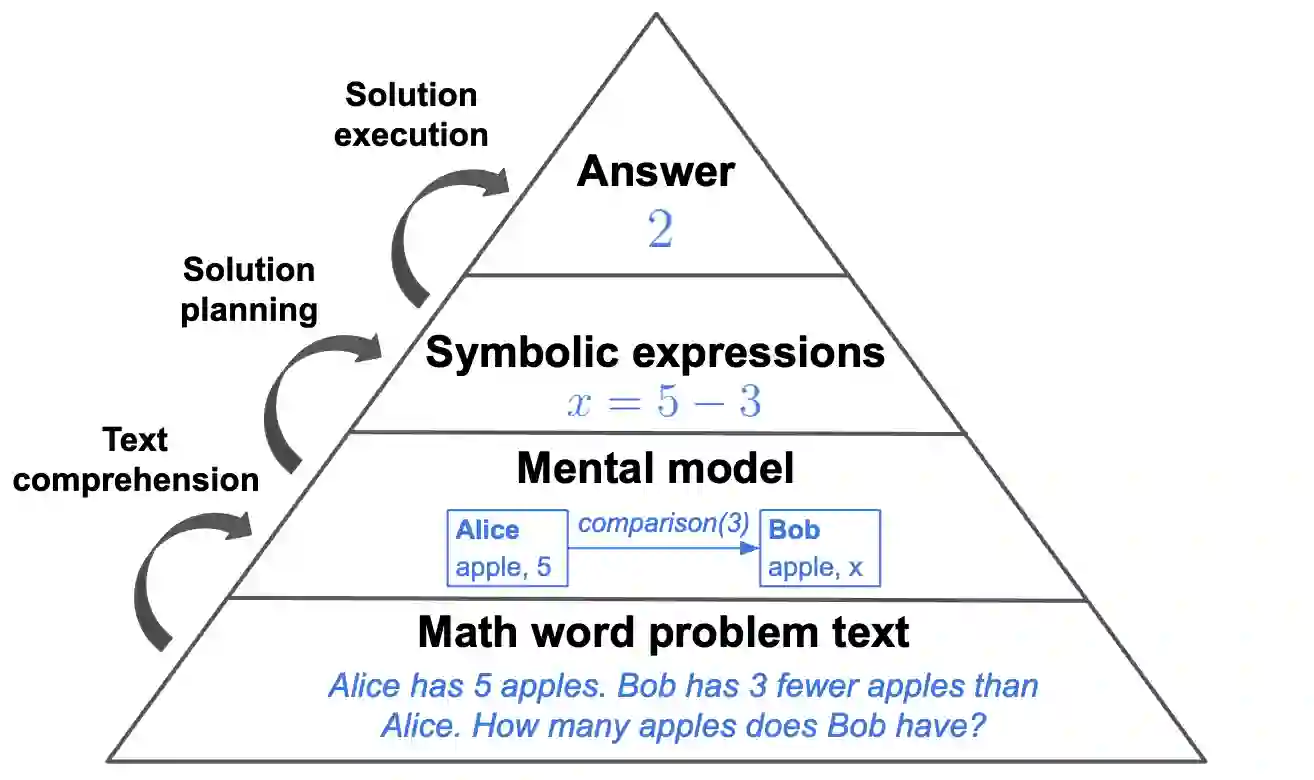
There is increasing interest in employing large language models (LLMs) as cognitive models. For such purposes, it is central to understand which cognitive properties are well-modeled by LLMs, and which are not. In this work, we study the biases of LLMs in relation to those known in children when solving arithmetic word problems. Surveying the learning science literature, we posit that the problem-solving process can be split into three distinct steps: text comprehension, solution planning and solution execution. We construct tests for each one in order to understand which parts of this process can be faithfully modeled by current state-of-the-art LLMs. We generate a novel set of word problems for each of these tests, using a neuro-symbolic method that enables fine-grained control over the problem features. We find evidence that LLMs, with and without instruction-tuning, exhibit human-like biases in both the text-comprehension and the solution-planning steps of the solving process, but not during the final step which relies on the problem's arithmetic expressions (solution execution).
翻译:近年来,将大型语言模型(LLMs)用作认知模型的研究兴趣日益增长。为此,理解哪些认知属性能够被LLMs有效建模、哪些不能,至关重要。本研究探讨了LLMs在解决算术文字题时所表现出的偏差,并与儿童已知的偏差进行比较。通过梳理学习科学文献,我们认为问题解决过程可分为三个不同步骤:文本理解、方案规划与方案执行。我们针对每一步骤构建了测试,以揭示当前最先进的LLMs能够忠实地模拟该过程的哪些部分。对于每项测试,我们利用一种神经符号方法生成了一组全新的文字题,该方法能够对问题特征进行细粒度控制。研究发现,无论是否经过指令微调,LLMs在问题解决的文本理解和方案规划步骤中均表现出类似人类的偏差,但在依赖于问题算术表达式执行的最终步骤中并未发现此类偏差。