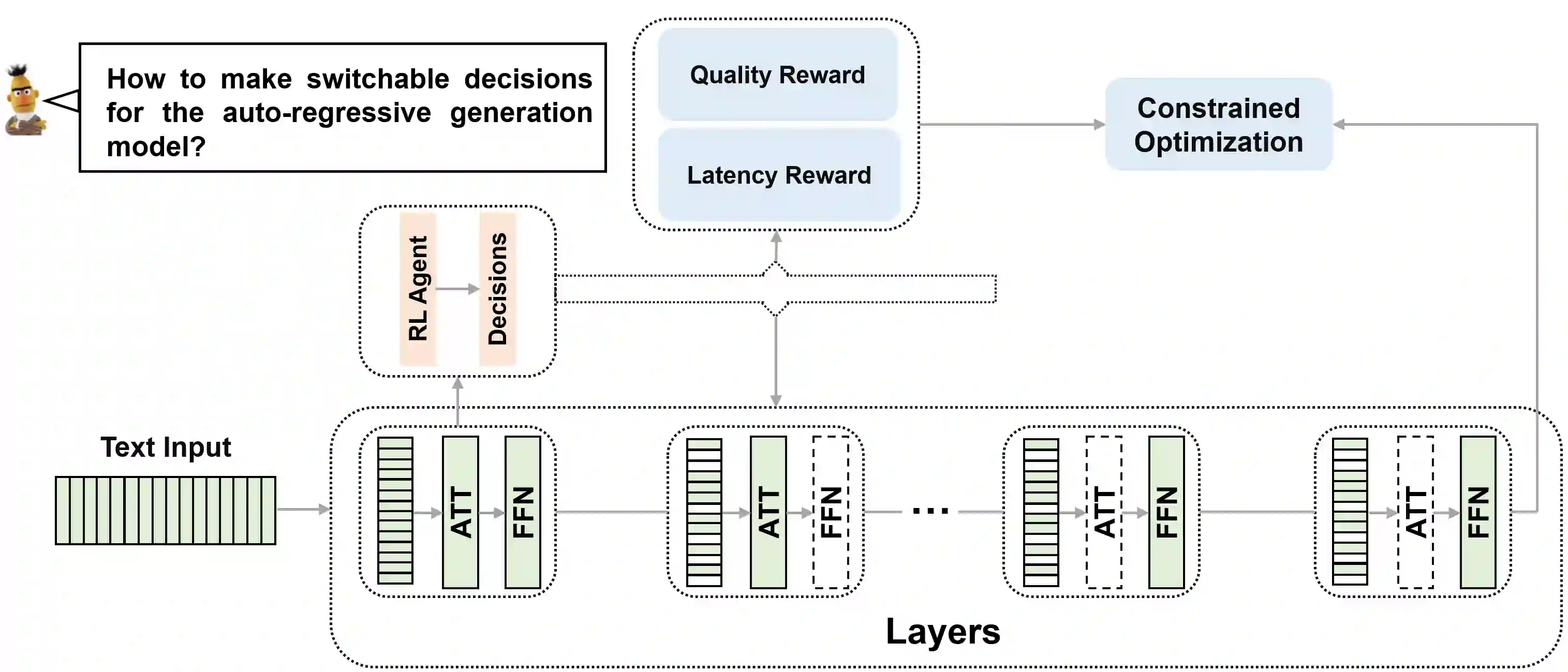
Auto-regressive generation models achieve competitive performance across many different NLP tasks such as summarization, question answering, and classifications. However, they are also known for being slow in inference, which makes them challenging to deploy in real-time applications. We propose a switchable decision to accelerate inference by dynamically assigning computation resources for each data instance. Automatically making decisions on where to skip and how to balance quality and computation cost with constrained optimization, our dynamic neural generation networks enforce the efficient inference path and determine the optimized trade-off. Experiments across question answering, summarization, and classification benchmarks show that our method benefits from less computation cost during inference while keeping the same accuracy. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
翻译:自回归生成模型在摘要生成、问答和分类等众多自然语言处理任务中表现出色,但其推理速度缓慢,难以部署于实时应用。我们提出一种可切换决策方法,通过为每个数据实例动态分配计算资源来加速推理。该方法利用约束优化自动决定何处可跳过计算以及如何平衡生成质量与计算成本,从而构建高效的动态神经生成网络,实现推理路径优化与折中。在问答、摘要生成和分类基准上的实验表明,我们的方法在保持相同准确率的同时降低了推理计算成本。大量实验与消融研究证明,该方法具有通用性、有效性,并适用于多种自然语言处理任务。