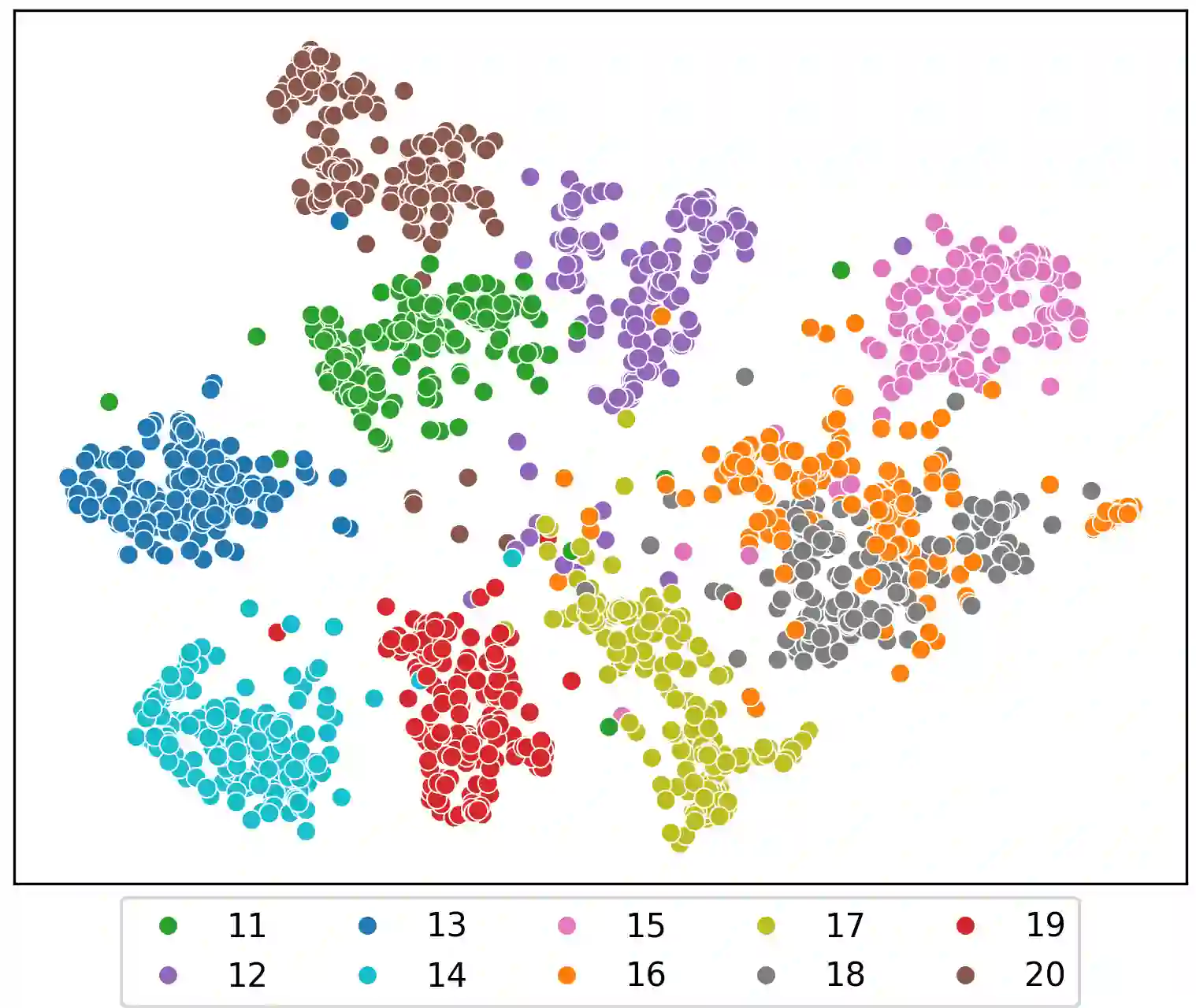
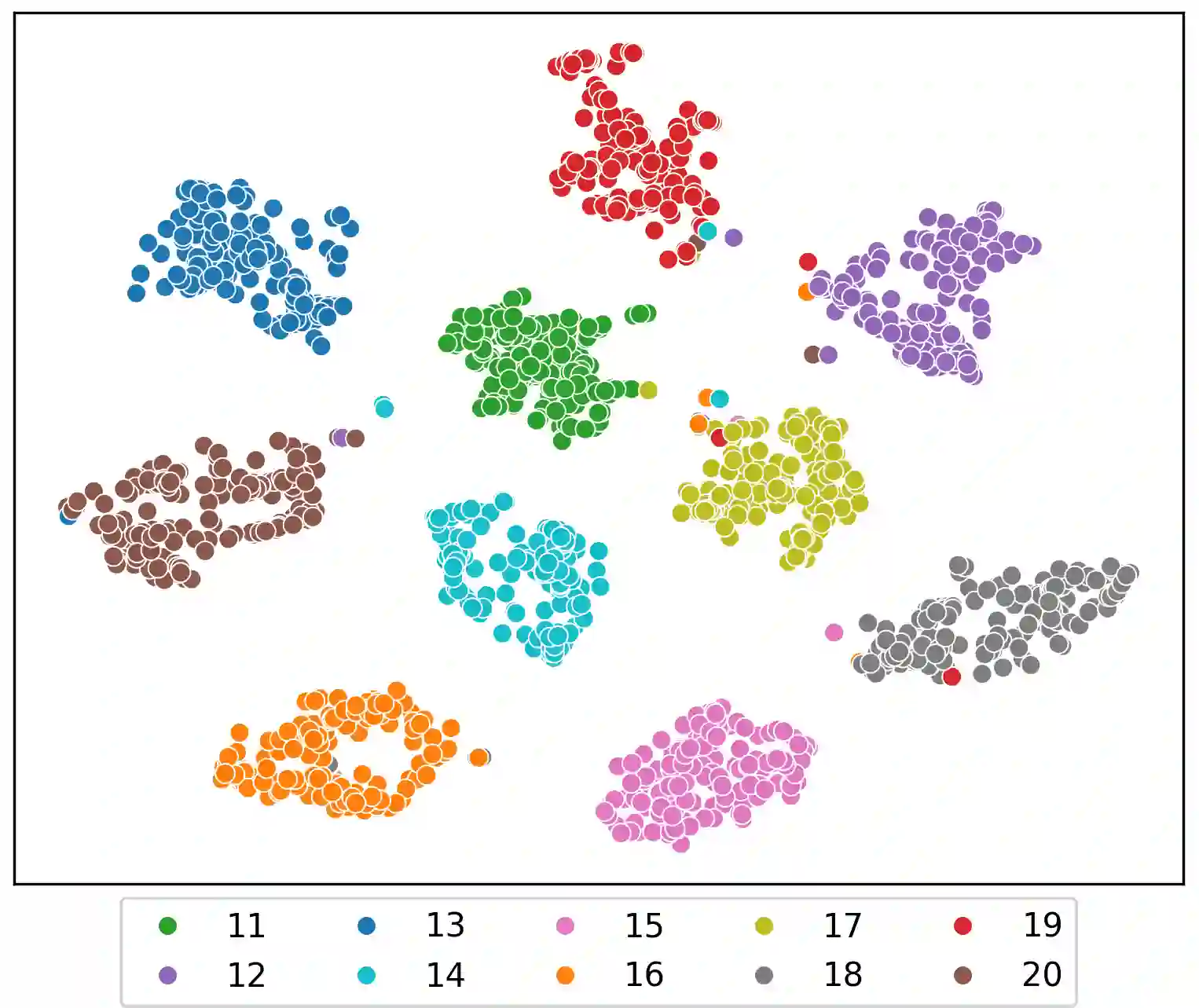
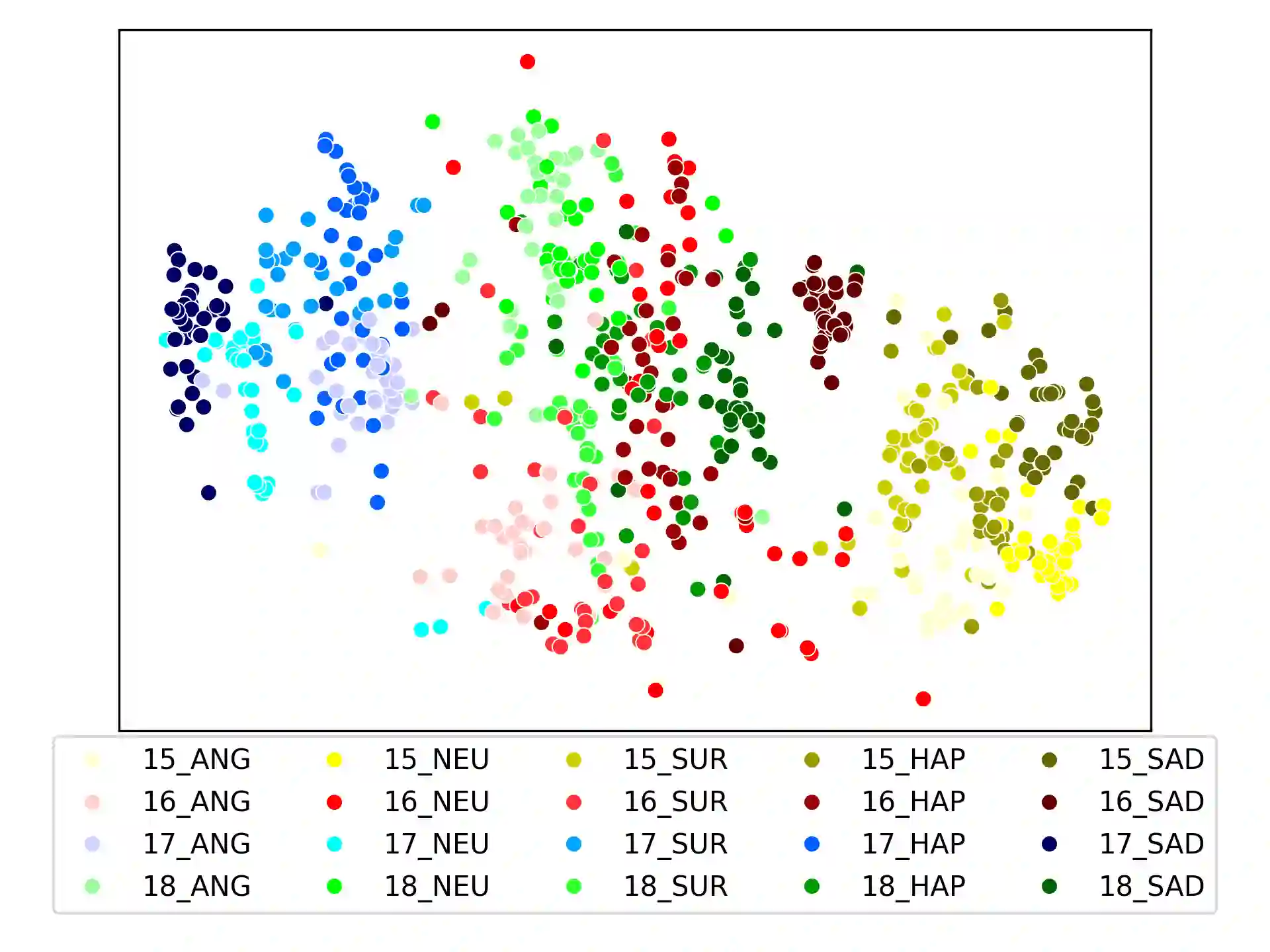
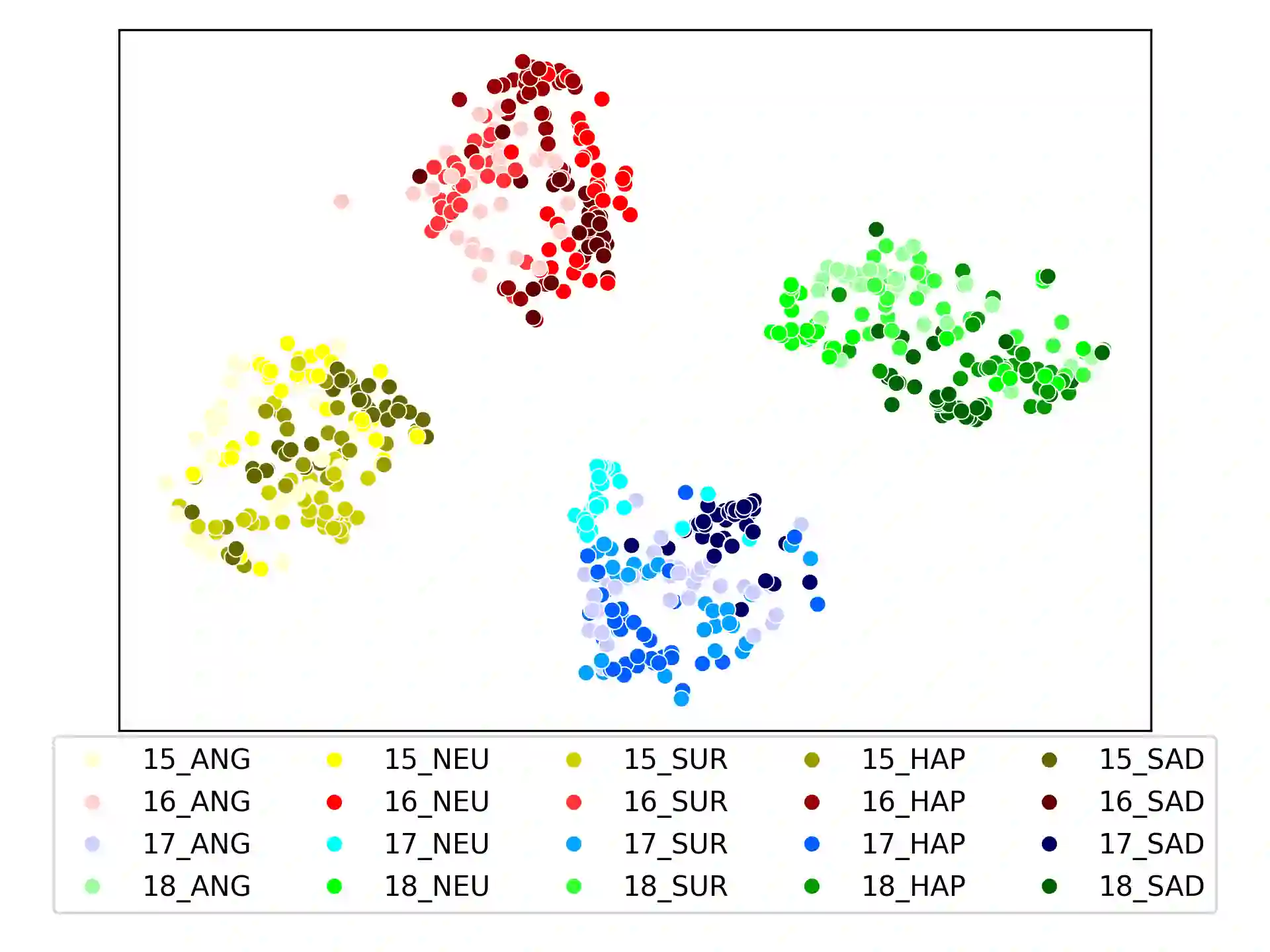
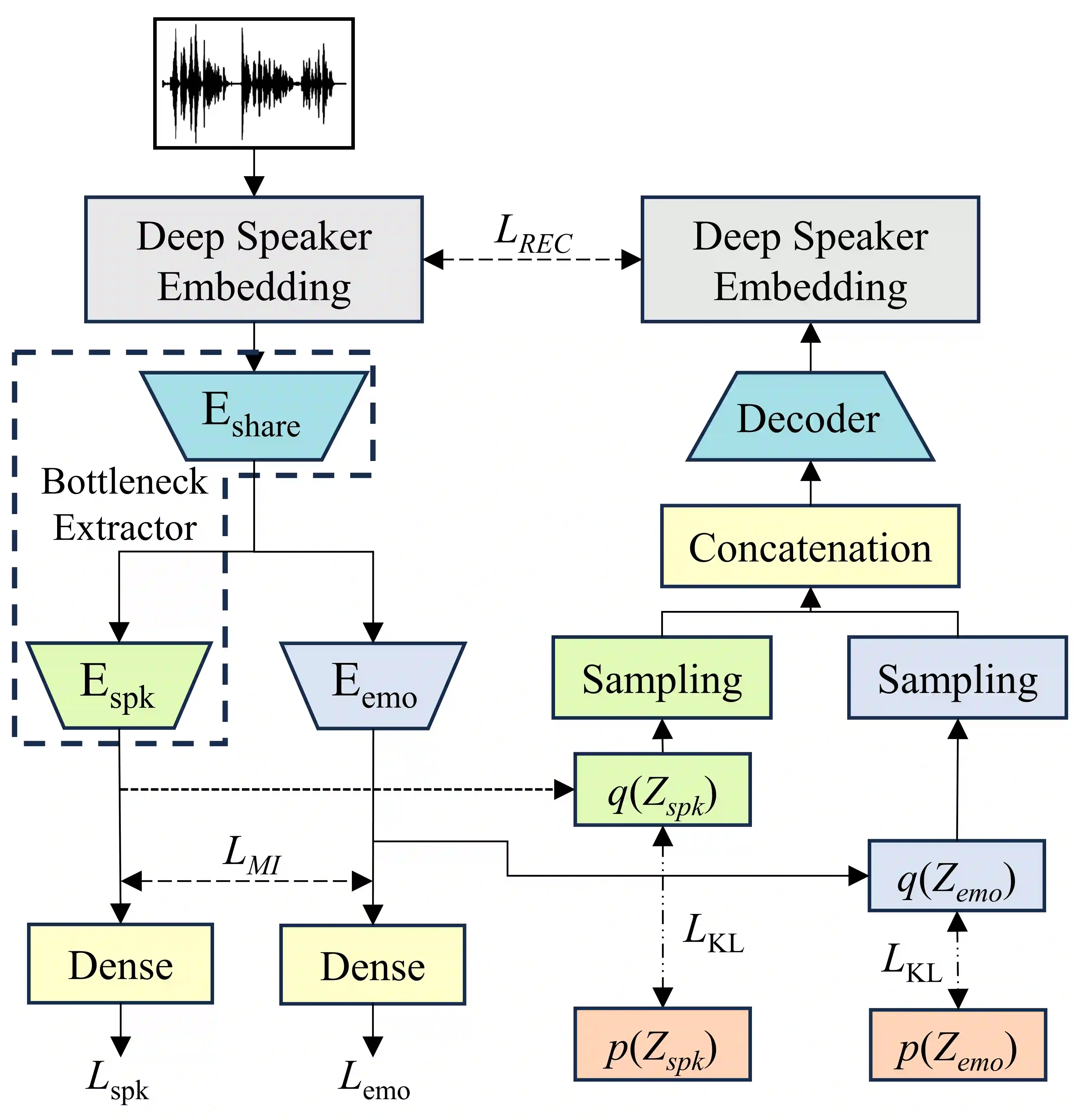
Speaker clustering is the task of identifying the unique speakers in a set of audio