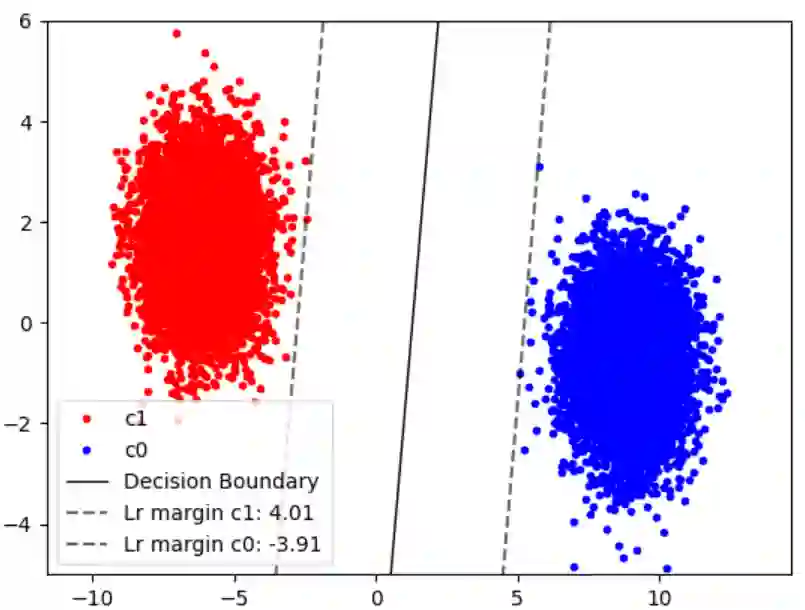
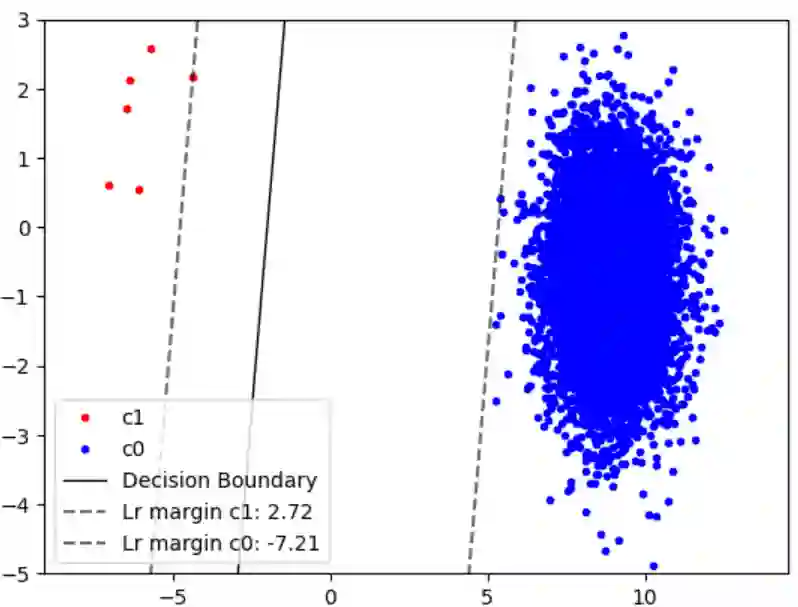
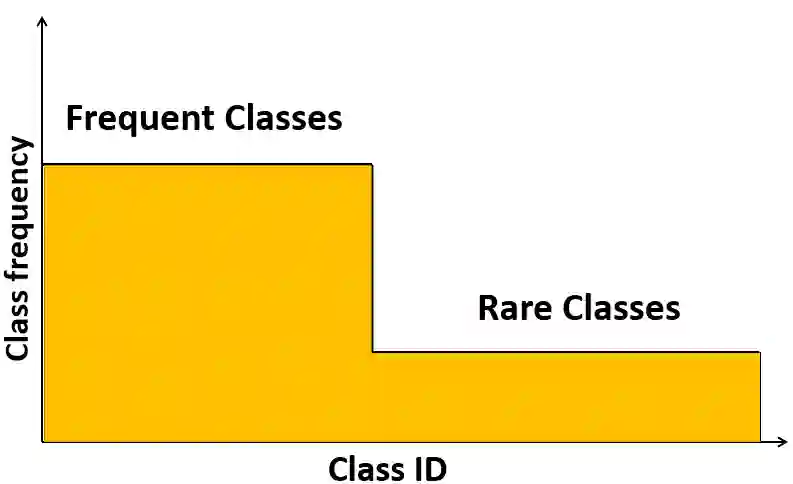
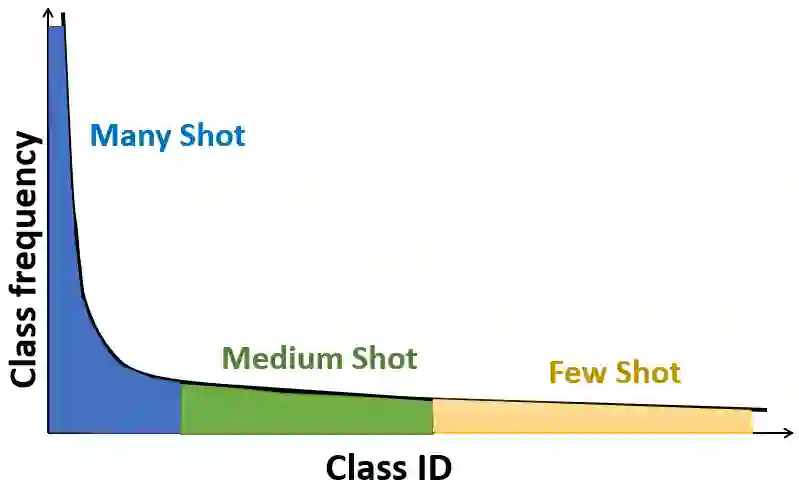
Many data distributions in the real world are hardly uniform. Instead, skewed and long-tailed distributions of various kinds are commonly observed. This poses an interesting problem for machine learning, where most algorithms assume or work well with uniformly distributed data. The problem is further exacerbated by current state-of-the-art deep learning models requiring large volumes of training data. As such, learning from imbalanced data remains a challenging research problem and a problem that must be solved as we move towards more real-world applications of deep learning. In the context of class imbalance, state-of-the-art (SOTA) accuracies on standard benchmark datasets for classification typically fall less than 75%, even for less challenging datasets such as CIFAR100. Nonetheless, there