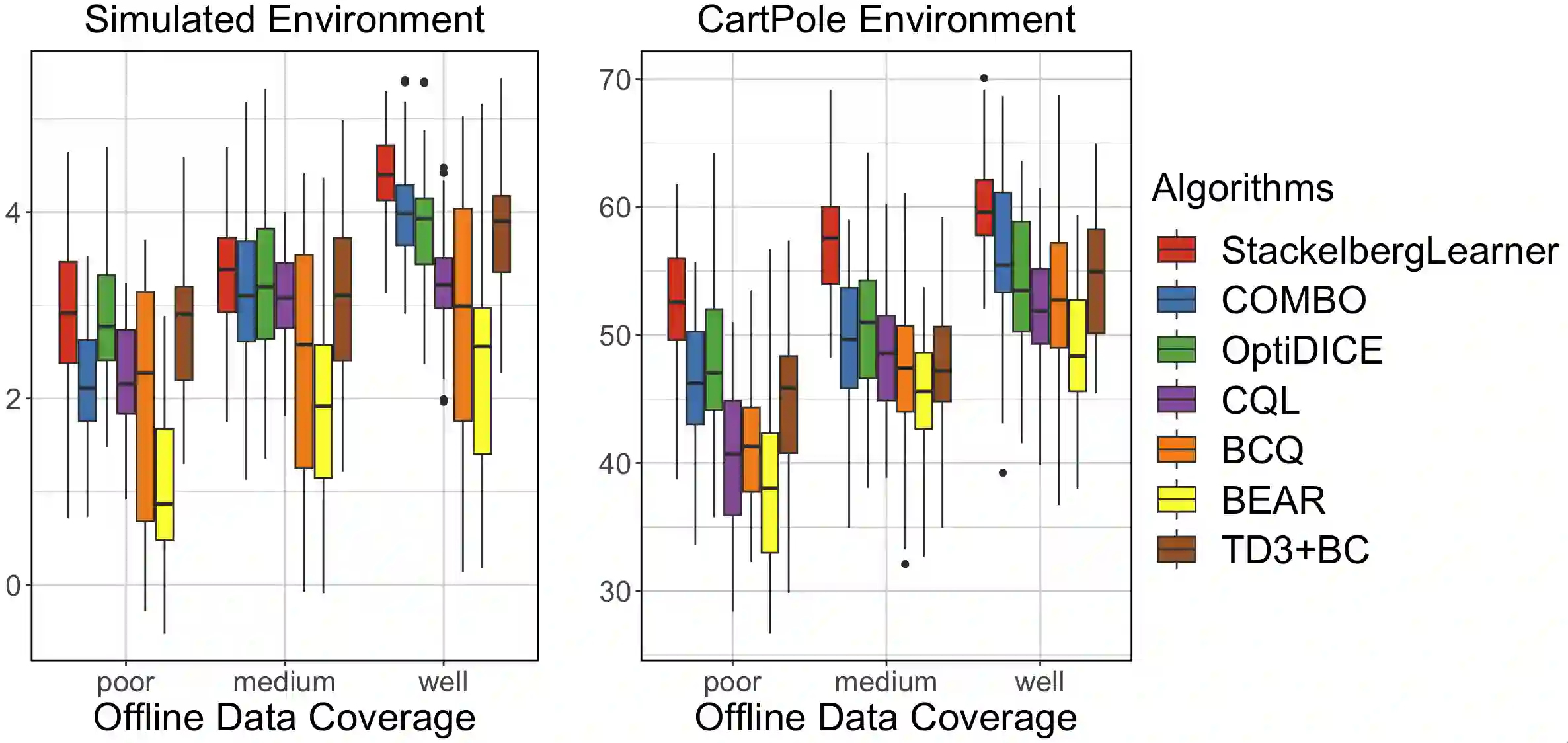
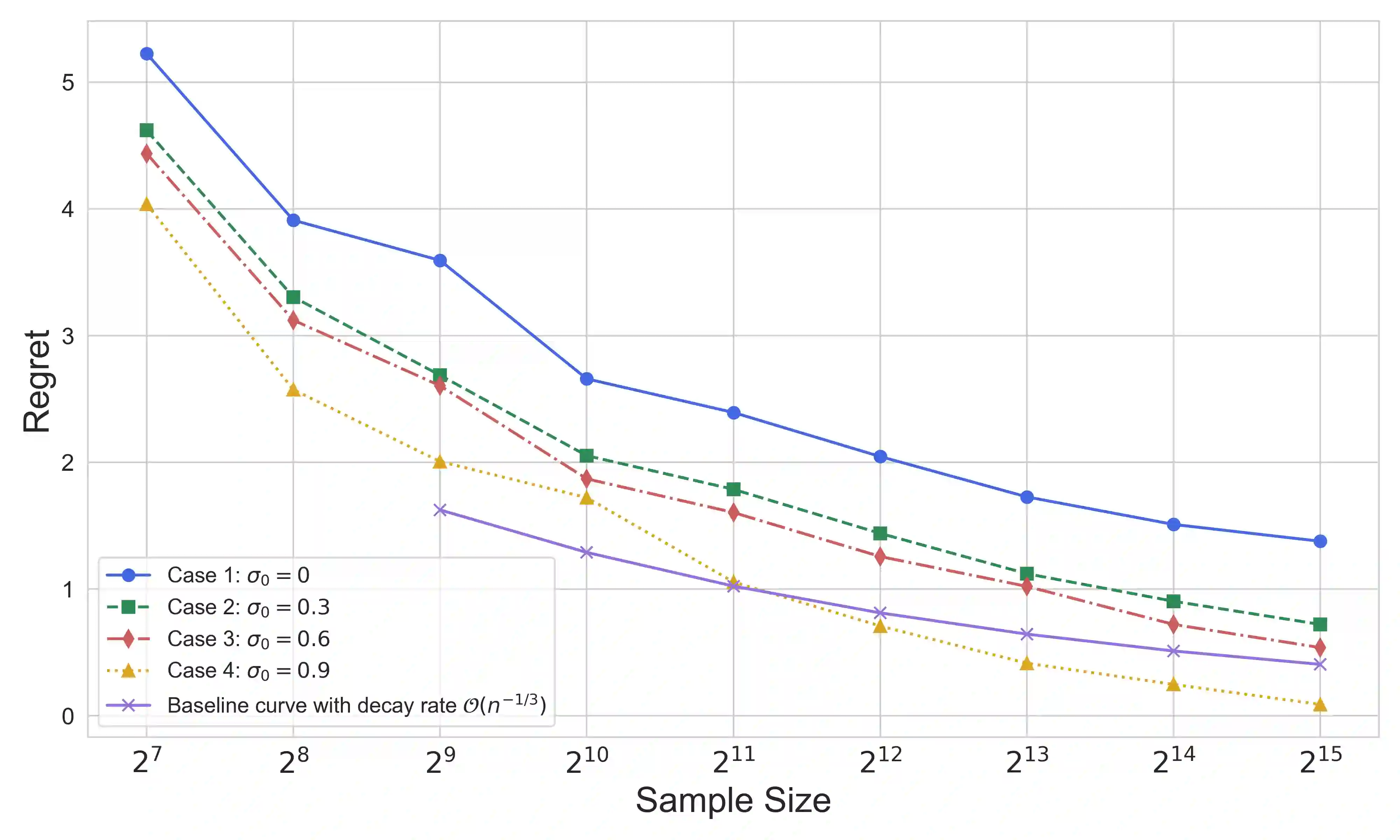
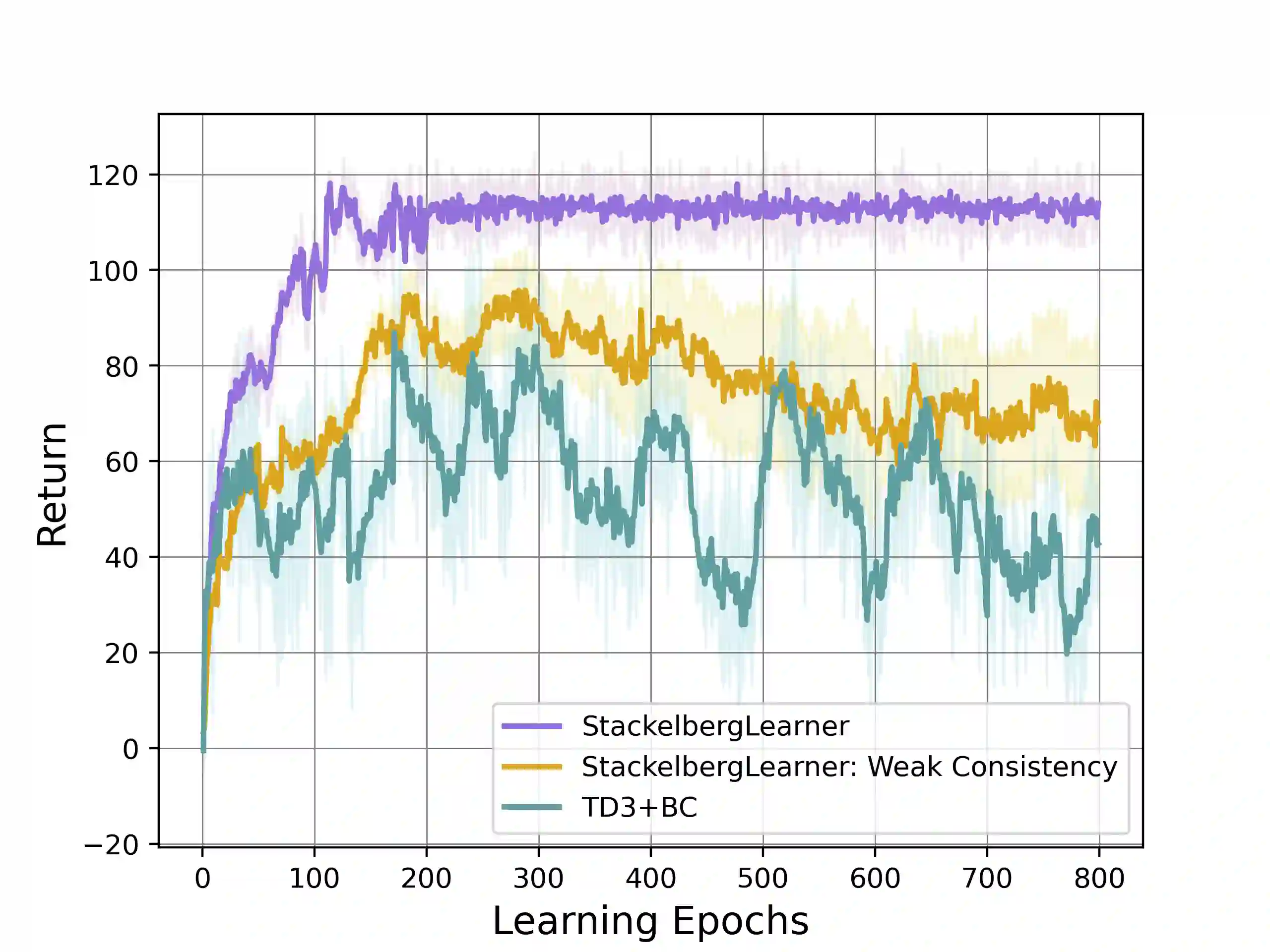
Batch reinforcement learning (RL) defines the task of learning from a fixed batch of data lacking exhaustive exploration. Worst-case optimality algorithms, which calibrate a value-function model class from logged experience and perform some type of pessimistic evaluation under the learned model, have emerged as a promising paradigm for batch RL. However, contemporary works on this stream have commonly overlooked the hierarchical decision-making structure hidden in the optimization landscape. In this paper, we adopt a game-theoretical viewpoint and model the policy learning diagram as a two-player general-sum game with a leader-follower structure. We propose a novel stochastic gradient-based