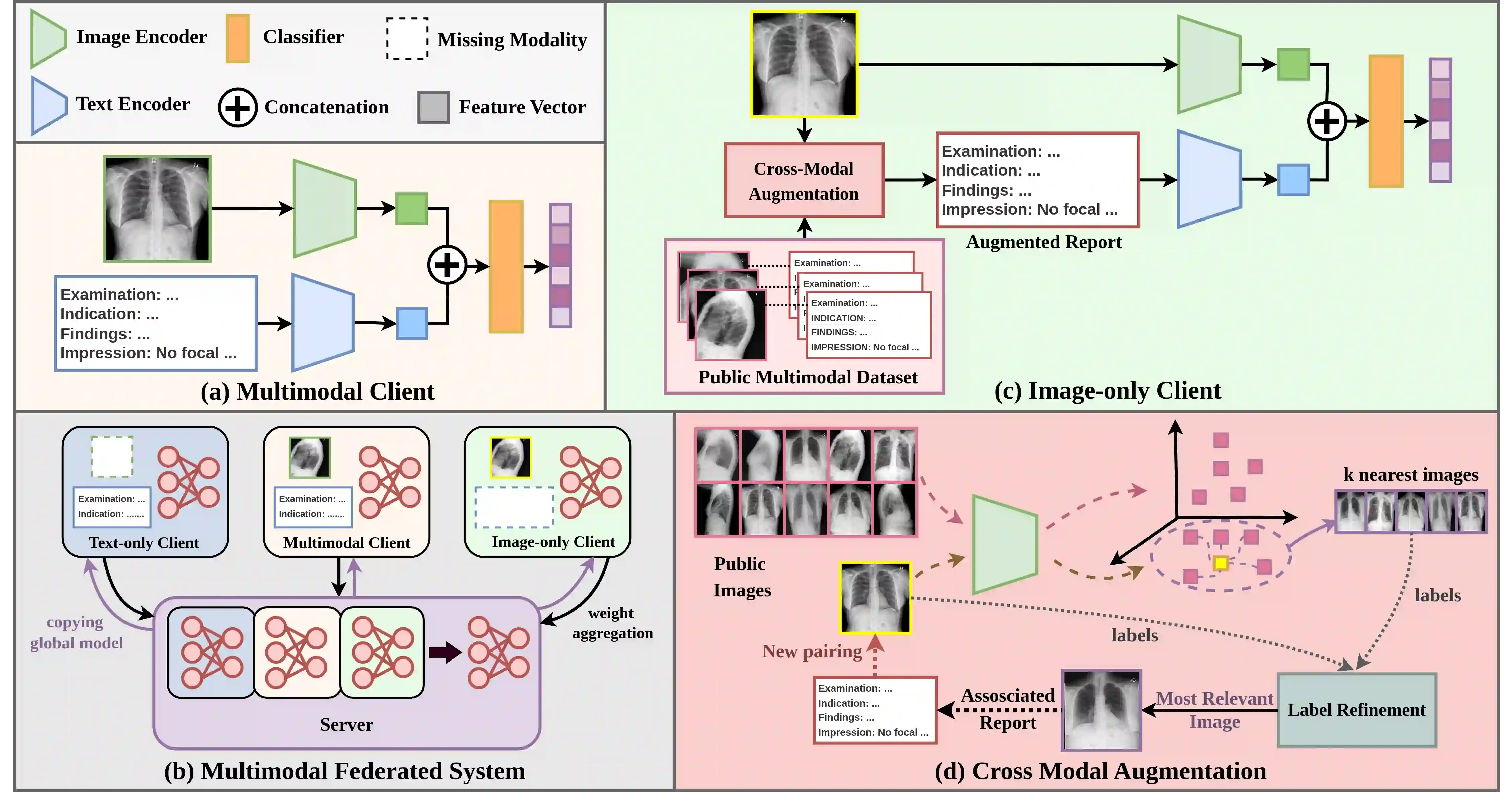
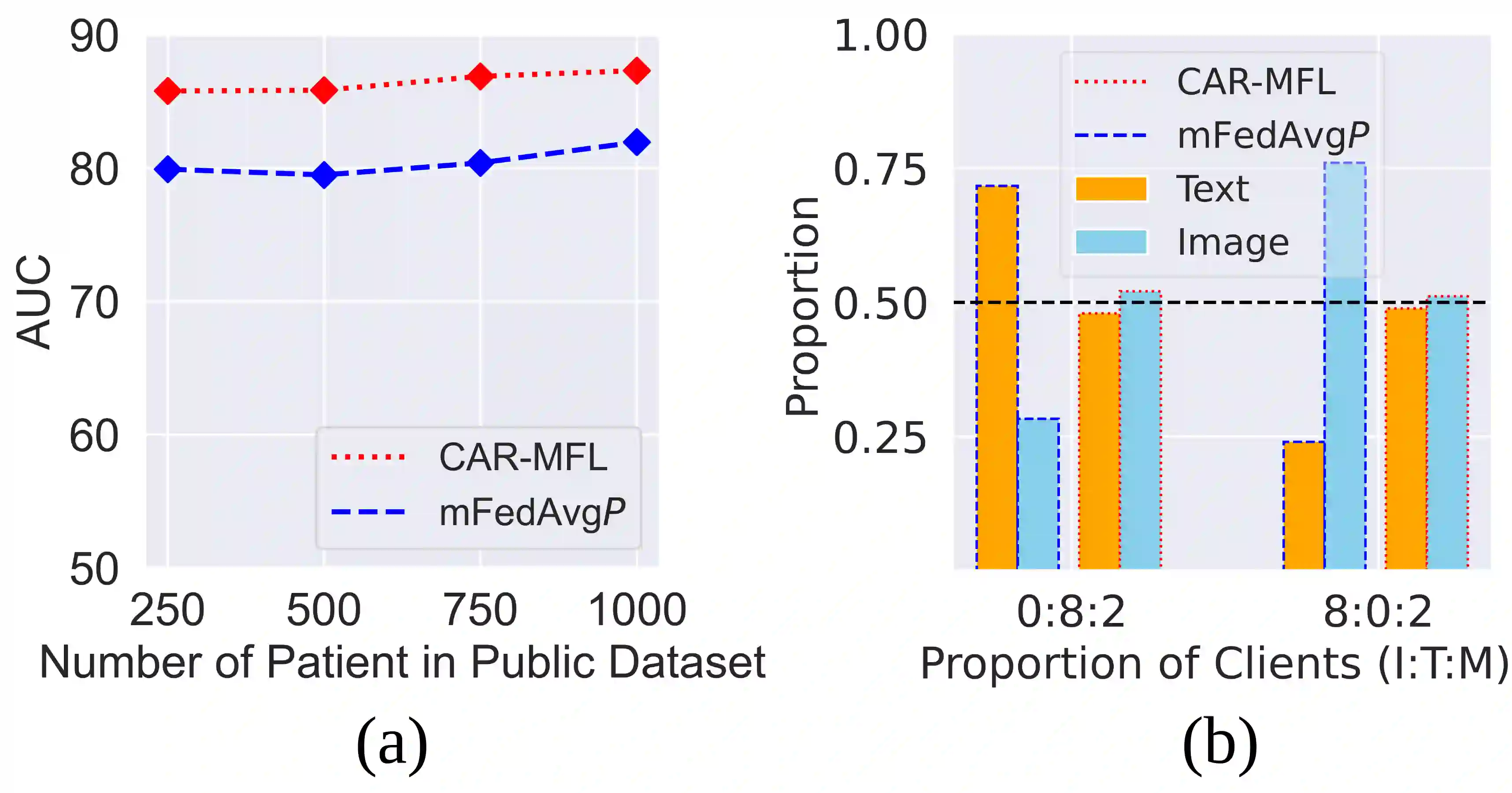
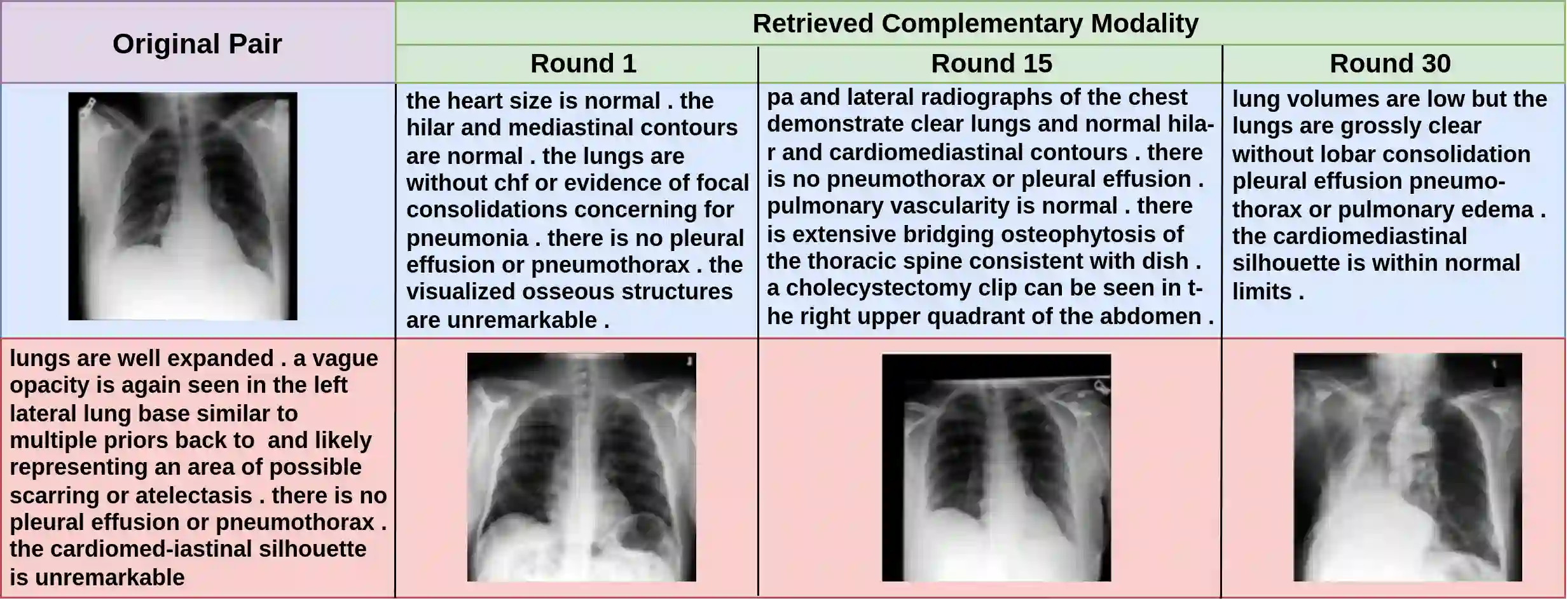
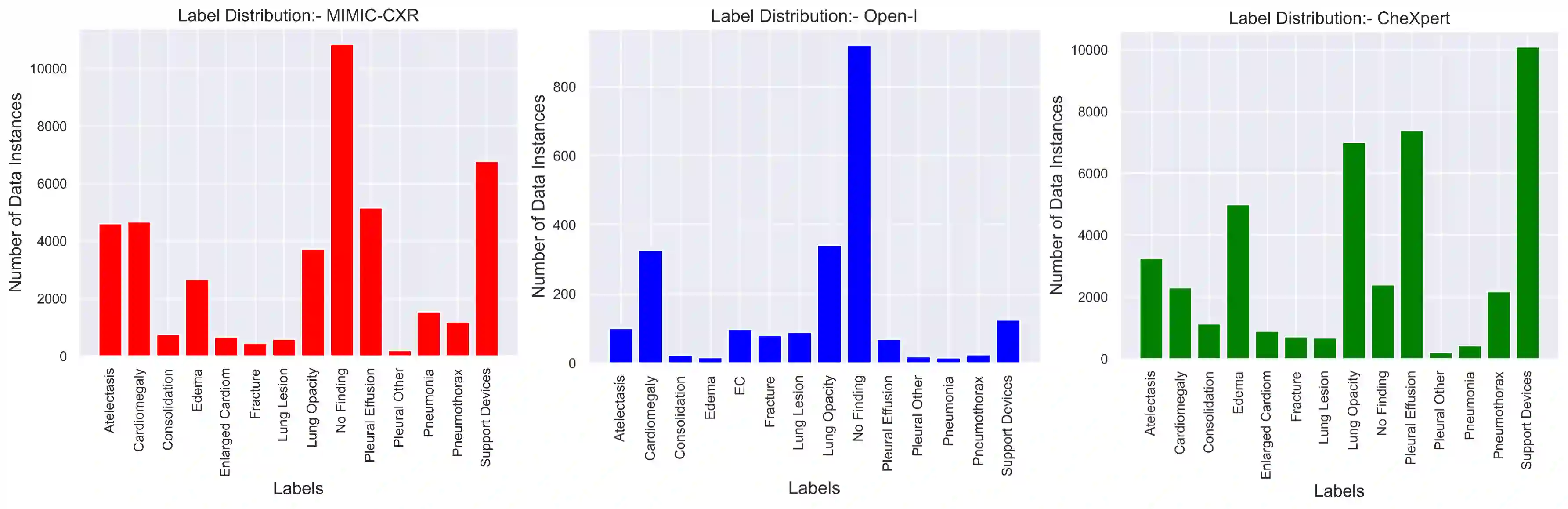
Multimodal AI has demonstrated superior performance over unimodal approaches by leveraging diverse data sources for more comprehensive analysis. However, applying this effectiveness in healthcare is challenging due to the limited availability of public datasets. Federated learning