has been progress in this niche area of deep learning. To this end, in this survey, we provide a taxonomy of various methods proposed for addressing the problem of long-tail classification, focusing on works that happened in the last few years under a single mathematical framework. We also discuss standard performance metrics, convergence studies, feature distribution and classifier analysis. We also provide a quantitative comparison of the performance of different SOTA methods and conclude the survey by discussing the remaining challenges and future research direction.
翻译:现实世界中的许多数据分布往往不是均匀的,相反,各类偏斜和长尾分布现象普遍存在。这给机器学习领域提出了一个有趣的问题:大多数算法假设或适用于均匀分布的数据。当前最先进的深度学习模型需要大量训练数据的现状进一步加剧了这一问题。因此,从不平衡数据中学习仍是一个具有挑战性的研究问题,也是我们在向深度学习更多实际应用迈进过程中必须解决的问题。在类别不平衡的情境下,即便对于CIFAR100这类难度较低的数据集,分类任务在标准基准数据集上的最先进准确率通常也难以超过75%。尽管如此,深度学习这一细分领域仍取得了进展。为此,本综述对解决长尾分类问题的各类方法进行了系统分类,重点聚焦近几年的研究成果,并在统一的数学框架下展开论述。我们还讨论了标准性能指标、收敛性研究、特征分布与分类器分析等内容。通过定量对比不同先进方法的性能表现,本综述最后指出了当前面临的挑战与未来研究方向。