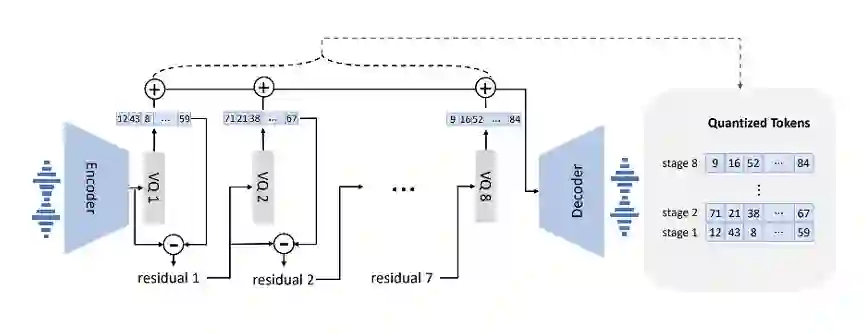
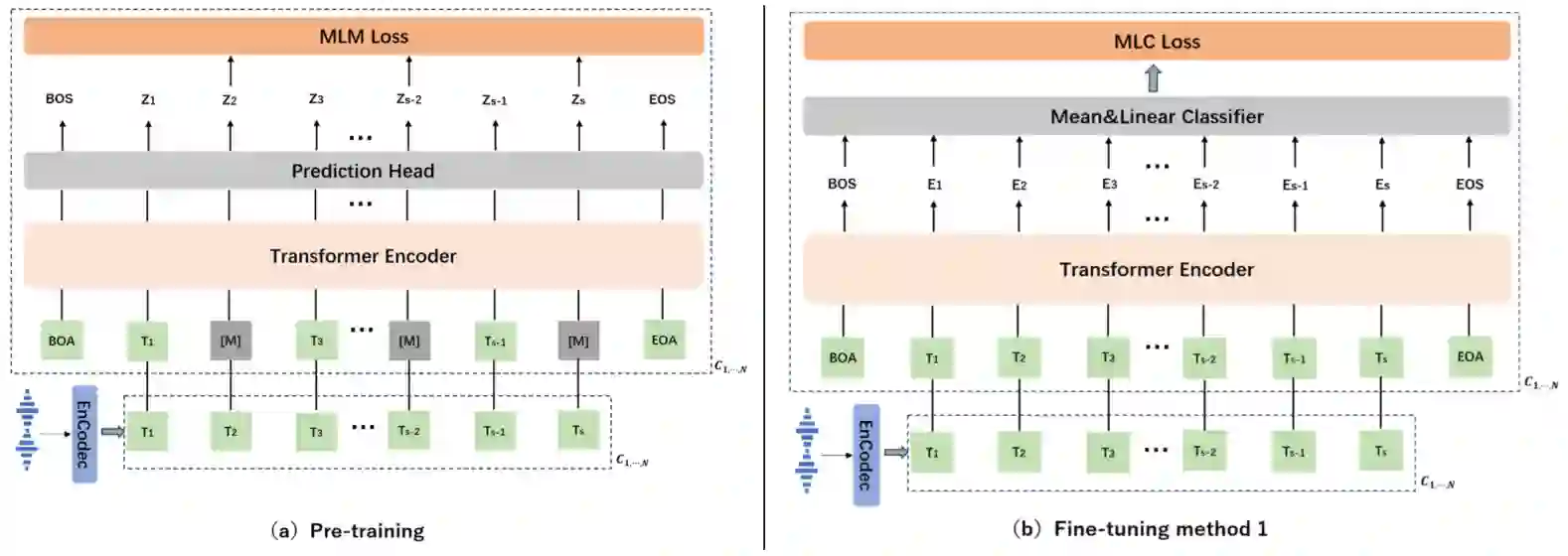
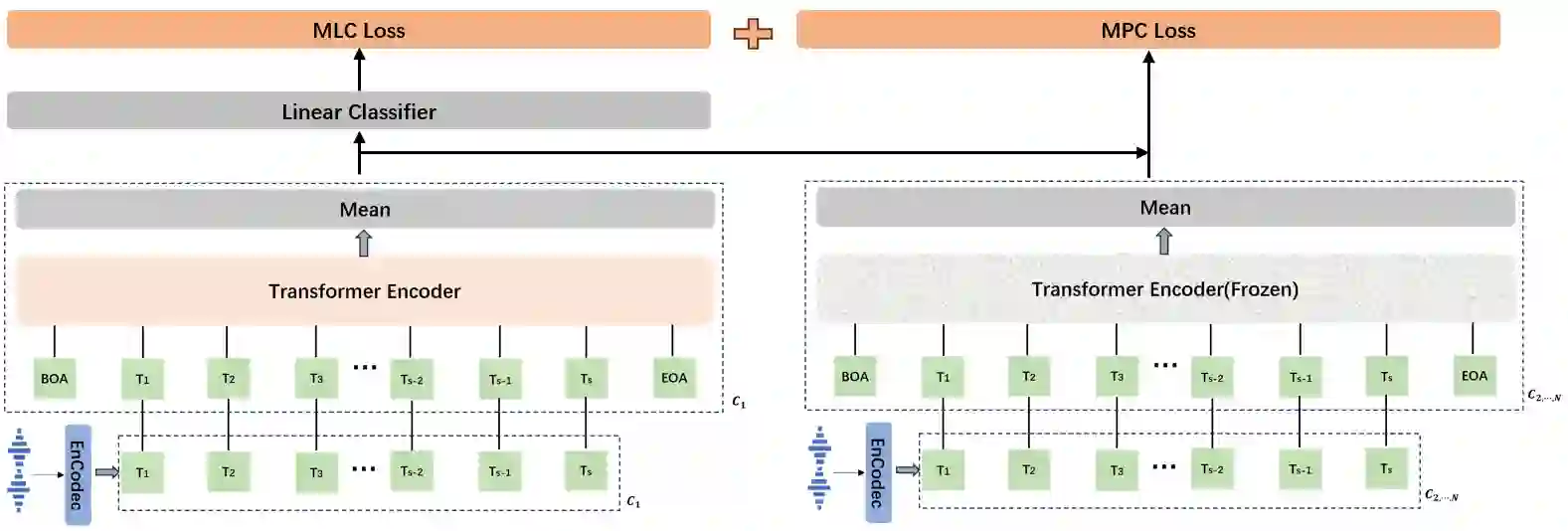
We propose a method named AudioFormer,which learns audio feature representations through the acquisition of discrete acoustic codes and subsequently fine-tunes them for audio classification tasks. Initially,we introduce a novel perspective by considering the audio classification task as a form of natural language understanding (NLU). Leveraging an existing neural audio codec model,we generate discrete acoustic codes and utilize them to train a masked language model (MLM),thereby obtaining audio feature representations. Furthermore,we pioneer the integration of a Multi-Positive sample Contrastive (MPC) learning approach. This method enables the learning of joint representations among multiple discrete acoustic codes within the same audio input. In our experiments,we treat discrete acoustic codes as textual data and train a masked language model using a cloze-like methodology,ultimately deriving high-quality audio representations. Notably,the MPC learning technique effectively