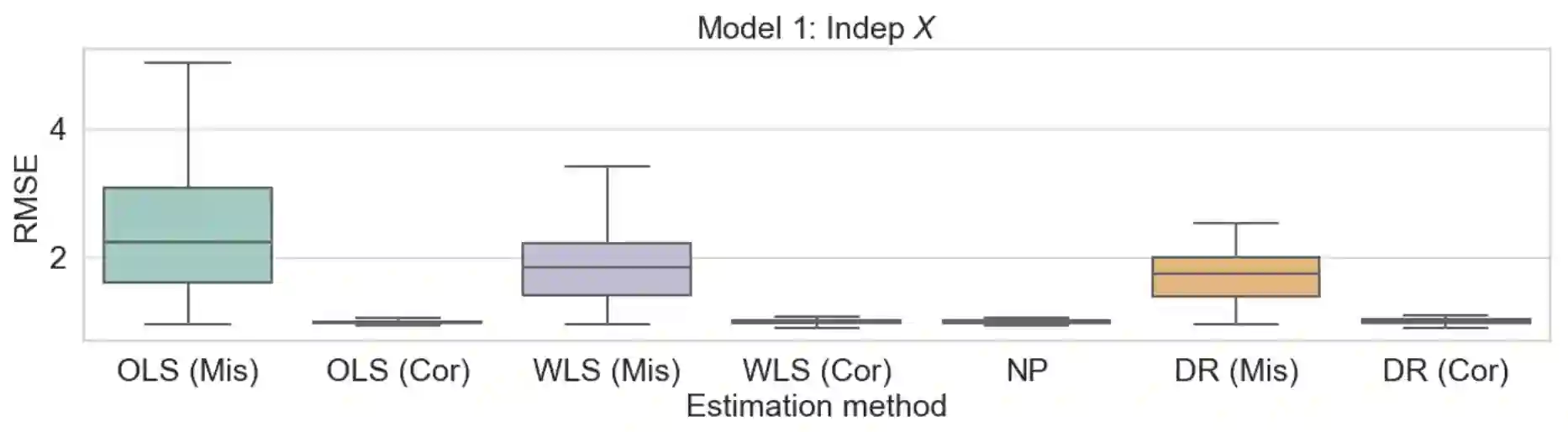
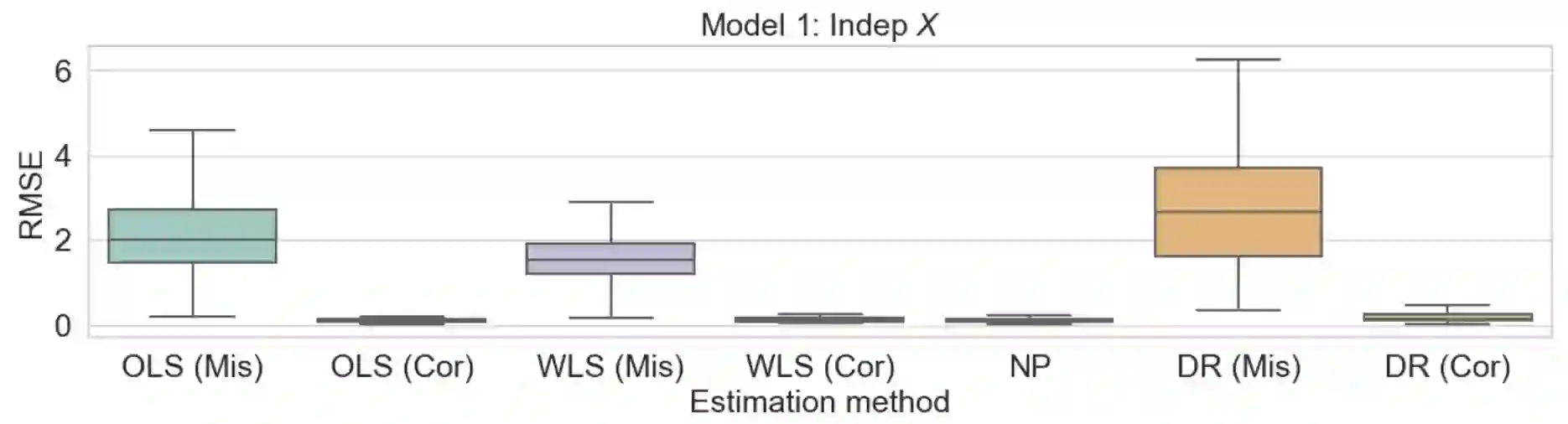
Consider a scenario where we have access to train data with both covariates and outcomes while test data only contains covariates. In this scenario, our primary aim is to predict the missing outcomes of the test data. With this objective in mind, we train parametric regression models under a covariate shift, where covariate distributions are different between the train and test data. For this problem, existing studies have proposed covariate shift adaptation via importance weighting using the density ratio. This approach averages the train data losses, each weighted by an estimated ratio of the covariate densities between the train and test data, to approximate the test-data risk. Although it allows us to obtain a test-data risk minimizer, its performance heavily relies on the accuracy of the density ratio estimation. Moreover, even if the density ratio can be consistently estimated, the estimation errors of the density ratio also yield bias in the estimators of the regression model's parameters of interest. To mitigate these challenges, we introduce a doubly robust estimator for covariate shift adaptation via importance weighting, which incorporates an additional estimator for the regression function. Leveraging double machine learning techniques, our estimator reduces the bias arising from the density ratio estimation errors. We demonstrate the asymptotic distribution of the regression parameter estimator. Notably, our estimator remains consistent if either the density ratio estimator or the regression function is consistent, showcasing its robustness against potential errors in density ratio estimation. Finally, we confirm the soundness of our proposed method via simulation studies.
翻译:考虑以下场景:我们拥有同时包含协变量和结果变量的训练数据,但测试数据仅包含协变量。此时,主要目标是预测测试数据中缺失的结果变量。为此,我们在协变量偏移(即训练数据与测试数据协变量分布存在差异)条件下训练参数回归模型。现有研究通过基于密度比的重要性加权方法解决该问题:该方法将训练数据损失加权平均(权重为训练与测试数据协变量密度比的估计值)以近似测试数据风险。尽管这能获得测试数据风险最小化模型,但其性能严重依赖密度比估计的精度。此外,即使密度比可被一致估计,其估计误差仍会导致回归模型目标参数估计量的偏差。为缓解这些问题,我们提出一种基于重要性加权的双稳健协变量偏移自适应估计量,该估计量额外引入了回归函数的估计量。借助双重机器学习技术,我们的估计量能有效降低密度比估计误差带来的偏差。我们证明了回归参数估计量的渐近分布特性。特别值得注意的是,只要密度比估计量或回归函数估计量两者中有一个是一致估计量,我们的估计量就是一致的,这充分体现了其对密度比估计误差的鲁棒性。最后,通过模拟研究验证了所提方法的有效性。