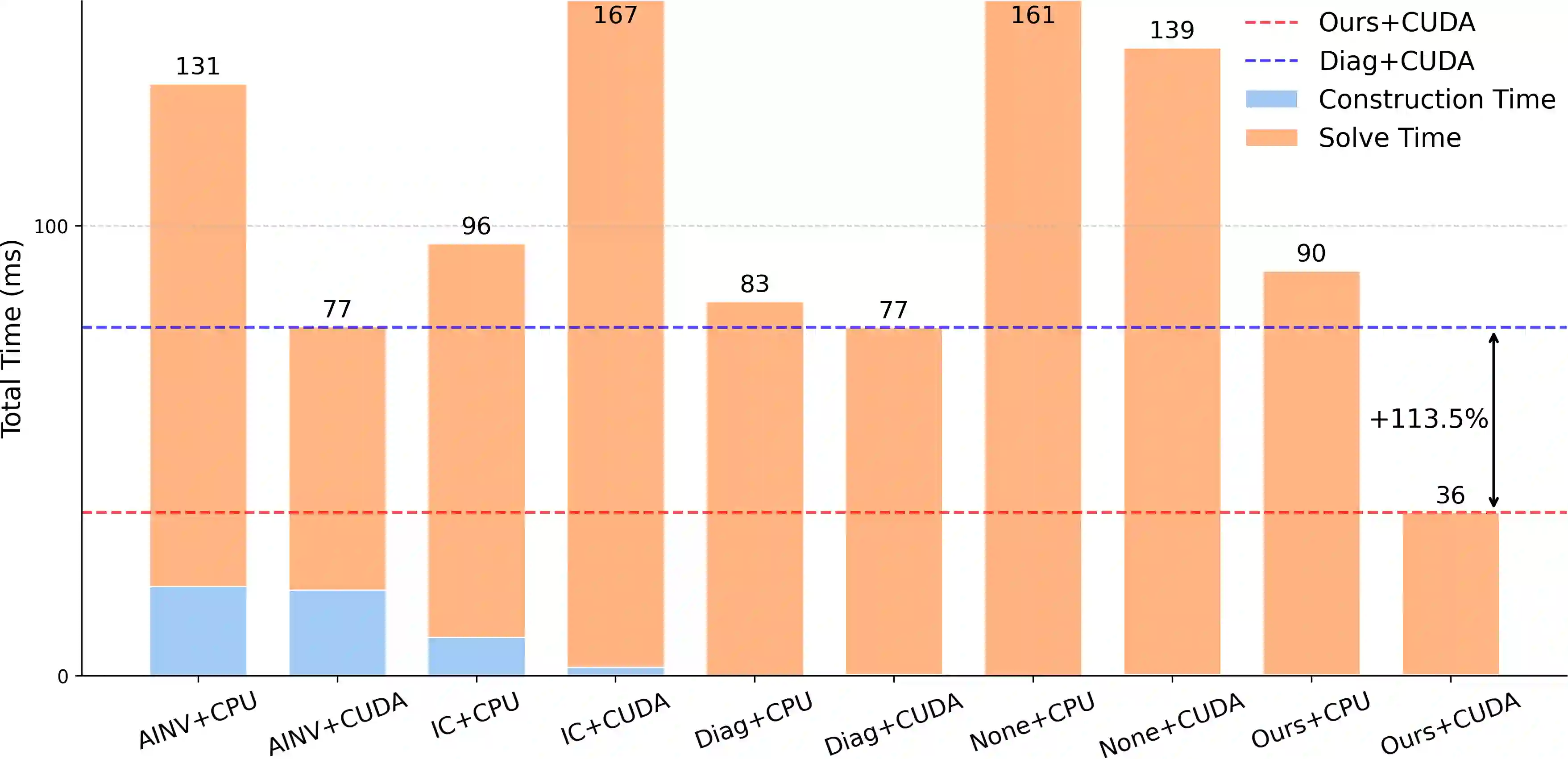
The conjugate gradient solver (CG) is a prevalent method for solving symmetric and positive definite linear systems Ax=b, where effective preconditioners are crucial for fast convergence. Traditional preconditioners rely on prescribed algorithms to offer rigorous theoretical guarantees, while limiting their ability to exploit optimization from data. Existing learning-based methods often utilize Graph Neural Networks (GNNs) to improve the performance and speed up the construction. However, their reliance on incomplete factorization leads to significant challenges: the associated triangular solve hinders GPU parallelization in practice, and introduces long-range dependencies which are difficult for GNNs to model. To address these issues, we propose a learning-based method to generate GPU-friendly preconditioners, particularly using GNNs to construct Sparse Approximate Inverse (SPAI) preconditioners, which avoids triangular solves and requires only two matrix-vector products at each CG step. The locality of matrix-vector product is compatible with the local propagation mechanism of GNNs. The flexibility of GNNs also allows our approach to be applied in a wide range of scenarios. Furthermore, we introduce a statistics-based scale-invariant loss function. Its design matches CG's property that the convergence rate depends on the condition number, rather than the absolute scale of A, leading to improved performance of the learned preconditioner. Evaluations on three PDE-derived datasets and one synthetic dataset demonstrate that our method outperforms standard preconditioners (Diagonal, IC, and traditional SPAI) and previous learning-based preconditioners on GPUs. We reduce solution time on GPUs by 40%-53% (68%-113% faster), along with better condition numbers and superior generalization performance. Source code available at https://github.com/Adversarr/LearningSparsePreconditioner4GPU
翻译:共轭梯度求解器(CG)是求解对称正定线性系统Ax=b的常用方法,其中有效的预条件子对于快速收敛至关重要。传统预条件子依赖于预设算法以提供严格的理论保证,但限制了其从数据中利用优化的能力。现有的基于学习的方法常利用图神经网络(GNNs)来提升性能并加速构造过程。然而,这些方法对不完全分解的依赖带来了显著挑战:相关的三角求解在实际中阻碍了GPU并行化,并引入了GNNs难以建模的长程依赖关系。为解决这些问题,我们提出一种基于学习的方法来生成GPU友好的预条件子,特别是利用GNNs构造稀疏近似逆(SPAI)预条件子,该方法避免了三角求解,且在每个CG步仅需两次矩阵-向量乘积。矩阵-向量乘积的局部性与GNNs的局部传播机制相兼容。GNNs的灵活性也使我们的方法适用于广泛场景。此外,我们引入了一种基于统计的尺度不变损失函数。其设计匹配了CG的收敛速率依赖于条件数而非A的绝对尺度的特性,从而提升了所学预条件子的性能。在三个偏微分方程衍生数据集和一个合成数据集上的评估表明,我们的方法在GPU上优于标准预条件子(对角、不完全Cholesky和传统SPAI)及先前基于学习的预条件子。我们将GPU上的求解时间减少了40%-53%(加速68%-113%),同时获得了更好的条件数和优异的泛化性能。源代码发布于 https://github.com/Adversarr/LearningSparsePreconditioner4GPU。