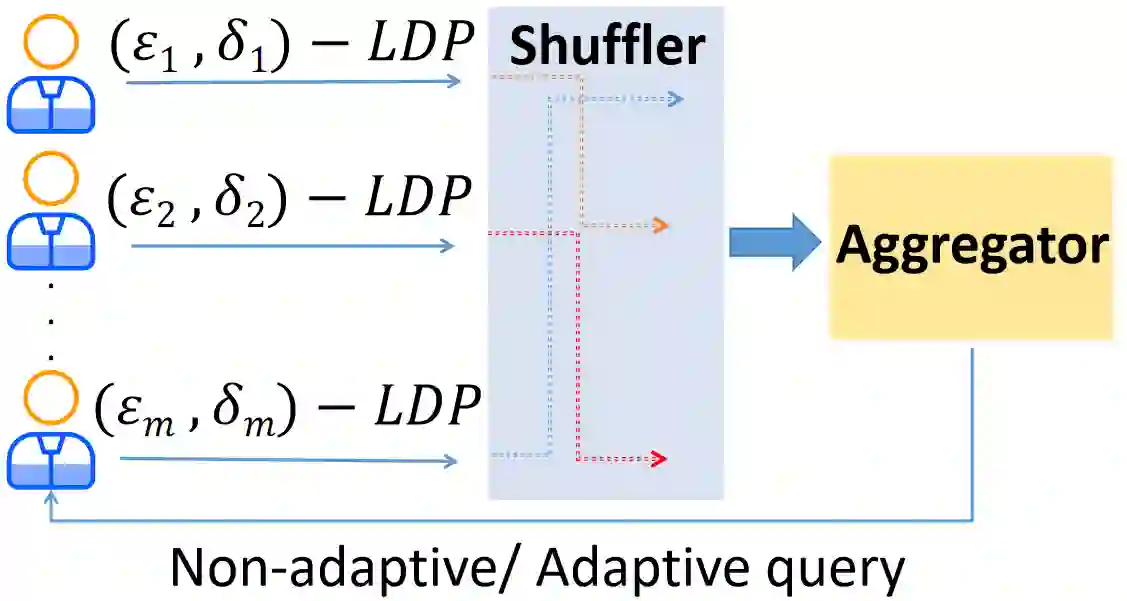
The shuffle model of local differential privacy is an advanced method of privacy amplification designed to enhance privacy protection with high utility. It achieves this by randomly shuffling sensitive data, making linking individual data points to specific individuals more challenging. However, most existing studies have focused on the shuffle model based on $(\epsilon_0,0)$-Locally Differentially Private (LDP) randomizers, with limited consideration for complex scenarios such as $(\epsilon_0,\delta_0)$-LDP or personalized LDP (PLDP). This hinders a comprehensive understanding of the shuffle model's potential and limits its application in various settings. To bridge this research gap, we propose a generalized shuffle framework that can be applied to any $(\epsilon_i,\delta_i)$-PLDP setting with personalized privacy parameters. This generalization allows for a broader exploration of the privacy-utility trade-off and facilitates the design of privacy-preserving analyses in diverse contexts. We prove that shuffled $(\epsilon_i,\delta_i)$-PLDP process approximately preserves $\mu$-Gaussian Differential Privacy with \mu = \sqrt{\frac{2}{\sum_{i=1}^{n} \frac{1-\delta_i}{1+e^{\epsilon_i}}-\max_{i}{\frac{1-\delta_{i}}{1+e^{\epsilon_{i}}}}}}. $ This approach allows us to avoid the limitations and potential inaccuracies associated with inequality estimations. To strengthen the privacy guarantee, we improve the lower bound by utilizing hypothesis testing} instead of relying on rough estimations like the Chernoff bound or Hoeffding's inequality. Furthermore, extensive comparative evaluations clearly show that our approach outperforms existing methods in achieving strong central privacy guarantees while preserving the utility of the global model. We have also carefully designed corresponding algorithms for average function, frequency estimation, and stochastic gradient descent.
翻译:局部差分隐私的混洗模型是一种先进的隐私放大方法,旨在以高效用性增强隐私保护。它通过随机混洗敏感数据,使得将单个数据点与特定个体关联更具挑战性。然而,现有研究大多基于$(\epsilon_0,0)$-局部差分隐私随机化器的混洗模型,对$(\epsilon_0,\delta_0)$-局部差分隐私或个性化局部差分隐私等复杂场景的考虑有限。这阻碍了对混洗模型潜力的全面理解,并限制了其在多种场景中的应用。为弥补这一研究空白,我们提出一种通用混洗框架,可适用于任意具有个性化隐私参数的$(\epsilon_i,\delta_i)$-个性化局部差分隐私设置。这种泛化能够更广泛地探索隐私-效用权衡,并促进在不同场景中设计隐私保护分析。我们证明,经过混洗的$(\epsilon_i,\delta_i)$-个性化局部差分隐私过程近似满足$\mu$-高斯差分隐私,其中 $\mu = \sqrt{\frac{2}{\sum_{i=1}^{n} \frac{1-\delta_i}{1+e^{\epsilon_i}}-\max_{i}{\frac{1-\delta_{i}}{1+e^{\epsilon_{i}}}}}}$。该方法使我们能够避免不等式估计相关的局限性和潜在不准确性。为强化隐私保障,我们通过利用假设检验(而非依赖如切尔诺夫界或霍夫丁不等式等粗略估计)来改进下界。此外,广泛的比较评估清晰表明,我们的方法在实现强中心隐私保障的同时保持全局模型效用方面优于现有方法。我们还针对平均函数、频率估计和随机梯度下降精心设计了相应算法。