presents an exciting solution, allowing the use of extensive databases from hospitals and health centers without centralizing sensitive data, thus maintaining privacy and security. Yet, research in multimodal federated learning, particularly in scenarios with missing modalities a common issue in healthcare datasets remains scarce, highlighting a critical area for future exploration. Toward this, we propose a novel method for multimodal federated learning with missing modalities. Our contribution lies in a novel cross-modal data augmentation by retrieval, leveraging the small publicly available dataset to fill the missing modalities in the clients. Our method learns the parameters in a federated manner, ensuring privacy protection and improving performance in multiple challenging multimodal benchmarks in the medical domain, surpassing several competitive baselines. Code Available: https://github.com/bhattarailab/CAR-MFL
翻译:多模态人工智能通过利用多样化的数据源进行更全面的分析,已展现出优于单模态方法的性能。然而,在医疗健康领域应用这一优势具有挑战性,因为公开数据集的可用性有限。联邦学习提供了一种极具前景的解决方案,它允许利用来自医院和医疗中心的大量数据库,而无需集中敏感数据,从而保护了隐私与安全。然而,针对多模态联邦学习的研究,尤其是在处理医疗数据集中常见缺失模态场景下的研究,仍然非常匮乏,这突显了一个未来亟待探索的关键领域。为此,我们提出了一种用于处理缺失模态的新型多模态联邦学习方法。我们的核心贡献在于一种新颖的基于检索的跨模态数据增强技术,该方法利用少量公开可用的数据集来填补客户端缺失的模态。我们的方法以联邦方式学习参数,确保了隐私保护,并在医疗领域的多个具有挑战性的多模态基准测试中提升了性能,超越了若干具有竞争力的基线方法。代码已开源:https://github.com/bhattarailab/CAR-MFL