recordings (each belonging to exactly one speaker) without knowing who and how many speakers are present in the entire data, which is essential for speaker diarization processes. Recently, off-the-shelf deep speaker embedding models have been leveraged to capture speaker characteristics. However, speeches containing emotional expressions pose significant challenges, often affecting the accuracy of speaker embeddings and leading to a decline in speaker clustering performance. To tackle this problem, we propose DTG-VAE, a novel disentanglement method that enhances clustering within a Variational Autoencoder (VAE) framework. This study reveals a direct link between emotional states and the effectiveness of deep speaker embeddings. As demonstrated in our experiments, DTG-VAE extracts more robust speaker embeddings and significantly enhances speaker clustering performance.
翻译:说话人聚类任务旨在从一组音频录音(每条录音仅属于单一说话人)中识别出唯一的说话人,而无需预先获知整个数据集中存在哪些说话人及其具体数量,该任务是说话人日志生成流程中的关键环节。近年来,现成的深度说话人嵌入模型已被用于捕捉说话人特征。然而,包含情感表达的语音会带来显著挑战,常常影响说话人嵌入的准确性,并导致说话人聚类性能下降。为解决此问题,我们提出了一种新颖的解耦方法DTG-VAE,该方法在变分自编码器框架内增强了聚类能力。本研究揭示了情感状态与深度说话人嵌入有效性之间的直接关联。如实验所示,DTG-VAE能够提取更鲁棒的说话人嵌入,并显著提升说话人聚类性能。