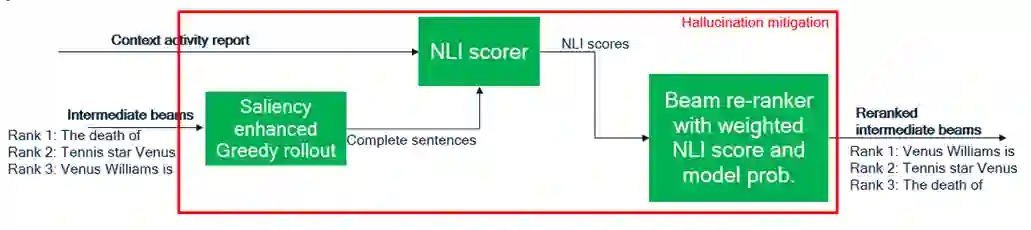
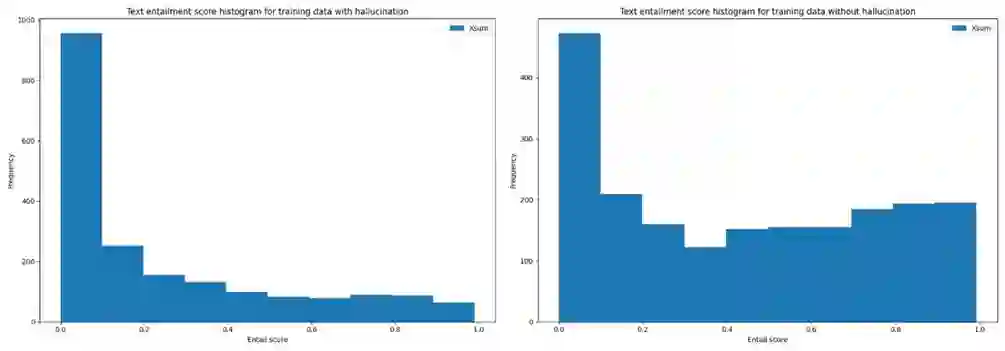
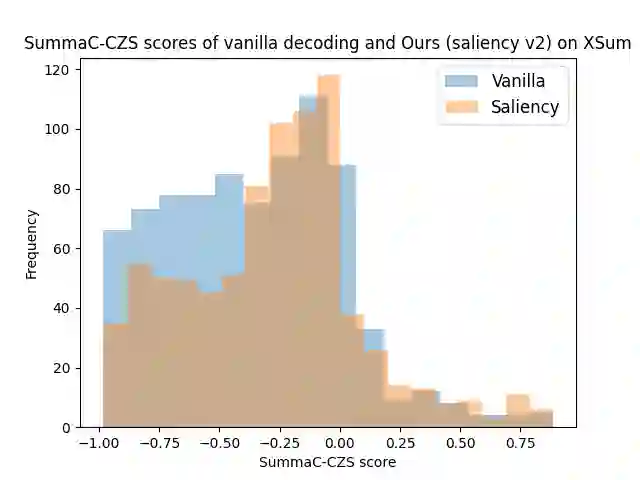
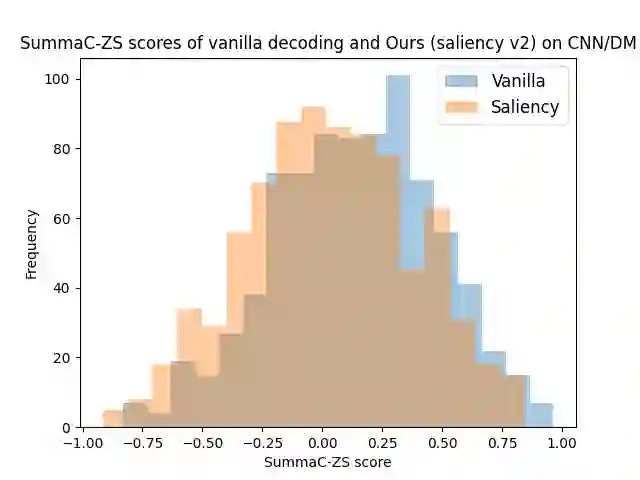
Advancement in large pretrained language models has significantly improved their performance for conditional language generation tasks including summarization albeit with hallucinations. To reduce hallucinations, conventional methods proposed improving beam search or using a fact checker as a postprocessing step. In this paper, we investigate the use of the Natural Language Inference (NLI) entailment metric to detect and prevent hallucinations in summary generation. We propose an NLI-assisted beam re-ranking mechanism by computing entailment probability scores between the input context and summarization model-generated beams during saliency-enhanced greedy decoding. Moreover, a diversity metric is introduced to compare its effectiveness against vanilla beam search. Our proposed algorithm significantly outperforms vanilla beam decoding on XSum and CNN/DM datasets.
翻译:大型预训练语言模型的进步显著提升了其在条件生成任务(包括摘要生成)中的性能,但幻觉问题依然存在。为减少幻觉,传统方法提出改进波束搜索或采用事实核查作为后处理步骤。本文探讨了利用自然语言推理(NLI)蕴含指标来检测和防止摘要生成中的幻觉。我们提出了一种基于NLI辅助的波束重排序机制,通过在显著性增强的贪心解码过程中计算输入上下文与摘要模型生成的波束之间的蕴含概率分数。此外,还引入了多样性指标以评估其与标准波束搜索相比的有效性。我们提出的算法在XSum和CNN/DM数据集上显著优于标准波束解码。