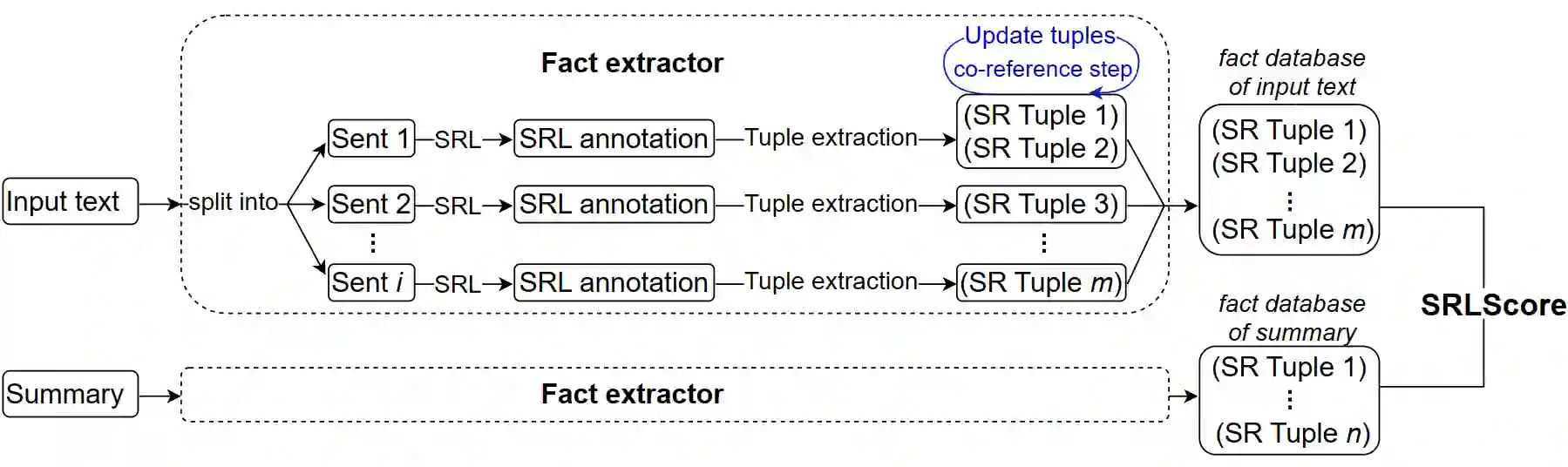
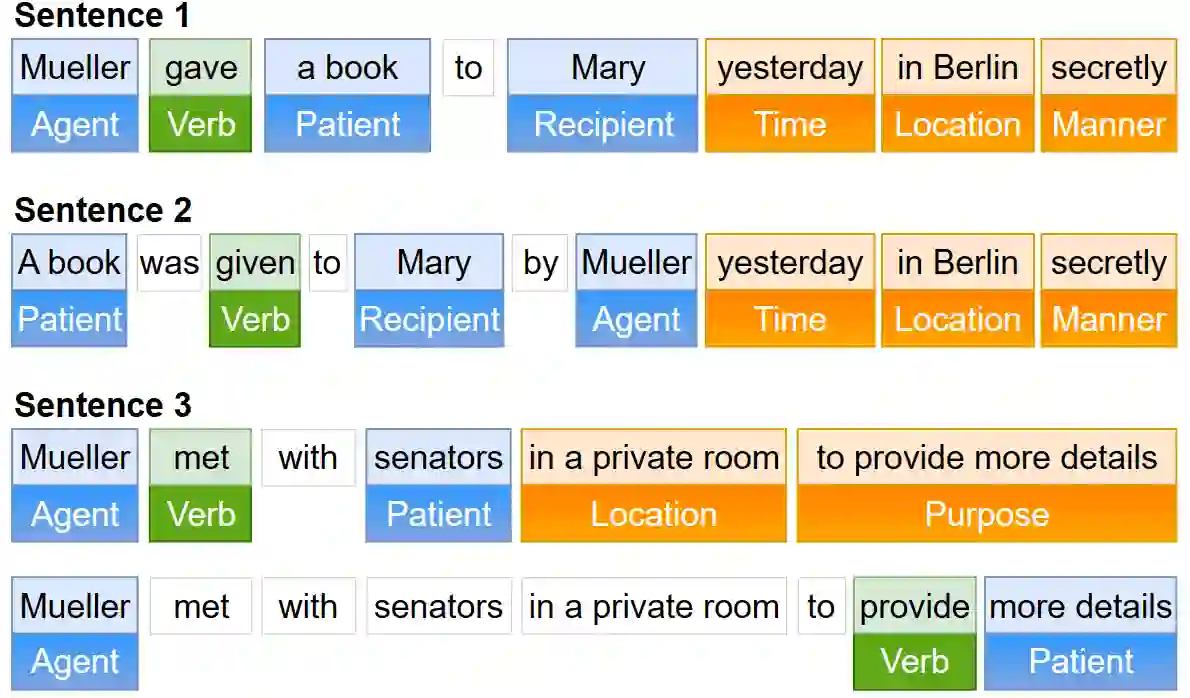
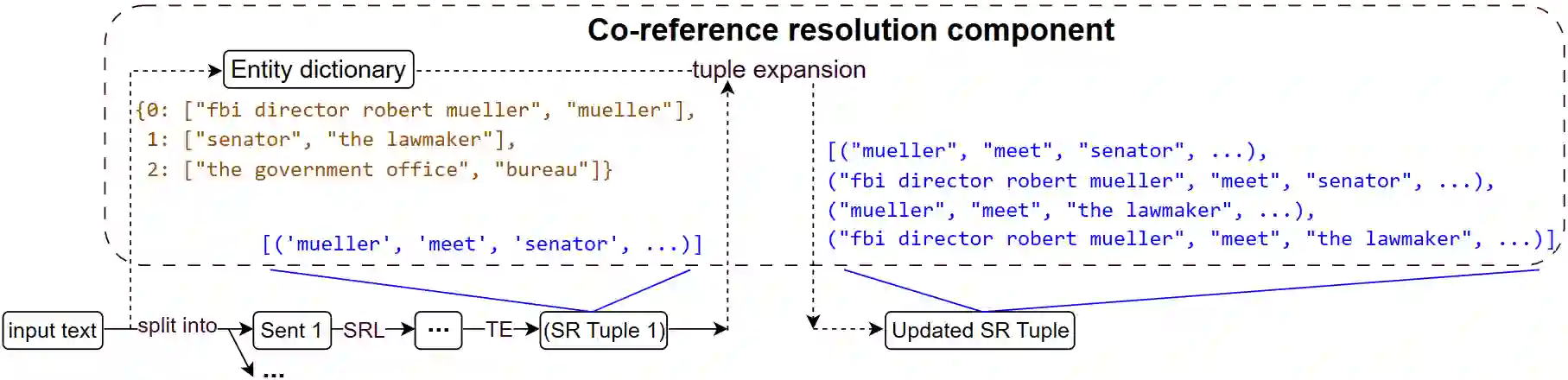
Automated evaluation of text generation systems has recently seen increasing attention, particularly checking whether generated text stays truthful to input sources. Existing methods frequently rely on an evaluation using task-specific language models, which in turn allows for little interpretability of generated scores. We introduce SRLScore, a reference-free evaluation metric designed with text summarization in mind. Our approach generates fact tuples constructed from Semantic Role Labels, applied to both input and summary texts. A final factuality score is computed by an adjustable scoring mechanism, which allows for easy adaption of the method across domains. Correlation with human judgments on English summarization datasets shows that SRLScore is competitive with state-of-the-art methods and exhibits stable generalization across datasets without requiring further training or hyperparameter tuning. We experiment with an optional co-reference resolution step, but find that the performance boost is mostly outweighed by the additional compute required. Our metric is available online at https://github.com/heyjing/SRLScore.
翻译:近年来,文本生成系统的自动化评估日益受到关注,特别是检查生成文本是否忠实于输入源。现有方法常依赖基于任务特定语言模型的评估,这使得生成分数的可解释性较低。我们提出SRLScore——一种专为文本摘要设计的无参考评估指标。该方法从语义角色标签构建事实元组,同时应用于输入文本和摘要文本。通过可调整的评分机制计算最终事实性分数,使得该方法能够轻松适应不同领域。在英文摘要数据集上与人工判断的相关性表明,SRLScore与最先进的方法具有竞争力,且无需额外训练或超参数调整即可在数据集间稳定泛化。我们尝试了可选的共指消解步骤,但发现其性能提升大多被所需的额外计算所抵消。我们的指标在线提供:https://github.com/heyjing/SRLScore。