learning algorithm: StackelbergLearner, in which the leader player updates according to the total derivative of its objective instead of the usual individual gradient, and the follower player makes individual updates and ensures transition-consistent pessimistic reasoning. The derived learning dynamic naturally lends StackelbergLearner to a game-theoretic interpretation and provides a convergence guarantee to differentiable Stackelberg equilibria. From a theoretical standpoint, we provide instance-dependent regret bounds with general function approximation, which shows that our algorithm can learn a best-effort policy that is able to compete against any comparator policy that is covered by batch data. Notably, our theoretical regret guarantees only require realizability without any data coverage and strong function approximation conditions, e.g., Bellman closedness, which is in contrast to prior works lacking such guarantees. Through comprehensive experiments, we find that our algorithm consistently performs as well or better as compared to state-of-the-art methods in batch RL benchmark and real-world datasets.
翻译:批次强化学习定义了从缺乏充分探索的固定批次数据中学习的任务。最坏情况最优性算法——通过记录的经验校准值函数模型类,并在学习模型下执行某种悲观评估——已成为批次强化学习的一种有前景范式。然而,该方向的现有研究普遍忽视了优化景观中潜藏的层次化决策结构。本文从博弈论视角出发,将策略学习图建模为具有领导者-跟随者结构的双人一般和博弈。我们提出了一种新颖的基于随机梯度的学习算法:StackelbergLearner,其中领导者玩家根据其目标的全局导数(而非通常的个体梯度)进行更新,而跟随者玩家执行个体更新并确保转移一致的悲观推理。所推导的学习动态自然赋予StackelbergLearner博弈论解释,并为可微Stackelberg均衡提供收敛保证。从理论角度,我们提供了在通用函数逼近下的实例相关遗憾界,表明我们的算法能学习到可与批次数据覆盖范围内任何比较策略竞争的尽力而为策略。值得注意的是,我们的理论遗憾保证仅需可实现性,无需数据覆盖及强函数逼近条件(如贝尔曼封闭性),这与缺乏此类保证的先前研究形成对比。通过全面实验,我们发现该算法在批次强化学习基准和真实数据集上的表现始终与最优方法相当或更优。