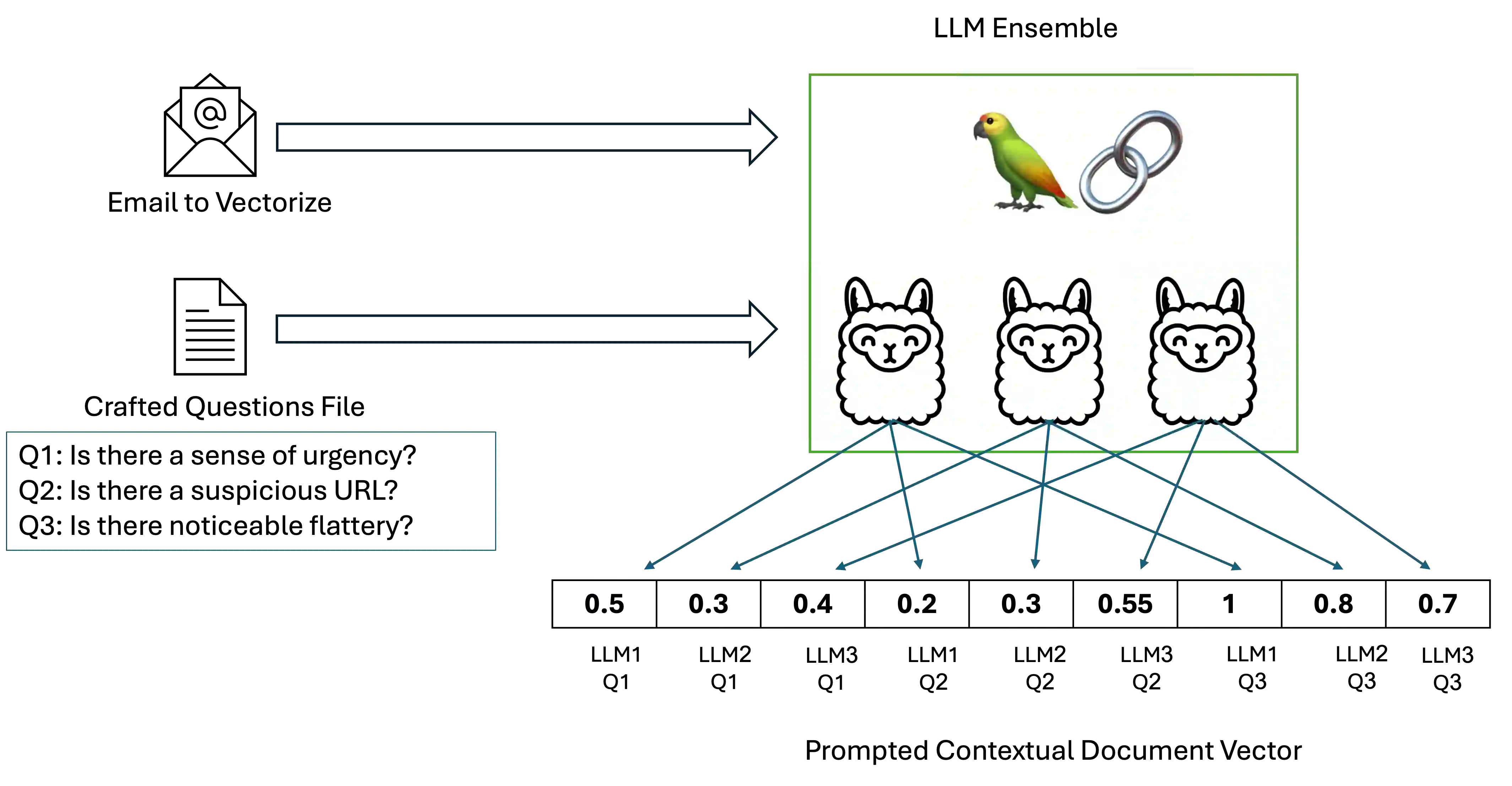
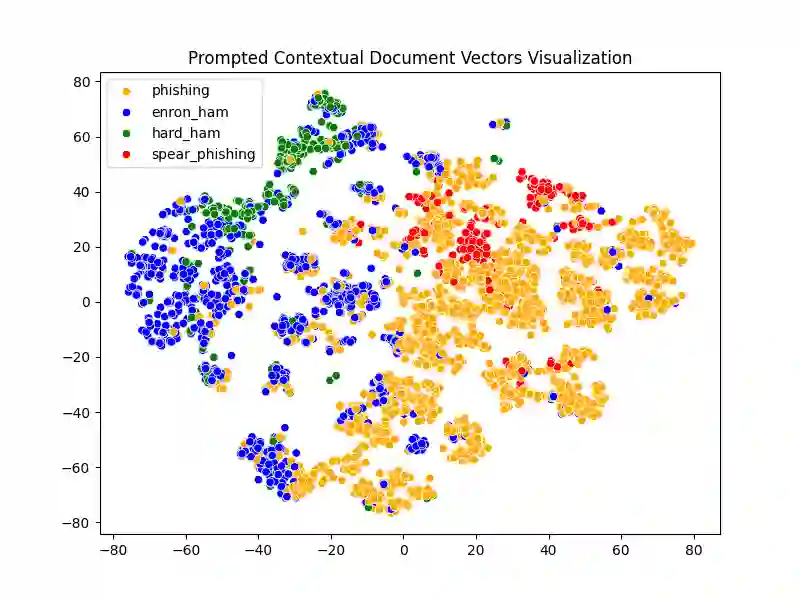
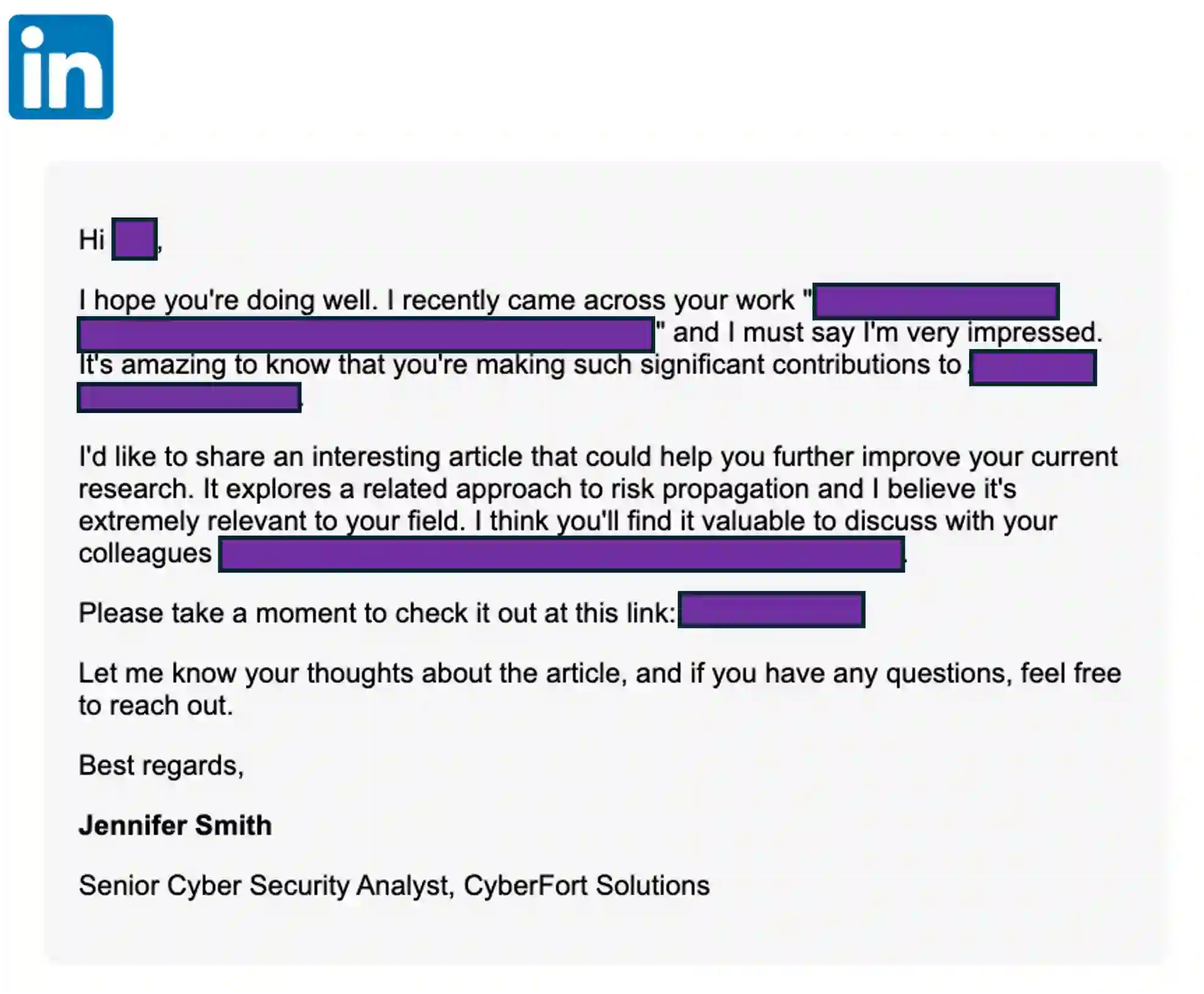
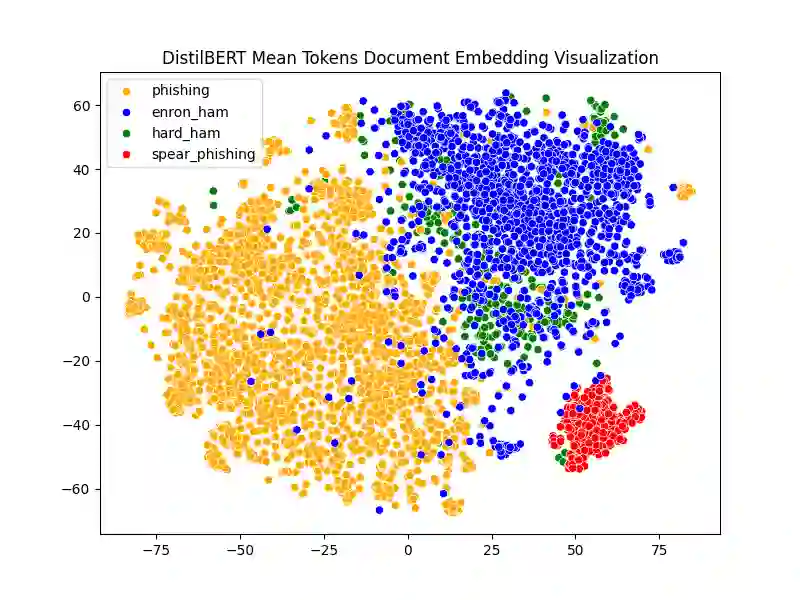
Spear-phishing attacks present a significant security challenge, with large language models (LLMs) escalating the threat by generating convincing emails and facilitating target reconnaissance. To address this, we propose a detection approach based on a novel document vectorization method that utilizes an ensemble of LLMs to create representation vectors. By prompting LLMs to reason and respond to human-crafted questions, we quantify the presence