captures collaborative representations among distinct positive samples. Our research outcomes demonstrate that AudioFormer attains significantly improved performance compared to prevailing monomodal audio classification models across multiple datasets,and even outperforms audio-visual multimodal classification models on select datasets. Specifically,our approach achieves remarkable results on datasets including AudioSet (2M,20K),and FSD50K,with performance scores of 53.9,45.1,and 65.6,respectively. We have openly shared both the code and models: https://github.com/LZH-0225/AudioFormer.git.
翻译:我们提出一种名为AudioFormer的方法,该方法通过获取离散声学编码来学习音频特征表示,并在此基础上进行微调以完成音频分类任务。首先,我们引入了一种新颖的观点,将音频分类任务视为一种自然语言理解(NLU)形式。利用现有的神经音频编解码器模型,我们生成离散声学编码,并利用这些编码训练掩码语言模型(MLM),从而获得音频特征表示。此外,我们开创性地整合了多正样本对比学习(MPC)方法。该方法能够学习同一音频输入中多个离散声学编码之间的联合表示。在实验中,我们将离散声学编码视为文本数据,采用类完形填空的方法训练掩码语言模型,最终得到高质量的音频表示。值得注意的是,MPC学习技术能够有效捕捉不同正样本之间的协同表示。我们的研究结果表明,AudioFormer在多个数据集上的性能显著优于当前的主流单模态音频分类模型,甚至在某些数据集上超越了音频-视觉多模态分类模型。具体而言,我们的方法在AudioSet(2M、20K)和FSD50K数据集上取得了显著结果,性能分数分别为53.9、45.1和65.6。我们已公开分享代码和模型:https://github.com/LZH-0225/AudioFormer.git。