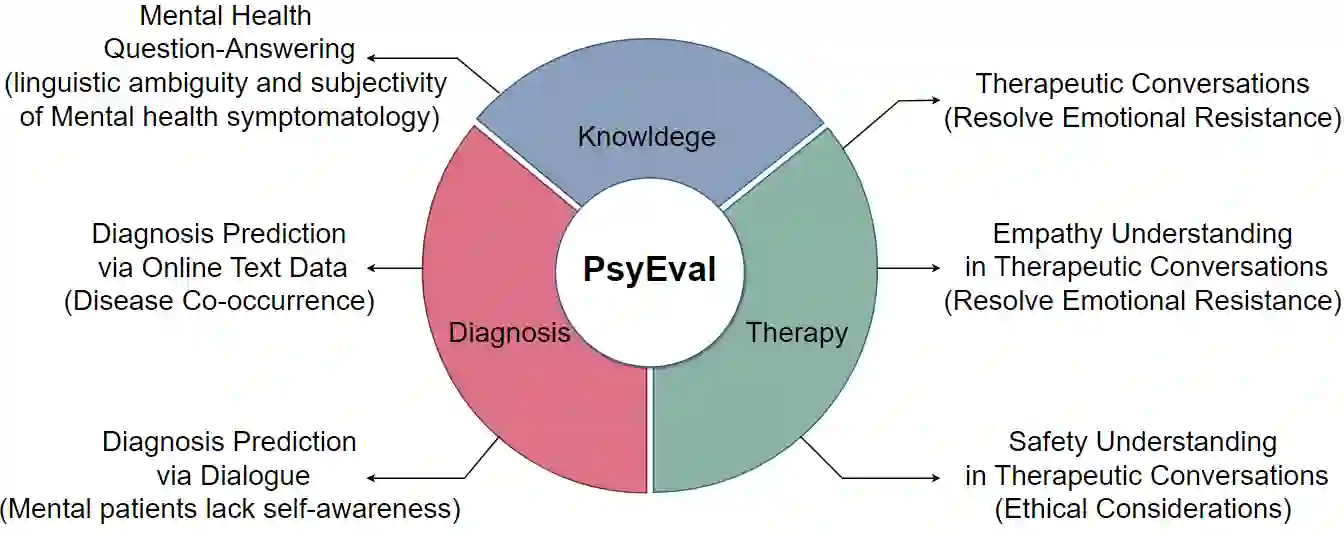
Recently, there has been a growing interest in utilizing large language models (LLMs) in mental health research, with studies showcasing their remarkable capabilities, such as disease detection. However, there is currently a lack of a comprehensive benchmark for evaluating the capability of LLMs in this domain. Therefore, we address this gap by introducing the first comprehensive benchmark tailored to the unique characteristics of the mental health domain. This benchmark encompasses a total of six sub-tasks, covering three dimensions, to systematically assess the capabilities of LLMs in the realm of mental health. We have designed corresponding concise prompts for each sub-task. And we comprehensively evaluate a total of eight advanced LLMs using our benchmark. Experiment results not only demonstrate significant room for improvement in current LLMs concerning mental health but also unveil potential directions for future model optimization.
翻译:近年来,利用大型语言模型(LLMs)开展心理健康研究日益引起学界关注,相关研究已展示出其在疾病检测等任务中的卓越能力。然而,目前尚缺乏能够全面评估LLMs在该领域能力的标准化基准。为此,本研究针对心理健康领域的独特特征,首次构建了系统性评测基准。该基准涵盖三个维度的六项子任务,可系统评估LLMs在心理健康领域的能力。我们为每项子任务设计了简洁的提示模板,并基于该基准对八种先进LLMs进行了全面评测。实验结果表明,当前LLMs在心理健康领域仍存在显著改进空间,同时揭示了未来模型优化的潜在方向。