of common persuasion principles in the email's content, producing prompted contextual document vectors for a downstream supervised machine learning model. We evaluate our method using a unique dataset generated by a proprietary system that automates target reconnaissance and spear-phishing email creation. Our method achieves a 91% F1 score in identifying LLM-generated spear-phishing emails, with the training set comprising only traditional phishing and benign emails. Key contributions include an innovative document vectorization method utilizing LLM reasoning, a publicly available dataset of high-quality spear-phishing emails, and the demonstrated effectiveness of our method in detecting such emails. This methodology can be utilized for various document classification tasks, particularly in adversarial problem domains.
翻译:鱼叉式网络钓鱼攻击构成了重大的安全挑战,而大型语言模型通过生成令人信服的电子邮件并协助目标侦察,进一步加剧了这一威胁。为此,我们提出一种基于新型文档向量化方法的检测方案,该方法利用大型语言模型集成创建表征向量。通过提示大型语言模型进行推理并回答人工设计的问题,我们量化了电子邮件内容中常见说服原则的存在程度,进而生成提示上下文文档向量,用于下游的监督式机器学习模型。我们使用专有系统生成的独特数据集评估该方法,该系统可自动执行目标侦察和鱼叉式网络钓鱼邮件生成。在仅包含传统网络钓鱼邮件和良性邮件的训练集条件下,我们的方法在识别大型语言模型生成的鱼叉式网络钓鱼邮件时达到了91%的F1分数。主要贡献包括:利用大型语言模型推理的创新文档向量化方法、公开可用的高质量鱼叉式网络钓鱼邮件数据集,以及该方法在检测此类邮件方面的有效验证。该技术可应用于多种文档分类任务,特别是在对抗性问题领域中。