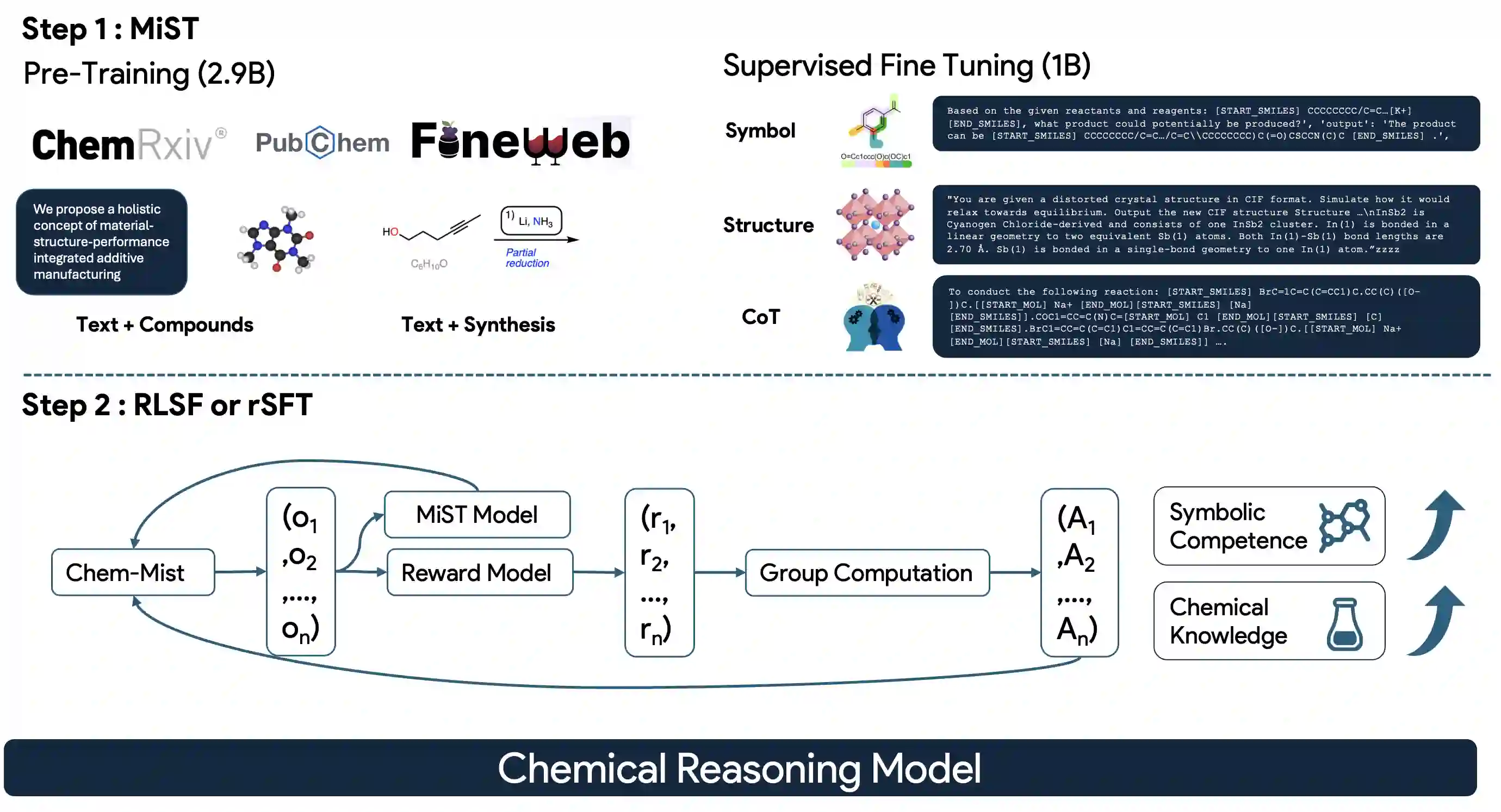
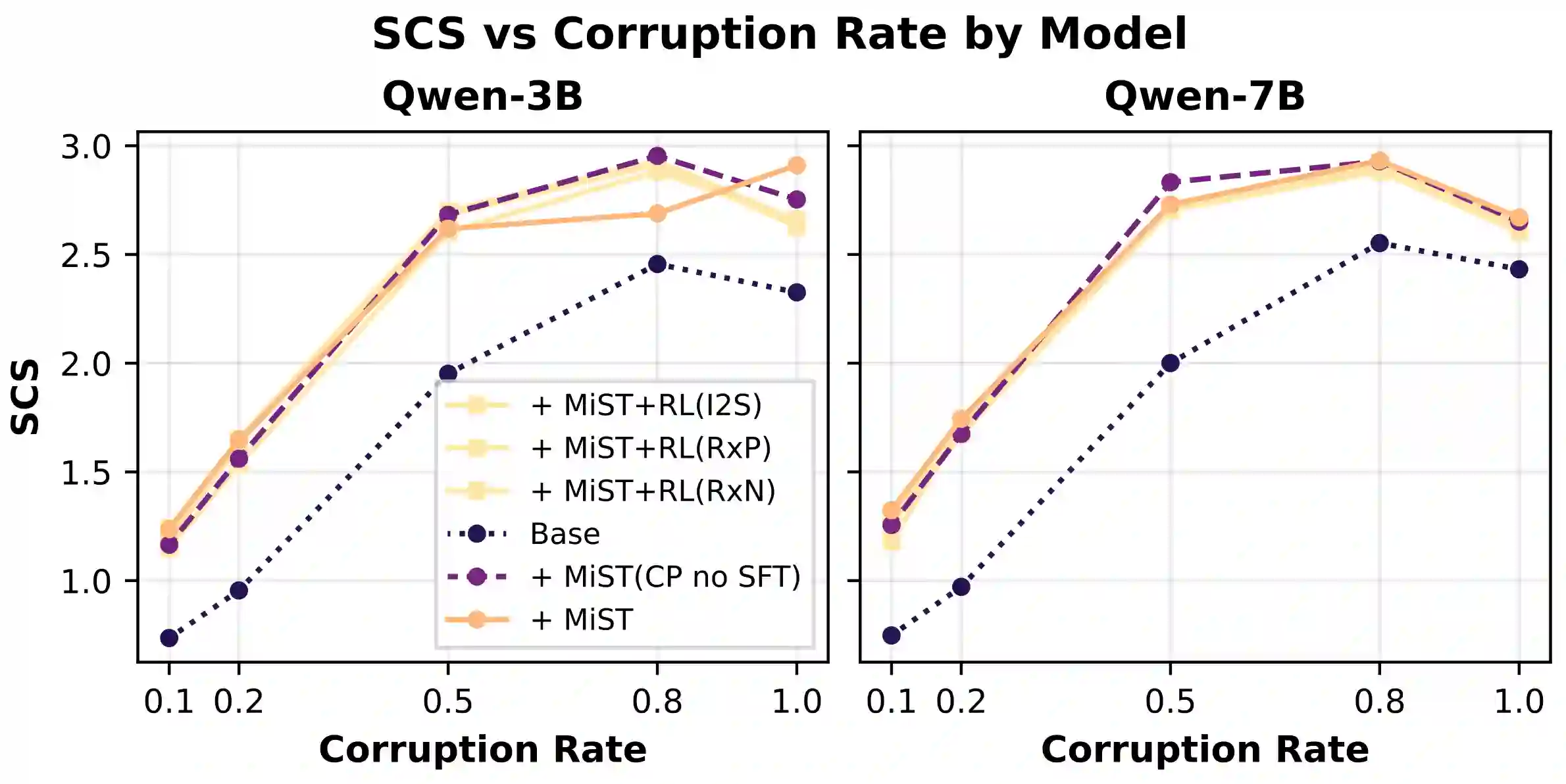
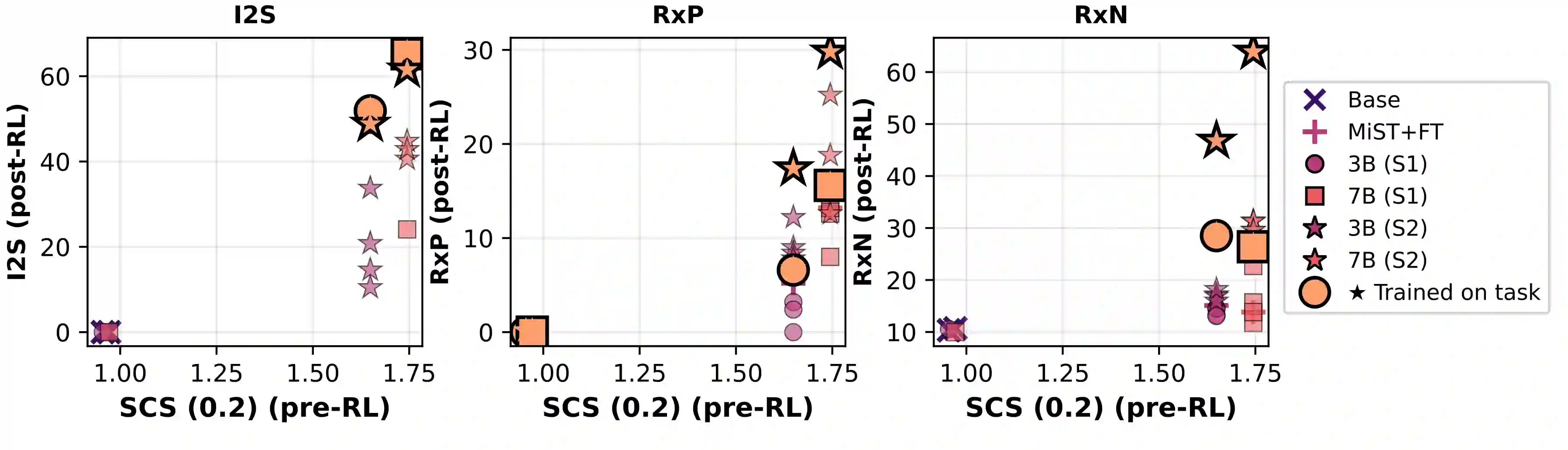
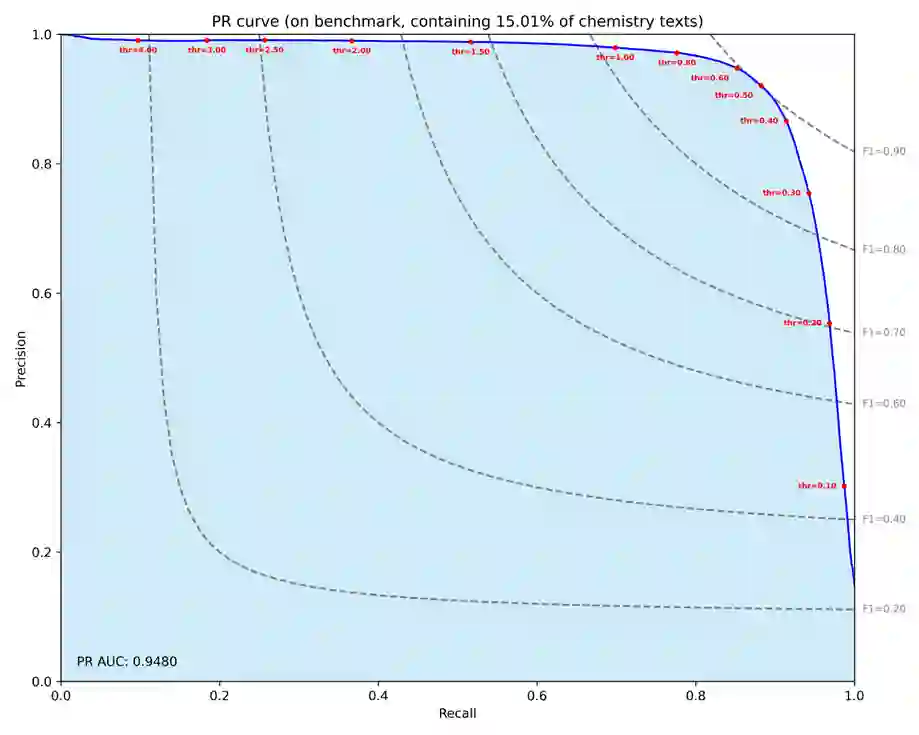
Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.
翻译:大型语言模型可通过基于规则的奖励进行在线微调来发展推理能力。然而,近期研究揭示了一个关键限制:仅当基础模型已对正确答案分配了不可忽略的概率时,强化学习才能成功——我们将此特性称为“潜在可解性”。本研究探讨了化学推理能力的涌现过程,以及这些先决条件对化学领域意味着什么。我们确定了基于强化学习的化学推理所需的两项必要条件:1)符号能力,以及2)潜在化学知识。我们提出了中期科学训练(MiST):一套满足这些条件的中期训练技术,包括采用SMILES/CIF感知预处理的数据混合、基于29亿词元的持续预训练,以及基于10亿词元的监督微调。这些步骤将30亿和70亿参数模型的潜在可解性分数提升至多1.8倍,并使强化学习在有机反应命名任务中的Top-1准确率从10.9%提升至63.9%,在无机材料生成任务中从40.6%提升至67.4%。在其他具有挑战性的化学任务中也观察到类似效果,同时生成可解释的推理轨迹。我们的研究结果为化学推理训练明确了先决条件,并凸显了中期训练在解锁推理能力方面的更广泛作用。